









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第21回目は、Microsoftが開発した実写アバターTTS、擬人化キャラの生成モデルなど、生成AI最新論文の概要5つをお届けします。
生成AI論文ピックアップ
Microsoft、テキストの内容を実写アバターに話させるツールを発表。リアルタイムに対話できるボットアバターも可能
Microsoftは、写実的なアバターを作成し、テキスト入力によってアバターに話させることができるツール「Azure AI Speech text-to-speech avatar」をパブリックプレビュー版として発表しました。このシステムを使用すると、リアルな外見を持つ実写アバターを作成し、この実写アバターにテキスト入力した言葉をさまざまな言語や声で話させることができます。
ただし、有害なディープフェイクや誤解を招くコンテンツの生成を防ぐために、カスタムアバターの利用は登録制で、特定の使用にのみ利用が制限されています。フォームからの申請が必要です。
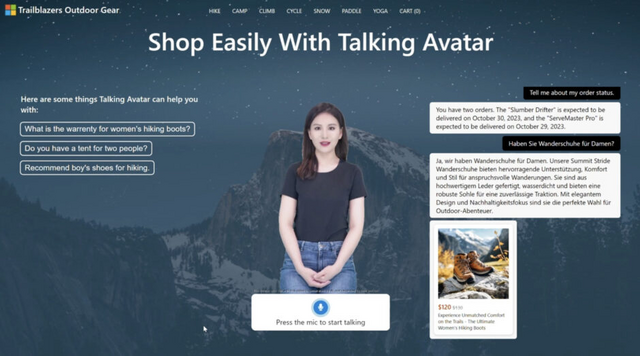
このシステムは、作成した実写アバターを使用してリアルタイムの対話型チャットボットを構築することもできます。例として、アウトドア用品のオンラインショップでバーチャル販売員として活動する実写アバターが紹介されています。
ユーザーは、バーチャル販売員に話しかけることができます。バーチャル販売員は商品情報や注文状況などのデータにアクセスし、Azure OpenAI Service GPT-3.5モデルを利用して顧客の質問に答えます。また、Azure OpenAI Serviceを通じて商品知識ベースの検索やデータベーストランザクションを実行し、在庫がある場合はリアルタイムでの商品の注文処理も可能です。
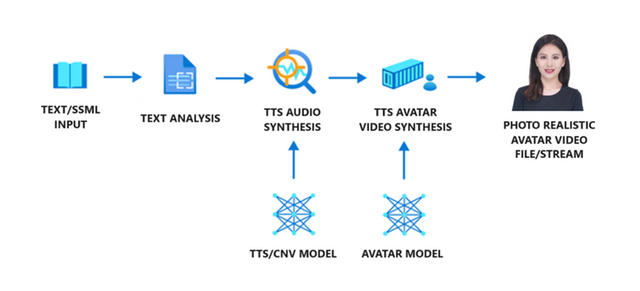
アバターコンテンツ生成のワークフローには3つの要素が含まれます。テキストアナライザー、TTS音声合成器、そしてTTSアバタービデオ合成器です。アバタービデオを生成するためには、まずテキストをテキストアナライザーに入力します。このアナライザーは入力されたテキストを音素のシーケンスとして出力します。次に、TTS音声合成器がテキストの音響特性(声のトーン、速さ、高さなど)を予測し、声を合成します。TTSアバタービデオ合成器では、音響特徴に基づいて、アバターの唇の動きを予測し生成します。

