









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第31回目は、生成AI最新論文の概要6つを紹介します。
生成AI論文ピックアップ
あらゆる画像や動画の奥行きを高品質に推定する手法「Depth Anything」、TikTokなどが開発
あらゆる画像に対して高品質な深度情報を提供できる単眼深度推定(Monocular Depth Estimation、MDE)のための基盤モデル「Depth Anything」が登場しました。
従来の方法とは異なり、約150万枚のラベル付き画像とともに、約6200万枚の大規模なラベルなし画像を利用しています。ラベルなし画像を有効に活用するために、研究チームは自動的に深度注釈を生成するデータエンジンを設計しました。これにより、多様なシナリオに対応可能な豊富なデータセットを構築し、モデルの一般化能力を高めることを目指しています。
加えて、意味的セグメンテーションタスクの補助を取り入れることで、MDEモデルの性能向上を目指します。このアプローチにより、MDEモデルは高レベルのシーン理解能力を獲得し、中間レベルと高レベルの知覚タスクに適したエンコーダーとして機能します。
実験の結果、Depth Anythingモデルは印象的な一般化能力を示しました。特に、異なるタイプのデータセットに対しても高い精度を達成し、多様なシナリオでの有効性を証明しました。さらに、NYUv2およびKITTIデータセットの深度情報を用いて行われた微調整を通じて、新しい最先端の成果を達成しました。


Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
Project | Paper | GitHub | Demo
大規模言語モデルを2倍高速にする手法「Medusa」
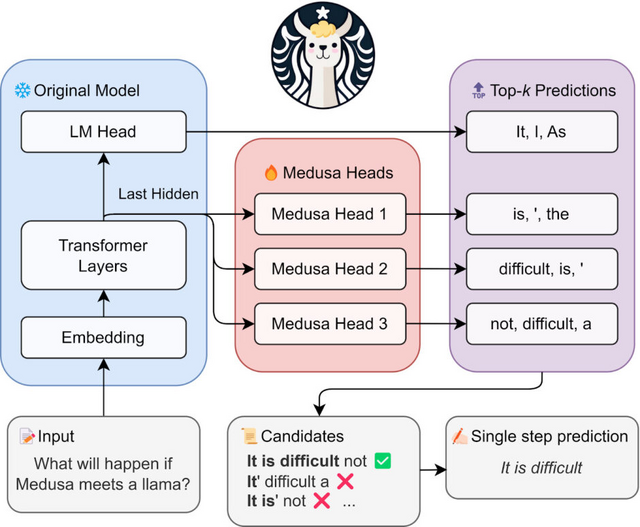
「Medusa」は大規模言語モデル(LLM)の推論プロセスを高速化するための新しい手法です。従来の方法と異なり、Medusaは元のモデルの最後の隠れ層の上に複数の追加デコーディングヘッドを導入し、元のモデルの機能を拡張します。
これらのヘッドは、それぞれ異なる位置で複数のトークンを同時に予測する役割を持ち、結果として各生成段階で複数のトークンを一度に処理できるため、全体の処理速度が向上します。
