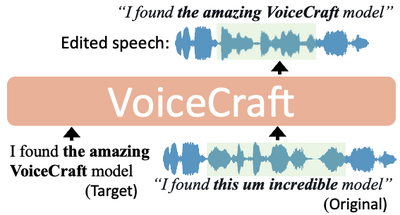
OpenAIは3月29日、15秒ほどの短い音声を元に、本人そっくりで、感情を込めたリアルな音声を生成できるAIモデル「Voice Engine」を発表しました。元音声と生成音声のサンプルがいくつか公開されています。

同種の技術であるマイクロソフトのVALL-E Xは、わずか3秒の音声データを元に、その人らしさを保った発声を可能とするAIモデルで、発表済み。
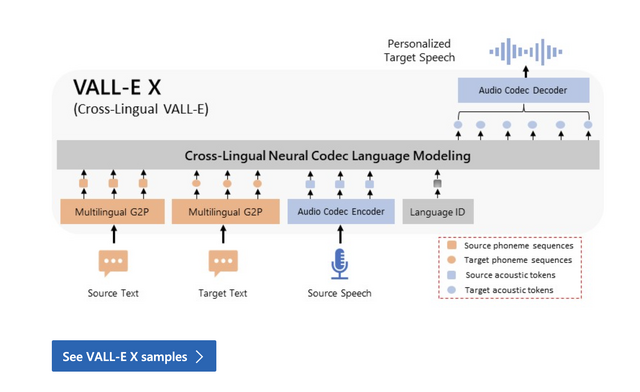
マイクロソフトはディープフェイクを恐れてコードを非公開のままですが、この技術をオープンソース実装したソフトウェアは2023年の8月に公開されています。
VALL-E Xはテキストからの推論に時間がかかるため、昨年に検証した時点では実用的レベルではありませんでしたが、Voice EngineはGPT-4のテキストレスポンスをリアルタイムで音声にできるとしており、推論スピードの点では問題なさそうです。
Voice Engineはごく限定的なユーザーにのみ提供されていますが、その一つが、AIアバターサービスのHeyGen。同社のサービスは実用的レベルのリップシンク技術が知られていますが、もう一つの柱は、企業向けのカスタマイズアバターサービスです。ChatGPTと連動してカスタマイズされた音声で応答するサービスも提供していますが、その音声技術の出所についてはこれまで言及していませんでした。
それが、今回のOpenAIの発表により、HeyGenのカスタマイズ可能な音声技術はOpenAIのVoice Engineであることが判明したというわけです。
Voice Engineの採用例としては、HeyGenの他に、リアルタイム翻訳機能や自分の声を失う可能性のある患者用のTTSといった用途を挙げています。
ただし、現時点では一般公開の予定はありません。金融機関でのID詐称などの悪用を防ぎ、個人の音声AIを防御するといった手段を確立する必要があると、その理由について説明しています。
しかし、VALLE-Xのオープンソース実装やSoraに対するOpen-Sora同様、短時間の音声から高品質でリアルタイムに近い応答性と本人性を持ったAI音声モデルが登場するのは、時間の問題でしょう。