





Stable Diffusionを提供するStability AIは、高品質なマルチビュー推定と3Dメッシュの生成を行う新たなモデル「Stable Video 3D」(SV3D)を発表しました。
ただし現時点で公開されているのは、画像から多角度の姿を推定するマルチビュー推定部分のみです。
現状ではまだその全貌がよく知られていないので、ローカルで試せるようになる前に、その概要と技術的な構成についてまとめました。ゲーム開発者の立場からの展望も考えます。

SV3Dとは?

3D生成の大きな流れは、動画の生成に似た状況にあります。ひとつはテキストによる指示から3Dオブジェクトを生成するもの。もうひとつは画像を元にそれを3D化するものです。
SV3Dは後者で、入力した画像からその被写体の複数の角度の姿を推定、つまり画像からのマルチビュー推定を実行します。そして推定した姿を元に3Dデータを生成する仕組みです。
SV3Dのライセンスは、ここ最近のStability AIのプロダクト同様に、研究目的等非商用なら無償・商用利用にはStablity AIのMemberships加入が必要です。
マルチビュー推定

SV3Dは、同じくStability AIが公開している動画生成モデルの「Stable Video Diffusion」(SVD)をベースに開発されました。
SVDのモデルをカメラ姿勢を条件としてファインチューニングしており、動画生成で重要な時間方向の一貫性を、空間的な一貫性に応用しています。
SVDの発表時点ですでに、そのマルチビュー推定能力の高さについて言及しており、SV3Dはそれを具体化した技術です。
基本的な原理は画像生成と同じで、大量の画像や動画を学習して潜在空間を構築しますが、カメラ位置も考慮します。
入力画像とカメラの位置を与えて潜在空間を探索し、その結果を画像に出力することで、入力画像の異なる角度の姿を推定できるのです。またベースが動画用のSVDであることで、画像生成とは異なり高い一貫性を担保しています。
学習に用いたデータセットは、Objaverseという3Dモデル集を用いています。ただしObjaverseは商用利用禁止のモデルなどを多数含むため、ここからCC-BYライセンスのものだけを抜粋しています。これはやはりStability AIが共同開発したTripoSRでも同様の方針でした。
現在公開されているモデルには「SV3D_u」と「SV3D_p」の2種類あります。SV3D_uは画像を1枚入力すると、アナログレコードプレーヤーのターンテーブルに乗せて回転させるような、いわゆるターンテーブル動画を生成します。SV3D_pは推定するカメラの軌道を任意に指定可能です。
uよりpの方がより正確な3D化に有利な角度からの姿を推定できますが、角度が任意の分、破綻するケースも多いようです。
3Dメッシュの生成
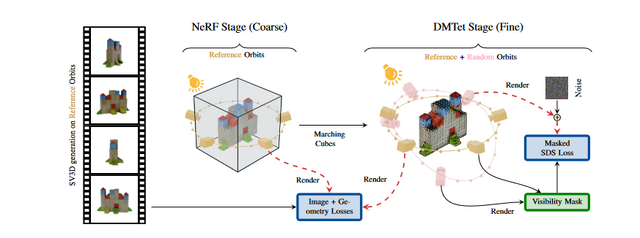
▲SV3Dの技術文書(PDF) より
現時点でまだ公開されていない3Dメッシュの生成ですが、技術文書に大まかな説明が掲載されています。少し専門用語が多いですが、流れと特徴を確認しましょう。
NeRFによる立体化
まず推定されたマルチビューを元に「Instant-NGP NeRF」の学習を行います。NeRFは多角度の画像から3D表現を算出する技術で、写真からその場の空間的な記録を表現する場合などに用いられています。Instant-NGP NeRFは学習に長時間を要すNeRFを、品質を維持しつつ高速化したものです。
DMTetによる細部の表現
NeRFのみでは細部が欠落しやすいため、他に「DMTet」技術を使ってそれを補っています。DMTetは高解像度のメッシュ生成を効率よく行えるもので、NeRFで行った粗い推定を補ってより精細な表現を可能にします。
球面ガウシアンによる照明の除去
メッシュ生成と合わせて表面の色となるテクスチャも生成します。その際、「球面ガウシアン」とランバート反射の仮定を用いて被写体の照明モデル、つまり光にどう照らされているかを推定し、その仮定した照明の影響の除去もしています。
なぜこんなことをするかというと、元にする画像はなんらかの照明が当たっているのが通常で、生成されたモデルを利用する際、元画像が受けていた照明の影響まで描かれては不便だからです。
たとえば強いハイライトが出ている画像をそのまま3D化して、ハイライトまで描かれてしまうと、暗いシーンではかなり不自然に見えます。それを除去してやることで、ゲームやXRで任意のシーンに表示しても違和感のない3Dオブジェクトとなります。
マスク付きSDS損失による品質の向上
こうしたメッシュやテクスチャの生成とともに、「マスク付きSDS損失」を使って元画像と生成結果の類似度を測り、結果の補正も施します。
原理はややこしいですが、元となるマルチビュー画像から、見えている部分は正確さを保ち、見えていない部分も適切に元画像の表現を取り込むことで精度を高める工夫です。
このように、SV3Dのメッシュ生成は先進的で非常に魅力的ですが、残念ながらまだ公開されていません。単にリソースの問題なのか、あるいはこの生成そのものをサービスとして提供するためかなど考えられますが、そうした事情も公表されていません。
とはいえ技術文書は公開されているので、CSMやTripoなど有料サービスや、他のオープンな実装に取り込まれていく余地はありそうです。
ローカルでの動作
マルチビュー推定部分だけでもローカル動作が可能か試しましたが、VRAMが足りずだめでした。試した環境はVRAM16GBのRTX 4060 Tiで、この規模でも動作するよう最適化が進むにはしばらくかかりそうです。
メッシュの生成まで公開されていれば、Google Colabなど大きなVRAMが使える環境を借りて試すのですが、マルチビューだけなら私は最適化を待つことにします。すでにComfyUIに取り込むなどの動きもあるので、近いうちにローカルでも動作するでしょう。
メッシュ生成部分まで公開されて、その実際の品質がサンプル並みに高ければ、ぜひローカルで生成を試したいと思います。
3D生成の需要
AIでの画像の生成が一気に広まった2022年以降、3Dオブジェクトの生成も多くの研究やオープンなモデル、商用サービスが登場しました。画像に比べてゆっくりですが品質や効率の向上が続いています。SV3Dもそうした流れのひとつです。
高品質な3D生成が可能になると、その応用範囲は非常に広いです。ゲームなどのエンターテインメント用はもちろん、XRデバイスでの利用や3Dコンパニオン、物販、医療、設計などいくらでも考えられます。
OpenAIやGoogle、Facebookなど大手も取り組んでいるはずですが、それらがオープンなるとは限らず、Stablity AIの取り組みはローカルで動かしたい者にとって貴重です。
とはいえ求められるマシンの性能が大きすぎると気軽に試せません。そこで次の記事では、やや低品質ながらローカルでも手軽に高速に動作する3D生成の「TripoSR」を紹介します。




