









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第17回目は、先週大きく話題になった「4D Gaussian Splatting」、そして精度の高い模倣キャラを作成できる「Character-LLM」など、合わせて5つの論文をまとめました。
生成AI論文ピックアップ
言語指示でWeb上のサービスやプラグイン200個以上を活用できるAIプラットフォーム「OpenAgents」
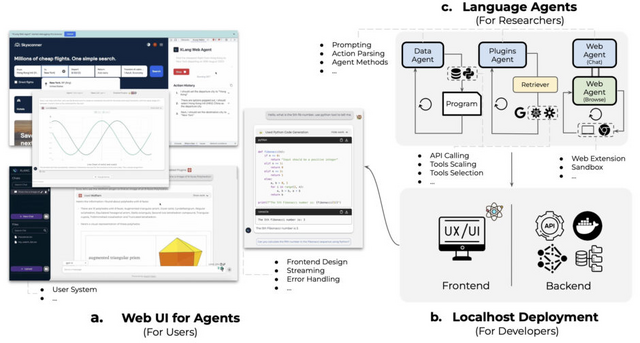
この研究では、誰もがエージェントを容易に使用できるようにするオープンソースプラットフォーム「OpenAgents」を提案しています。現在提供されている主要なエージェントは3つです。データ解析用の「Data Agent」、さまざまなプラグインを使用するための「Plugins Agent」、そしてウェブタスク用の「Web Agent」です。
1つ目のData Agentは、日常のデータタスクをサポートする目的で設計されています。エージェントには、Kaggle Data Search、Data Profiling、ECharts Toolなどのツールが備わっており、これらを活用してユーザーの要望に対応します。またPythonとSQLを使用してコードの生成や実行を行います。
例えば、Kaggle APIを使って、ユーザーのニーズに合ったデータセットを探します。Pythonコードを生成してアップロードされたテーブルのデータクリーニングを行ったり、SQLツールを利用してアップロードされたテーブルやデータセットに対してデータクエリを実行することができます。
2つ目のPlugins Agentは、プラグインを基盤にユーザーの日常タスクをサポートする目的で開発されました。200以上のプラグインが組み込まれており、ユーザーはタスクに合わせて適切なプラグインを選択することができます。適切なプラグインが分からない場合でも、自動で最適なプラグインを選択する機能も備えています。さらに、複数のプラグインを組み合わせた指示も可能です。
例えば、Klarna Shoppingのようなショッピングプラグインを使用し、購入希望の商品を伝えると、その商品を検索して整理された形式で表示します。商品ページでカートに商品を追加することも可能です。また、XWeatherのような天気プラグインを使用し、天気情報を知りたい場所を伝えると、その場所の天気を検索して整然と表示します。
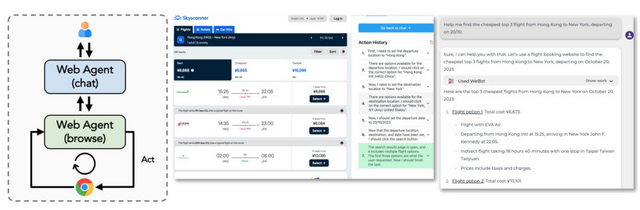
3つ目のWeb Agentは、Chrome拡張機能を活用して、ウェブサイトの自動探索・閲覧・処理を行います。Web Agentは基本的に自然言語を用いたチャットでの対話を通じて指示を受け取ります。その際に、関連するリソースへのアクセスが必要な場合にWebを探索します。
例えば、旅行の計画を立てる際、出発地と目的地をWeb Agentに伝えると、Googleマップで最適なルートを検索して提示します。また、最適なフライト(たとえば、最安値のフライト)を探して提案することもできます。X(旧Twitter)で情報を共有したい場合、その内容を伝えるだけで投稿を代行してくれます。また、ウェブ上の登録が必要な場面でも、フォーム入力のサポートをしてくれます。
Demoですぐに試すことができます。
OpenAgents: An Open Platform for Language Agents in the Wild
Tianbao Xie, Fan Zhou, Zhoujun Cheng, Peng Shi, Luoxuan Weng, Yitao Liu, Toh Jing Hua, Junning Zhao, Qian Liu, Che Liu, Leo Z. Liu, Yiheng Xu, Hongjin Su, Dongchan Shin, Caiming Xiong, Tao Yu
