





コンピュータの歴史を暗部も含めてていねいに掘り起こすことで定評のある大原雄介さんによる連載17回目。古くからのMac、PDAユーザーなら知っている人物がちらほら。
「Hobbit」の名前を知っている方はかなり少ないと思うが、その少ない方の代表例が本稿編集担当の松尾さんではないか、という気がする。いろんな意味でAppleに絡むことになったからだ、ただ、絡んだといっても直接というよりは間接的にという感じではあるのだが。
話は1975年に遡る。この年AT&T Bell Labsは、The C Machine Projectをスタートしている。C Machineの対象はもちろんC言語のことである。
The C Machine ProjectとCRISP
C言語は1972年、やはりAT&T Bell Labに在籍していたDennis M. Ritchie博士が開発した言語であり、Ritchie博士が同僚であるKen Thompson氏と共に開発したUNIXの記述言語としても知られている(*1)。
*1:元々のUNIX Kernelはアセンブラで記述されており、CはUNIX上で動くアプリケーションの記述に使われていたが、後にKernel全部がCで書き直された
ちなみに筆者はK&R(Brian W. Kernighan博士とRitchie博士の共著である"The C Programming Language"でC言語を勉強したクチである)。まぁそんな訳でC言語は広範に使われ始めることになるのだが、C言語そのものは機種非依存性を高め、様々なプラットフォームに移植されていく。
当然この過程で、C言語の仕様そのものが「どんなプラットフォームでも利用できるように汎用化する」のは当然である。もちろん限界もあって、例えばiAPX432の様にメモリアクセスの際に直接アドレス指定出来ず、Address Descriptorを介して指定するようなアーキテクチャの場合、メモリのポインタをどうやって実現するのか想像もつかないのだが、まぁこれは余談である。
そんな訳で本来はアーキテクチャ非依存のC言語であるが、AT&T Bell Labは逆に「効率的にC言語を実行できるアーキテクチャを考えよう」という逆のアプローチの研究を始めた。これが冒頭に述べた"The C Machine Project"である。もちろんC言語を直接解釈する訳ではなくMachine Codeを実行する訳だが、どんなMachine Codeであれば効率的にC言語を実行できるようになるかを調べよう、という訳だ。
まず最初に行ったのは、様々なアーキテクチャの上で動作するCコンパイラの開発と、これを用いてUNIXやアプリケーションを移植し、そのMachine Codeを分析することだ。
この中には生成したCodeの解析とかパフォーマンス分析なども含まれる。目的は違うがHennessy & Pattersonの"Computer Architecture A Quantitative Approach"(日本語訳はこちら )と同じやり方である。
おおよそ6年程この研究は続けられた後、この研究の成果を生かした実際のチップを作ることになる。1981年、まずはこのC Machine ArchitectureをECLベースのDiscreteチップを利用して、部分的に実装された。