擬人化系キャラクターをテキスト指示で生成できるモデル「ChatAnything」、ByteDanceらが開発
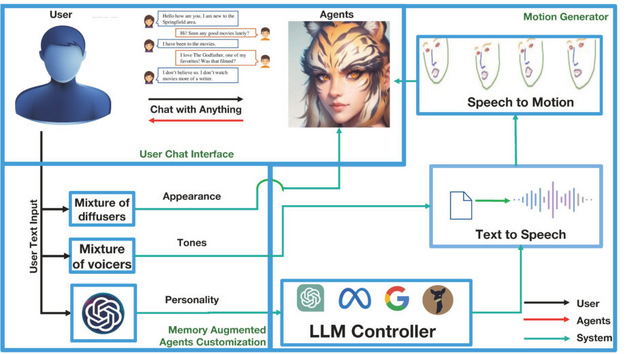
この研究では、テキストの説明のみを使用して人間らしい特徴(擬人化)の個性的なキャラクターを生成する「ChatAnything」を提案しています。このシステムは、大規模言語モデル(LLM)の能力を活用し、ユーザーが提供するテキストに基づいてキャラクターの見た目、性格、口調、表情や頭部の動きを作り出します。
これにより、ユーザーの好みや要求に合ったユニークなキャラクターを作り出すことができます。例えば、動物、果物、植物、料理、道具などの物体を擬人化したキャラクターや、架空のストーリーに登場するキャラクターの擬人化などです。
このプロセスの中で、特に重要なのが「Mixture of Voices」(MoV)と「Mixture of Diffusers」(MoD)という2つの概念です。MoVは、テキストから音声への変換(TTS)するアルゴリズムを使用し、さまざまな定義済みのトーン(話し方のスタイルや声の質など)から最も合致するものをユーザー提供のテキスト説明に基づいて自動的に選択します。MoDは、テキストから画像への生成技術と話す頭部モデルを組み合わせ、話すオブジェクトを生成します。
このシステムのもう一つの側面は、生成されたキャラクターの顔の品質評価方法です。研究チームは、顔の特徴を正確に検出し、スムーズなアニメーションを実現するための新しい評価データセットを提案しました。このデータセットに基づいて、生成されたキャラクターの顔のランドマーク検出率が57.0%から92.5%に大幅に向上したことが示されています。これにより、生成されたスピーチコンテンツに基づいた自動的な顔のアニメーションが可能になります。



ChatAnything: Facetime Chat with LLM-Enhanced Personas
Yilin Zhao, Xinbin Yuan, Shanghua Gao, Zhijie Lin, Qibin Hou, Jiashi Feng, Daquan Zhou
Project | Paper | GitHub
Meta、テキストから動画を生成するAI「Emu Video」を開発
この研究では、テキストからビデオを生成する新しいアプローチ「Emu Video」を紹介しています。Emu Videoは、テキストから画像を生成し、その画像を基にビデオを作成するという2段階のプロセスを採用しています。
この分割されたアプローチにより、Emu Videoは非常に効率的に高品質なビデオを生成することができます。具体的には、512×512ピクセルの解像度で4秒間、16フレーム/秒のビデオを生成することが可能です。
従来の直接的なText-to-Videoモデル(T2V)と異なり、推論時には、Emu Videoは明示的に画像を生成し、これによってテキストから画像モデルの視覚的な多様性、スタイル、品質を維持することができます。その結果、Emu Videoは、同じ量のトレーニングデータ、計算リソース、トレーニング可能なパラメータを考慮しても、直接的なT2Vを上回る性能を発揮します。
人間による評価では、EMU VIDEOが生成するビデオの品質は、品質とプロンプトへの忠実度の両方の面で他の全ての先行研究よりも高く評価されています。具体的には、Googleの「Imagen Video」に対して81%、NVIDIAの「PYOCO」に対して90%、Metaの「Make-A-Video」に対して96%の好評価を得ています。さらに、RunwayMLの「Gen2」やPika Labsなどの商用ソリューションよりも優れていると評価されています。