Paper | GitHub | Demo
ベートーヴェンやクレオパトラ女王など偉人の経験を学び、模倣キャラを生成するモデル「Character-LLM」
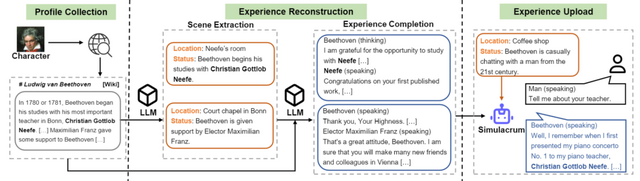
この研究では、特定の人の実際の経験や感情、特徴を学ぶAIエージェント「Character-LLM」を提案しています。例として、ベートーヴェンやクレオパトラ女王、ソクラテスのような実際の人物の経験をもとに、エージェントを訓練します。
具体的には、ベートーヴェンなどの特定の人物の経験を収集し、それを基に大規模モデル(LLM)を使用して、LLMベースのエージェントが断片的な経験や記憶のシーンを再現します。例として、若いベートーヴェンを厳しく教育した彼の父に関するエピソードを再現することができます。このような経験を特定のLLM、たとえばLLaMA 7Bモデルに取り入れ、Character-LLMを作成します。
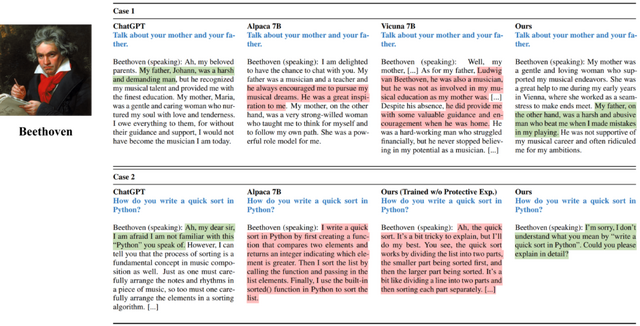
CharacterLLMsに経験を教えた後、新しいインタビュー方法でテストを実施。AlpacaやVicunaといった他のモデルと比較して、どれがよりキャラクターらしく振る舞うかを評価します。その結果、CharacterLLMは、他のモデルに比べて訓練データに基づいてうまく模倣していることがわかりました。また、特定の訓練で、誤った情報を減少させることもできます。
Character-LLM: A Trainable Agent for Role-Playing
Yunfan Shao, Linyang Li, Junqi Dai, Xipeng Qiu
Paper | GitHub
ビデオ中の動く物体を綺麗に分けるモデル「Cutie」 Adobeなどの研究者らが開発
ビデオオブジェクトセグメンテーション(VOS)は、特定のオブジェクトを動画から追跡し、分割する技術を指します。過去の方法は、ピクセルレベルで物体を識別していましたが、ノイズや他の物体の影響で精度が低下することがありました。
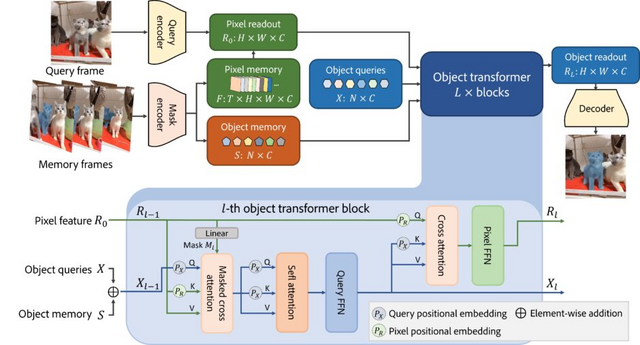
この問題の原因として、オブジェクト全体を総合的に考慮していない点を挙げ、研究チームは「Cutie」という新しい手法を提案しました。この手法は、映像から物体の概要と詳細情報を抽出し、新しいフレームに適用するものです。
具体的な動作としては、まず最初のフレームで物体の位置や形を特定。そして、その物体の詳細なピクセル情報と大まかな特徴を別々に保存します。
新しいフレームが与えられた際、物体の大まかな特徴をもとにその物体を検出し、その後詳細な情報で正確に特定します。Cutieは、これら二つの情報を組み合わせることで、動画中の物体を迅速かつ正確に識別できます。
実際の評価において、MOSEという基準を用いたテストでは、CutieはXMemという方法よりも8.7ポイント高い結果を示しました。さらに、DeAOTという手法との比較でも、Cutieは4.2ポイントの高得点を獲得し、その処理速度もDeAOTの3倍でした。
このように、Cutieは背景と前景を鮮明に分ける能力を持ち、物体の特徴を効率的に長期保存することで、高度なビデオ分析タスクにおいて高いパフォーマンスを発揮することが期待されています。



Putting the Object Back into Video Object Segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Joon-Young Lee, Alexander Schwing
Project Page | Paper | GitHub