この結果は悪くないと判断されたのだろう、1983年には実際にこのC Machineのアーキテクチャをフル実装したCRISPチップの開発がスタート、1986年に1.75μmプロセスを利用した16MHz駆動のCRISPチップが完成する(Photo01)。

▲Photo01:出典はJohn Hines氏のFlickr。総トランジスタ数は17万2163個だそうだ。左上に"CRISP Microprocessor""Bell Laboratories"の文字が見える
ちなみに論文の筆頭著者はDavid R. Ditzel氏である。Bell Labの後SPARCの開発などに携わり、Transmetaを創業してCrusoe/Efficionを開発、その後Esperanto Technologiesを創業し会長兼CEOを務めていたが、最近は会長/CEO職から降りてCTOを務めている、あのDitzel氏である。ちなみにDitzel氏はDecoder周りの設計を担当したらしい。
CRISPの設計思想は、その時点で現存するCPUより良い性能/コスト比を実現することである。これに関しては4つの目標が掲げられた。
(1) Procedure Call(要するに関数呼び出し)が全体の処理時間の半分を占めているケースがVAX上で存在しており、これをもっと高速化する
(2) コンパイラに、まだ実現していないような複雑な処理無しで、多数のレジスタを効率的に利用できる方法を検討する
(3) 命令を単純化し、効率的なパイプライン実装を可能にする
(4) 分岐によるパイプラインの中断に伴う性能低下をなるべく回避する
といったあたりだ。
これだけ見ているとRISCプロセッサの考え方に通じるものはあるのだが、RISCプロセッサそのものではない。Photo02が命令一覧とそのフォーマットであるが、Addressing ModeにImmediate/Absolute/Stack Offset/Stack Offset Indirectと4種類もあるあたりはちょっとRISCとは言いにくい。
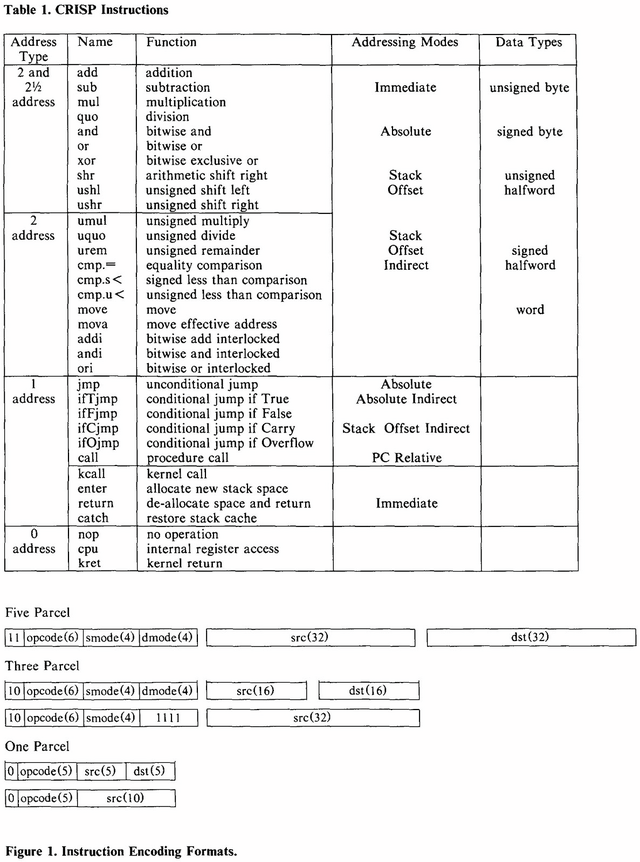
▲Photo02:16bitの塊をParcelと呼んでおり、なので命令長は1/3/5 Parcelということになる
OpCode長は16bit固定であるが、命令そのものは完全に32bit化されており、このため命令長は16/48/80bitの3種類である。ただOpCode先頭が0なら16bit、10なら48bit、11なら80bitと一意に決まるので、可変長命令といってもデコードは容易である。
命令そのものはご覧の通り35しかなく、当然整数演算のみである。まぁ実験用のプロセッサとしては必要十分といったところか。
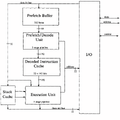
さて、そのCRISPの内部構造がこちら(Photo03)。
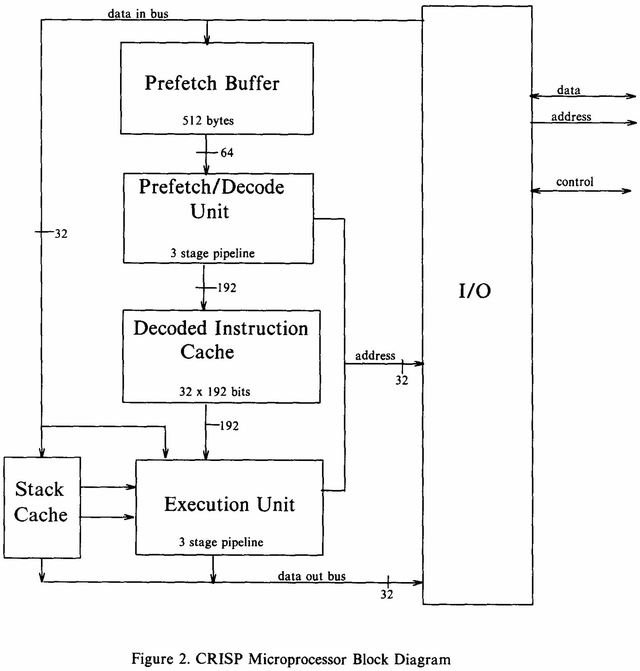
▲Photo03:Decode後の内部命令は192bit幅になる格好である
一見して明らかに変なのが
・Decoded Instruction Cache
・Stack Cache
の存在だ。
Decoded Instruction Cacheは後述するとして、Stack Cacheは何をしているか?というと、CRISPではRISCプロセッサとは異なるアプローチをとった。
