








4月15日、OpenAIが日本オフィス開設を発表した。すでに報道されているように、アジアとしては初の拠点、本拠地であるサンフランシスコ以外の拠点としては英国のロンドン、アイルランドのダブリンに続く3か所めとなる。

もっとも、昨年OpenAIのCEO サム・アルトマンが来日した際には、すぐにでも日本での活動拠点を設けるとの話をしていたから、予想よりも時間がかかったということになるだろう。その背景としてあるのは、最高の人材を確保したいためという理由があったようだ。
日本法人の代表は、2月までアマゾンウェブサービスジャパン(AWSジャパン)で代表取締役社長を務めた長崎忠雄氏。同氏は保守的だった日本の企業向け市場においてクラウド活用を推進するため、粘り強く対話してクラウド型のプラトフォームを根付かせた功労者だ。
OpenAIが開発する様々なAIサービスを日本で根付かせるという意味ではまさに適任ではあるのだが、この手法はOpenAIが日本でどのような事業を行っていたいのかを透かして見る上で重要な発表だった。

本誌の読者は、日本オフィスが生まれることで、一体OpenAIの何が変化するのか? というところが気になるのではないだろうか。エンドユーザーとしてはChatGPTがどうなるのか、技術開発に興味がある人にとっては、日本がAIの新たな技術発信拠点となっていくのか? といったところも気になるかもしれない。もちろん国産AIの開発がこれによって影響を受けないか? といったことを懸念している人もいるかもしれない。

そこでこのコラムでは、テクノロジーに興味のある人、OpenAIのChatGPTをユーザとして使っている人たちがどのような影響を受けるのかについて話をしたい。
日本語カスタムモデルで何が変わるの?

OpenAIの日本オフィスが生まれると聞いて、新たに日本でAI技術の開発が行われると期待していた人たちには肩透かしの発表内容だったかもしれない。
実は、発表会場でも記者からはやや誤解を感じる質疑応答があった。短時間での記者会見では詳細が分かりにくいこともあり、行き違いは不思議ではないのだが、このやりとりにはとても重要な要素が含まれている。
OpenAIは"GPT-4の日本語カスタムモデル"の提供が開始されたことアナウンスした。
AIモデルに日本語に適したカスタマイズを施すことにより、速度は最大で3倍、効率も大幅に改善し、使用されるトークンはあるアプリケーションにおいて47%削減されたとされる。
この発表に対して、こんな質問があったのだ。
「日本語カスタム版の提供に際して、どのような日本の文献データを使って学習させたのでしょうか?」
記者発表の中では、単純に"AIモデル"が日本語にカスタマイズされたものとしか紹介されていなかった。学習のデータモデルが日本語に最適化したのだろうと考えての質問だったのだと思う。
実際には、日本語の文章の解釈や作成における語順等の最適化をAIの推論モデルにおいてカスタム化し、データを学習させる上での重みづけについて日本語に適した形へと変更したようだ。
ようするに最終的に作られたAIモデルが日本語に適しているということであり、日本語の文章作成能力や解釈をする能力が高まっている事は確かだが、そう単純ではないということがわかるだろう。
実際、ChatGPTを使っていて、日本語の文章が不自然だと思っている方は少なくないと思う。さらに不自然なだけではなく、効率の点でも悪かったため、速度が3分の1、トークンもおよそ2倍多く消費していたということもできる。
つまり、日本語圏でOpenAIが大規模言語モデルを使った事業を広げていく上で、日本語という特殊な言語に対応していく事は必要不可欠であるため、その最適化を図ったということだ。
日本に拠点を据えて特別な開発を行っていくといった文脈ではなく、日本というAI活用が注目されている大きな市場において、実用的なAIサービスを作るための拠点を置いたと言う方が正しいだろう。
今後、数か月以内にAPIを通じたアクセスも解放されるとのことだが、日本語対応のカスタムモデルを用いることにより、OpenAIのサービスを通じて開発しているアプリやサービスは大幅にコスト削減できるはず。
これはAIサービスをAPIとして引用し、自社のアプリケーションサービスに組み込んでいる企業にとっても大きな違いだとは思う。
ただ、OpenAIがこうした対応をとったことによって、国産AIプロジェクトに関しては、その優位性が失われる可能性があるかもしれない。
OpenAIが日本法人を通じてやろうとしていること
日本を新たな開発の拠点とするわけじゃないの?
もちろん将来的にはその可能性もあるかもしれない。しかし、現時点における主な目的は異なる。
OpenAIが提供するAIモデルやAPIが日本のユーザの中でどのように使われ、日本のユーザからどのような要望があるのかを的確に情報収集し、サービスへと反映していくミッションが最も大きく、最初の役割になっていく。
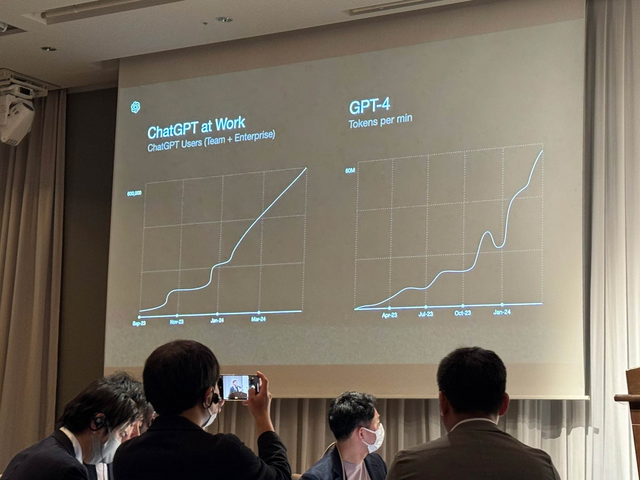
OpenAIは企業向けにChatGPT Enterpriseといった製品を提供している。ChatGPT Enterpriseは、OpenAIが提供するChatGPTのビジネス向けバージョン。企業や組織が独自のニーズに合わせ、カスタマイズ学習できるよう設計されており、自社内のデータを独自の処理インフラ内で動作させることもできる。
特に取り扱うデータのプライバシーやセキュリティが重視される企業向けに高度なセキュリティ対策やカスタマイズが提供されているわけだ。こうした顧客とのコラボレーションが必要不可欠な商品を売っていくためには、日本法人を設立する以外の方法はなかっただろう。
前述した日本語カスタムモデルの提供も象徴的な動きだ。今後も日本語環境、日本企業におけるサービスメニューや機能、AIモデルのカスタマイズといった形で、日本市場の開拓を行っていくことになるはずだ。長崎氏がトップに就任したのも、そうした事業開発を優先事項としたからにほかならない。
いずれはコンシューマユーザのサービス品質向上にも
では、一般のコンシューマーユーザにはほとんど関係のない話なのだろうか?
今回の東京オフィス設立においては、日本語カスタムモデルをChatGPTに盛り込むことに関してはほとんど話題にもならなかった。それだけ記者会見の内容が企業向けに特化していたこともある。
もっとも、今回発表された日本語カスタムモデルが直接使われるかどうかは別として、言語ごとに最適化し、効率を高めたAIモデルを用いる事は、ChatGPTを運営しているOpenAI自身にとって収益性を高めるという大きな意味を持っている。
何しろ日本におけるChatGPTユーザは200万人とも言われる。
日本語の文章が堪能になることも大きな意味を持つが、処理効率が高まることで、ChatGPTのコストが下がるのであれば、それは当然ながら運営しているOpenAI自身の利益になる。言い換えれば時間の問題で、我々はChatGPTにおいても日本語カスタムモデルを利用することが可能になるだろう。
それは遠い未来ではないと予想している。