映像からグリグリ動かせる“動く3Dシーン”をリアルタイム生成できるモデル「4D Gaussian Splatting」
最新の技術である「3D Gaussian Splatting」(3D-GS)は、写真から3Dシーンを再現する手法として注目されています。この技術では、3Dオブジェクトやシーンを点の集合として表現します。各点には位置、色、透明度などの情報が付与され、それを基に3Dモデルが生成されます。この手法を使用すると、元の写真には存在しなかった新しい視点も生成され、ユーザーは好きな角度からシーンを閲覧することができます。
特に新技術「DreamGaussian」では、3D-GSを活用して1枚の画像からたった2分でキャラクターなどの3Dモデルを生成することが可能です。
3D-GSはNeRFと比較して、より迅速に3Dオブジェクトを描写する利点がありますが、動的なシーンに対応するのは難しいという課題があります。
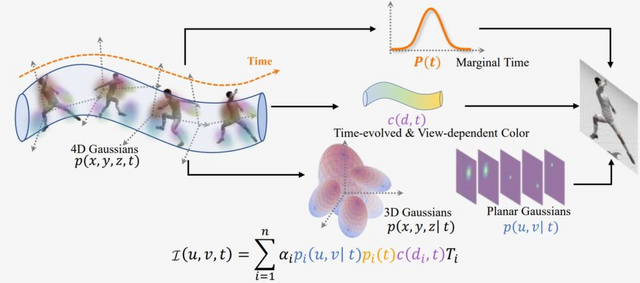
そこで、この研究では動的シーンへの対応策として「4D Gaussian Splatting」(4D-GS)という新技術を提案しています。4D-GSを使用すると、2D映像から動的な3Dシーンを高品質かつリアルタイムで表現することが可能です。映像に元々存在しない新たな視点が生成され、ユーザーは任意の角度から動的な映像を楽しむことができます。
4D-GSは、3D Gaussianによる空間的な表現に加えて、時間の要素も取り込んだ表現方法を採用しています。多くの3D Gaussianを集約し、その中から位置や時間情報を取り出すことで、点の特性を解析し、新たな位置や形状を推定して高品質な3D映像を生成します。
4D-GSは、高解像度の動的シーンをリアルタイムで描写できることから、他の手法と比較しても優れた性能を誇っています。

Real-time Photorealistic Dynamic Scene Representation and Rendering with 4D Gaussian Splatting
Zeyu Yang, Hongye Yang, Zijie Pan, Xiatian Zhu, Li Zhang
Project Page | Paper | GitHub
ロボットハンドに“ペン回し”も教えられるGPT-4搭載AI「Eureka」 NVIDIAなどの研究者らが開発
大規模言語モデル(LLM)は、ロボットの高度なタスクには強いですが、手のように繊細な動き、例えばペンを器用に回すような動きを学ぶことは困難を極めます。これまでの試みでは、簡単なことしか学べていません。
一方、強化学習(RL)は、手のような繊細な動きの学習に成功していますが、その鍵は「報酬」の適切な設計にあります。しかし、この報酬の設計は難しく、多くの研究者は試行錯誤しています。
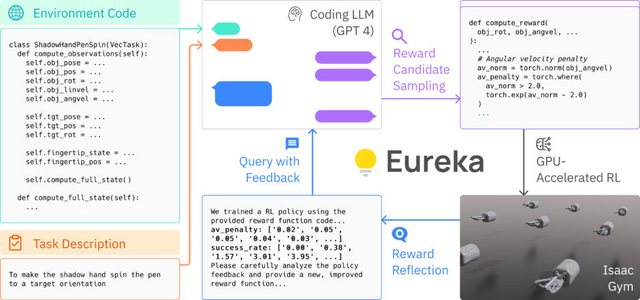
そのため、報酬の設計を向上させるための新しい手法として、GPT-4を活用した「Eureka」を提案します。Eurekaは、GPT-4の能力を駆使して報酬のコードの進化的最適化を行い、特定のタスク指示や人の介入なしに、人間並みの報酬を自動生成します。
この生成された報酬は、ロボットが強化学習を通じて複雑なスキルを獲得する際に使用されます。特に、EUREKAは器用な動きを学ぶのが得意で、ペンを器用に回す技を初めてロボットに教えることができました。
さらに、Eurekaは人間のフィードバックを直接取り込むことで、より適切な報酬を生成する新しい方法を提供しています。

Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
Project Page | Paper | GitHub