Medusaヘッドは元のモデルと共にトレーニングされます。トレーニング中に元のモデルを固定し、新しいヘッドだけをファインチューニングすることで、元のモデルの学習済み表現を最大限に活用します。
また、Medusaは生成した複数の候補を並行して処理するためにツリー構造を用いたアテンションメカニズムを採用します。このメカニズムにより、複数の候補を同時に評価し、最適な続きを効率的に選択できます。
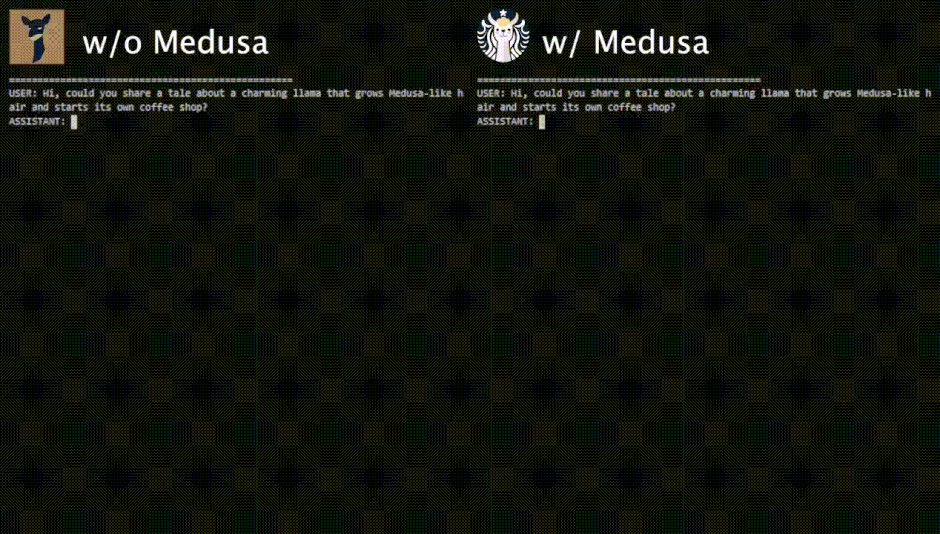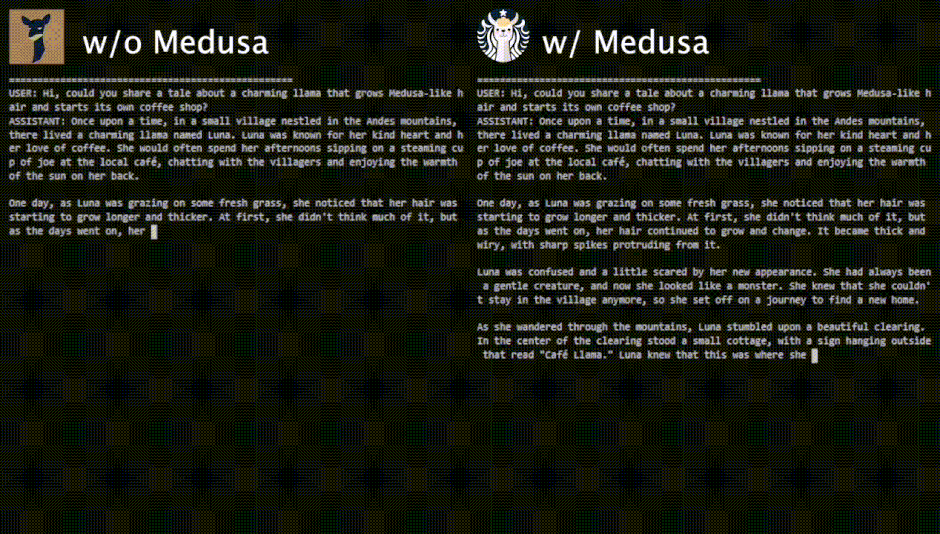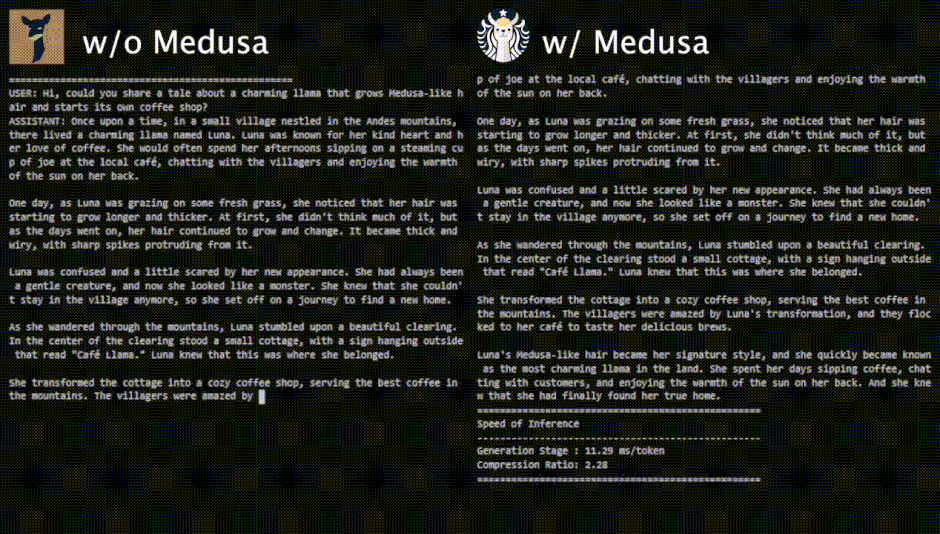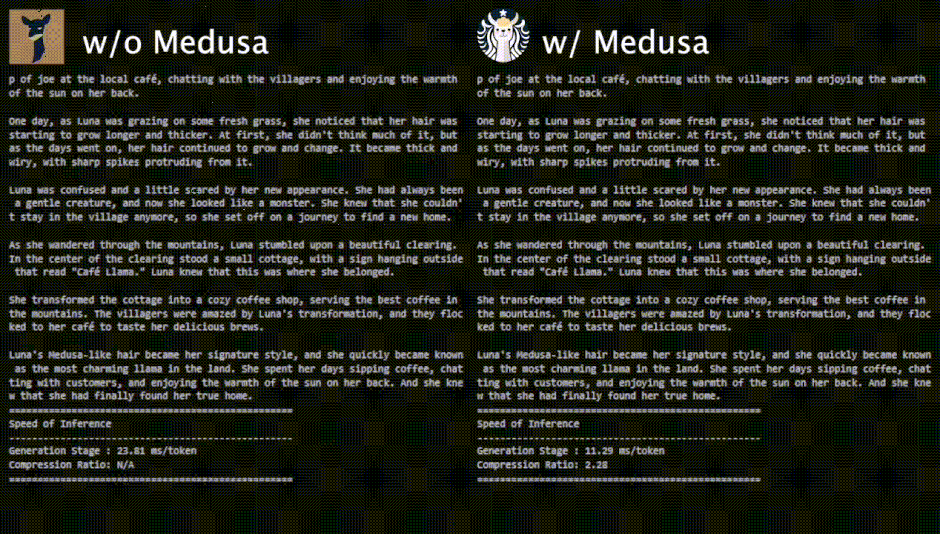
評価実験では、Vicunaモデル(7B、13B、33Bのパラメータ数を持つチャット用に特化したLlamaモデル)でMedusaをテストしました。結果として、Medusaは様々なユースケースにおいて、一貫して約2倍の速度向上を達成しました。
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, Tri Dao
Paper | GitHub | Blog
“複雑な”テキストプロンプトでも正確な画像を生成するフレームワーク「RPG」
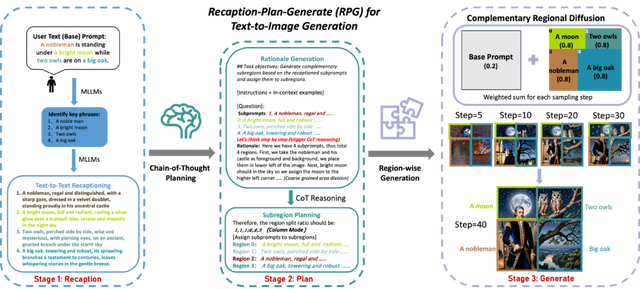
既存のテキストから画像を生成するモデルは、複数のオブジェクトや属性、関係性を含む複雑なテキストプロンプトを正確に再現する際には課題があります。これに対し、研究チームは「Recaption, Plan and Generate」(RPG)という新しいフレームワークを開発しました。
このフレームワークは、マルチモーダル大規模言語モデル(MLLM)の高度な思考プロセスを利用して、テキストから画像の拡散モデルの組成性を向上させています。具体的には、まず与えられたテキストプロンプトをMLLMを使用して、より具体的で詳細なサブプロンプトに分解します。この再キャプションのステップによって、画像に表現されるべき各要素が明確になります。
次に、MLLMを用いて画像内でこれらの要素がどのように配置されるべきかの計画を立てます。このプランニングステップでは、画像の異なる領域ごとに具体的な指示が生成され、画像全体の構成が決定されます。最後に、生成ステップでは、これらの指示に基づいて各領域を個別に生成し、最終的に全体の画像を形成します。