EMU VIDEO: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, Ishan Misra
Project | Paper | Demo
人の声、自然音、音楽、歌など多種多様な音声タイプを扱える言語モデル「Qwen-Audio」、アリババグループが開発
この研究では、人間と音声でやり取りするための新しいタイプのオーディオ言語モデル「Qwen-Audio」について提案しています。今までのオーディオモデルは、限られた種類の音声やタスクにしか対応できなかったため、この分野では進歩が遅れていました。
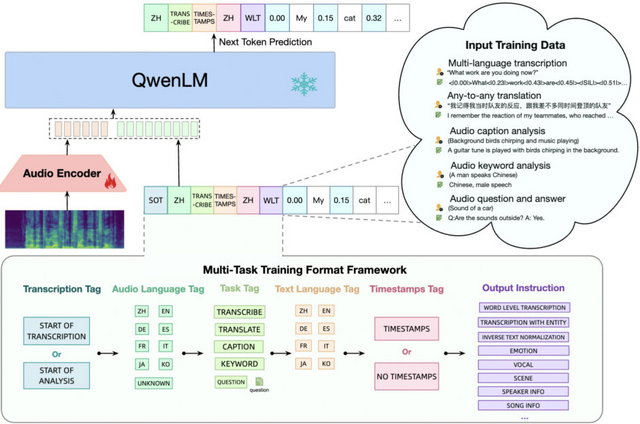
Qwen-Audioはこの問題を解決するために作られ、30種類以上の異なるタスクや、人の話し声、自然の音、音楽、歌などの様々なオーディオタイプに対応できるようになっています。
ただ、異なるタスクやデータセットを一緒に学習させると、それぞれのデータセットのテキストラベルが違うために問題が起こることがあります。Qwen-Audioは、この問題を解決するために、特定のタグを使って複数のタスクを効果的に学習できるように設計されています。その結果、Qwen-Audioは、特定のタスクに特化した微調整をすることなく、様々なタスクで優れた成果を達成しています。
さらに、Qwen-Audioの技術を基にして、さまざまな音声やテキスト入力からの情報を扱い、会話形式のやり取りや、音声を中心とした様々なシナリオに対応できる「Qwen-Audio-Chat」というシステムも開発しました。これにより、より広範囲な音声関連のタスクに対応できるようになりました。
広範囲にわたる評価により、Qwen-Audioはタスク固有の微調整なしで、さまざまなタスクにおいて既存のマルチタスクトレーニングモデルを上回ることが示されました。特に、Aishell1、ClothoAQA、VocalSoundのテストセットで最先端の成果を達成しました。


Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, Jingren Zhou
Paper | GitHub
表情や服のひらひらも詳細に再現し、リアルタイムで実写3Dアバターの動きを生成するモデル「D3GA」。Metaらが開発
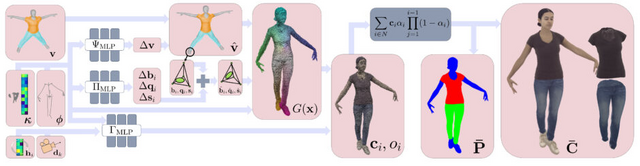
この研究は、写実的な3Dヒューマンアバターとその動きをリアルタイムで生成する新しい技術「D3GA」についてのものです。従来の「Neural Radiance Field」(NeRF)ベースの方法は高品質なレンダリングを実現しますが、リアルタイム処理には適していないという問題がありました。
この技術では、複数の視点から撮影した人間のビデオを使用し、3D Gaussian Splatting(3DGS)を利用して人間のアバターを表現します。体、顔、衣服など異なる部位を個別にモデル化し、それらを組み合わせることで、一貫性のあるアバターを生成します。
これにより、高品質でリアルタイムのフレームレートにて人間の姿を再現することが可能になります。また、顔の表情やスカートのようなひらひらする衣服も精密に再現されます。
D3GAの有効性を検証するために、様々な体型、衣服、動作を持つ9人の被験者を対象に実験を行いました。その結果、従来の方法と比較して、より高品質な結果が得られることが示されました。
この技術はリアルタイムでの描画が可能であるため、リアルタイムで動作するアバターを必要とする多くのアプリケーション、特にテレプレゼンスやバーチャルリアリティにおいて適しています。


Drivable 3D Gaussian Avatars
Wojciech Zielonka, Timur Bagautdinov, Shunsuke Saito, Michael Zollhöfer, Justus Thies, Javier Romero
Project | Paper