RISCプロセッサでは利用できる汎用レジスタの数を増やし、そもそもStackとかを多用しなくても汎用レジスタを使いまわすことで処理を行えるようにした。ただこれはコンパイラの側が頑張らないと性能が出ないことになる。そこでStackの処理を高速化することで、コンパイラがさして頑張らない(従来型のStackを多用するコードを生成する)場合でも性能が出るように工夫された。IntelがBaniasで導入したDedicated Stack Managerをちょっと連想する実装である。
このStack Cacheは32段分が用意され、MemoryにMappingされている。逆に徹底しているのが、いわゆる汎用レジスタに相当する、アプリケーションから見えるレジスタはCRISPにはほとんど無い(論文にも"Unlike most computers CRISP has no visible data or address registers."とある)。要するにStackを使って全部処理しろという訳だ。
ただStack Cacheがあるから結局汎用レジスタを使っているのとほぼ同じLatency(ただし最大32個まで)でアクセスできることになる(ちなみにStack Cacheは1cycleあたり2つの独立したReadと1つのWriteが同時に可能とされている)。なかなか尖った設計である。
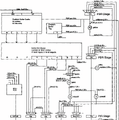
さてもう一度Photo03を見ると、Prefetch→Decodeは64bit幅なのに、Decodeの結果は192bitに増え、しかも途中でDecoded Instruction Cacheなるものを挟む格好だ。これ、Sandy Bridgeとかに導入されたμOps Cacheとはちょっと様相が異なる。まずPrefetch&Decode(Photo04)を見ると、1cycleあたり4×16bit(というか4 Parcel)を取り込み、これを5つのブロックに分解しているのが判る。
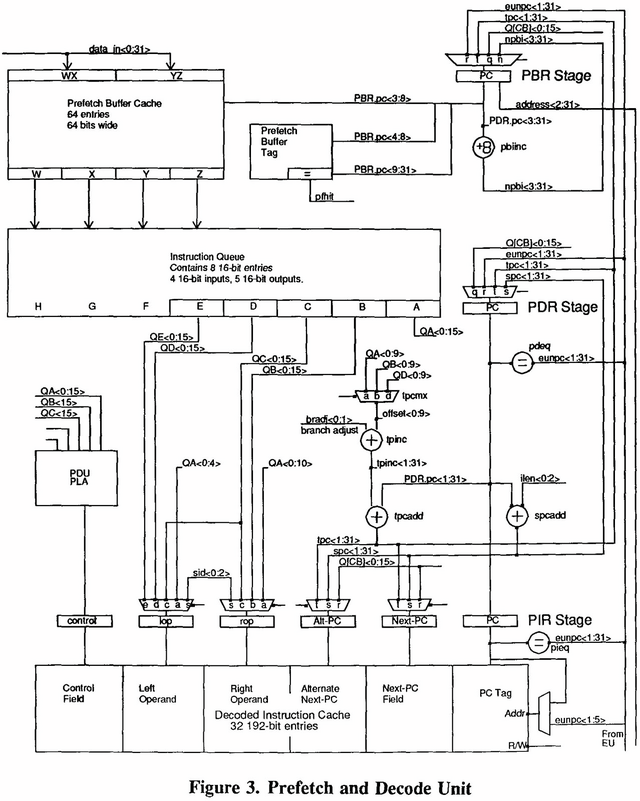
▲Photo04:PDUはPrefetch & Decode Unitの略なのは明記されているのだが、PLAの説明がない。ただこのPDUPLAユニットにQA~QCの3つのParcelからのデータが渡され、これがDecodeの制御を行っている事は明記されている
1 cycleあたり4 Parcelということは5 Parcelの命令(主に演算命令)は1cycleでDecodeが間に合わない形になるが、3 Parcelの命令とか Parcelの命令も同時に取り込めば平均的にはほぼ1cycleになるし、先に述べたDecoded Instruction Cacheがバッファになるから、実際にはほぼ1命令を1cycleで実行できるものと考えられる。
それはともかく、元の命令セットが5つの32bitブロックに分割され、さらにControl Fieldからくる分も合わせて、6つの32bitブロックとなって(Cacheを経て)Execution Unitに渡される格好だ。
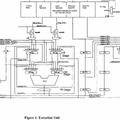
ではExecution Unitは?というとPhoto05のようになっており、構造そのものは比較的シンプルである。
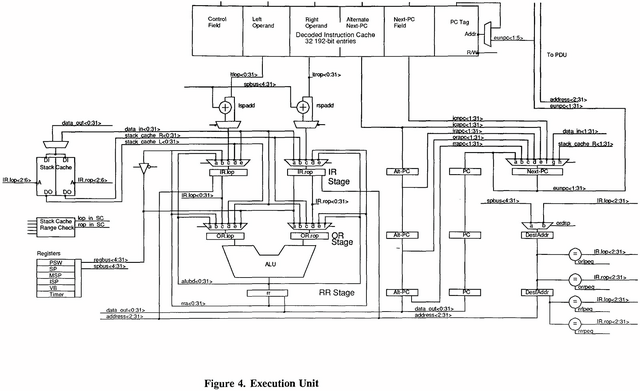