RPG手法の利点は、複雑なテキストプロンプトを効果的に扱い、細部まで精密な画像を生成できる点です。また、この方法はトレーニングを必要としません。
この新しいアプローチは、DALL-E 3やSDXLといった最先端のテキストから画像への拡散モデルと比較して、マルチカテゴリーオブジェクトの合成やテキストと画像の意味的整合性で優れた性能を示しています。また、RPGフレームワークは、さまざまなMLLMアーキテクチャ(例:MiniGPT-4)や拡散バックボーン(例:ControlNet、Canny Edge、Depth)との広範な互換性を持っています。





Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui
Paper | GitHub
Google、テキストや画像から自然でスムーズな動画を生成するAI「Lumiere」発表 全フレームを一度に処理
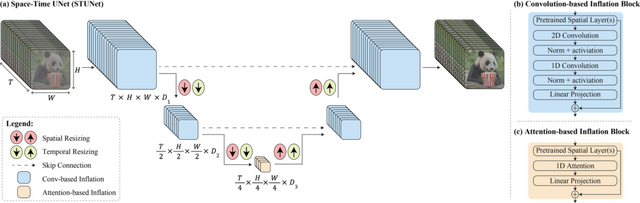
Google Researchなどによって開発された「Lumiere」は、テキストや画像を入力にして高品質なビデオを生成できることが特徴です。従来のビデオ生成モデルは、まずキーフレームを作り、その後これらのキーフレーム間のフレームを埋めていきます。このプロセスでは、ビデオの全体的な流れや動きを一貫して捉えることが難しいことがあります。
Lumiereは全フレームを一度に処理することで、時間的一貫性を持ちながらリアルな動きを生成することができます。このモデルの核となるのは「Space-Time UNetアーキテクチャ」という技術です。これにより、空間的(画像内のピクセルの配置や関係など)および時間的(ビデオ内でのオブジェクトの動き、シーンの変化、フレーム間の関係など)にビデオを効率的に処理し、ビデオ全体の時間的な流れを一度に生成できます。結果として、ビデオはより自然で一貫性のあるスムーズな動きを実現します。
Lumiereの応用範囲は広く、画像からビデオへの変換、ビデオの部分的な修正や編集、異なるスタイルのビデオ生成などが可能です。例えば、一枚の画像からその画像を動かすビデオを作ったり、ビデオ内の特定の部分を修正したり、新しい要素を追加したりすることができます。ビデオに特定の芸術的なテーマや雰囲気を加えることも可能です。

Lumiere: A Space-Time Diffusion Model for Video Generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Yuanzhen Li, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, Inbar Mosseri
Project | Paper
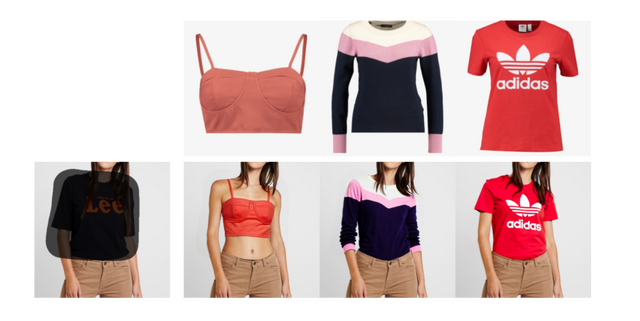
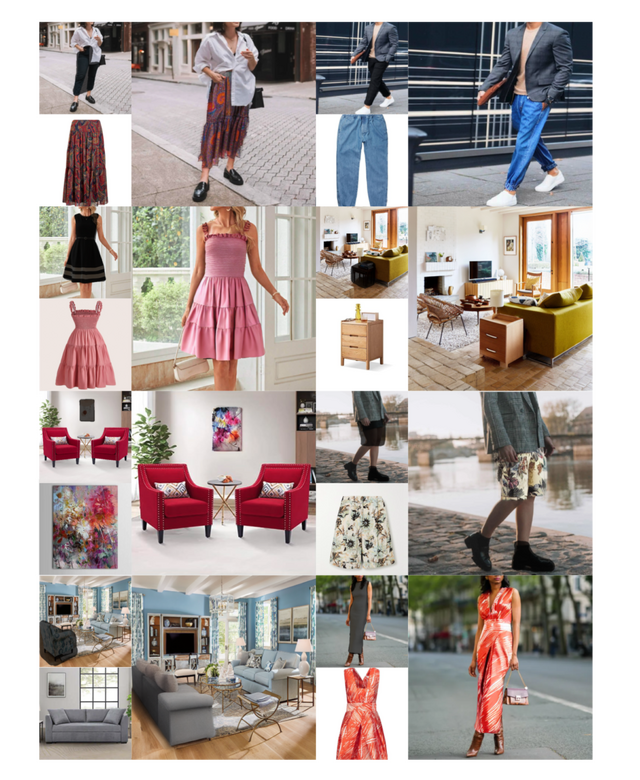
Amazon、服のバーチャル試着や家具のバーチャル配置ができるモデル「Diffuse to Choose」を開発。独自の大規模商品データで学習
オンラインショッピングの需要が増えるにつれて、消費者が自分の環境内で衣服、靴、家具、装飾品などのあらゆる製品をバーチャル的に試着できる技術が求められています。「Virtual Try-All」(Vit-All)と呼ばれ、ユーザーの写真に製品の画像を自然に統合するために、高度な意味的画像合成ツールとしての機能に依存しています。
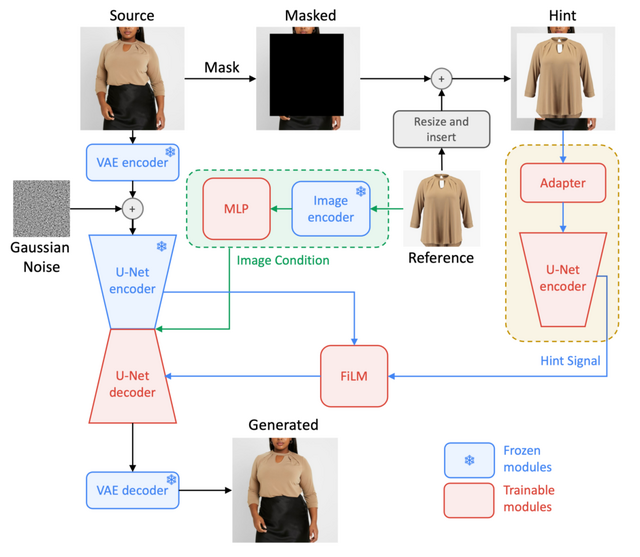
Amazonの研究チームは、Vit-Allアプリケーション用に「Diffuse to Choose」(DTC)という、新しい拡散インペインティング(拡散による画像補完)技術を開発しました。消費者がオンラインカタログから選んだ商品の画像を自分の写真に挿入し、実際に使用しているかのように見せることができます。
DTCは特に、商品の細かいディテールを保ちながら、写真の環境と調和させることに優れています。この技術は、2つのU-Netエンコーダーを使用して、参照画像の詳細な情報をメインのデコーダーに統合します。このプロセスにより、色やテクスチャなどの基本的な特徴も正確に合わせることができます。
さらに、DTCはリアルタイムで動作するため、数十億の商品と何百万人ものユーザーに対応できるスピードと効率を持っています。Amazonのチームは、様々なカテゴリーの製品(衣類、家具など)を含む1.2Mのソース参照ペアを含む独自のトレーニングデータセットでDTCを訓練しました。その結果、DTCは他の類似技術よりも優れた性能を示し、特に細部のディテールを保持する能力において顕著な成果を達成しました。


Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All
Mehmet Saygin Seyfioglu, Karim Bouyarmane, Suren Kumar, Amir Tavanaei, Ismail B. Tutar
Project | Paper
テキスト指示をもとに画像内のオブジェクトを検出して分割するモデル「Grounded SAM」
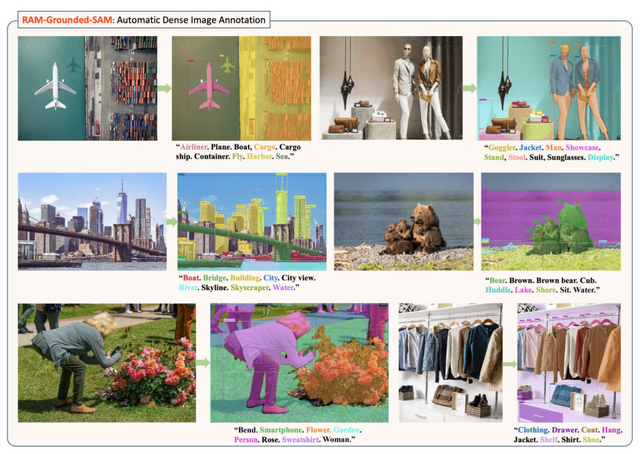
「Grounded SAM」は、任意のテキストプロンプトに基づいて画像内のオブジェクトを特定するモデル「Grounding DINO」と、プロンプトに基づいて画像内の任意のオブジェクトをセグメント(分割)するモデル「SAM」(Segment-Anything Model)を組み合わせたモデルです。任意のテキスト入力に基づいて画像内の任意の領域を検出・分割する能力を持っています。
Grounded SAMは、他のモデルと統合することで、より複雑な視覚タスクを達成することが可能です。例えば、Recognize Anything(RAM)と組み合わせると、RAM-Grounded-SAMモデルはテキスト入力なしで画像内の物やオブジェクトを自動的に識別し、分割することができ、自動画像アノテーションタスクを容易にします。同様の自動画像アノテーション機能は、BLIPとの統合を通じても達成できます。
さらに、Stable Diffusionの機能を備えたGrounded SAMは、Grounded-SAM-SDモデルとして、高精度な画像編集タスクを実行することができます。また、「OSX」(One-Stage 3D Whole-Body Mesh Recovery)と統合することにより、画像内の特定の人物に対する詳細な3D人体ポーズと形状の解析が可能になります。
Grounded SAMは、ベンチマークで優れたパフォーマンスを示しており、SegInW(Segmentation in the Wild)ゼロショットベンチマークでは、Grounding DINO-BaseとSAM-Hugeモデルの組み合わせで顕著な性能向上を達成しています。






Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, Lei Zhang
Paper | GitHub