▲Photo05:そもそも演算命令をLeft OperandとRight Operand別々に処理を行い、最後にALUにまとめて処理というのはなかなかゴージャスというか、もう少し何とか出来る(というか、これなら同時2命令の処理も出来たんじゃないか)という気はしなくもない
ALUは1個だけだ。ただ面白いのが、Next PCとAlternate Next-PCの2つのブロックが用意されており、ここで分岐が入った場合の先読みを行わせ、仮に分岐した場合にもパイプラインが中断しない様に工夫されているのが判る。
先のDecoded Instruction Cacheは、このAlternate Next-PCの先の命令も保持することが可能であり、これで分岐があった場合のペナルティを最小にできるという訳だ。
ところでこのブロックを改めて見直すと、要するにRISC風(あくまで風)である命令セットを内部でVLIW風に変換し、処理するという仕組みに見える。
これは何かというと、Ditzel氏がTransmetaでCrusoeとして実装したプロセッサそのものである。もちろんVLIWと言いつつ実際には1命令/cycleだから、あんまりVILWっぽくはないのだが、Crusoeの原点はこのCRISPだったのでは?という気がする。
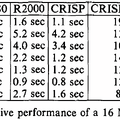
そのCRISPの性能として示されたのがこちら(Photo06)で、R2000はともかくVAX/11-780と比べるとかなり高速であるのが判る。
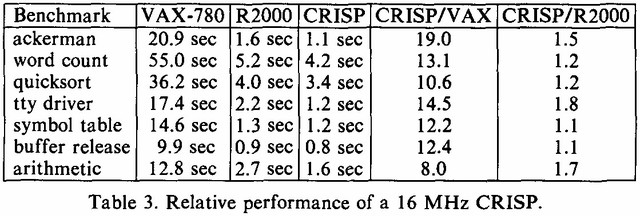
▲Photo06:MIPS R2000は、M/500というMIPSが出していた開発ボード(R2000/5MHz搭載)での数字なので、同じ動作周波数だとかなり性能面では負けている気はする。ちなみにWikipedia( https://en.wikipedia.org/wiki/AT%26T_Hobbit )ではR2000/8MHzと記載されているが、M/500は5MHz駆動であり、8MHz駆動だとM/800になるはずなので、ここは5MHzが正解だと思う
ちなみに最初のバージョンのCRSIPチップは16MHz駆動だったが、マスクを作り直した第2ロットでは20MHzまで動作周波数を上げられたそうで、さらに高速化できているとする。
有名なところでDhrystoneだとCRISPのスコアが13560、VAX-11/750だと997で、13.6倍高速という数字も示されている。
Cコンパイラを利用して生成した命令の処理速度はおおむね1.3cycle/命令ほど。CRISPは内部にDRAMコントローラも搭載していたが、これを利用して外部DRAMを使ったOne-wait状況だと、キャッシュを利用したZero-waitの場合より20%程性能が落ちたそうだ。
ちなみにR2000と比較した場合、CRISPが1チップでシステムを構成できるのに対し、R2000だとCPUに2つの外部キャッシュチップが必要で、さらに周辺チップを全部合わせると30チップ程になるため。遥かに低価格かつ効率的になる、としている。
CRISPからHobbitへ
CRISPはあくまでも実験的なチップではあるが、このように割と成功を収めたため、AT&Tはこれをベースに商用チップを生産することを目論む。それが今回取り上げるHobbitである。
もっともその道のりはストレートではなかった。実はこのあたりがハッキリしないのだが、少なくとも1991年にATT2100というチップが量産されたのは間違いない(Photo07)。
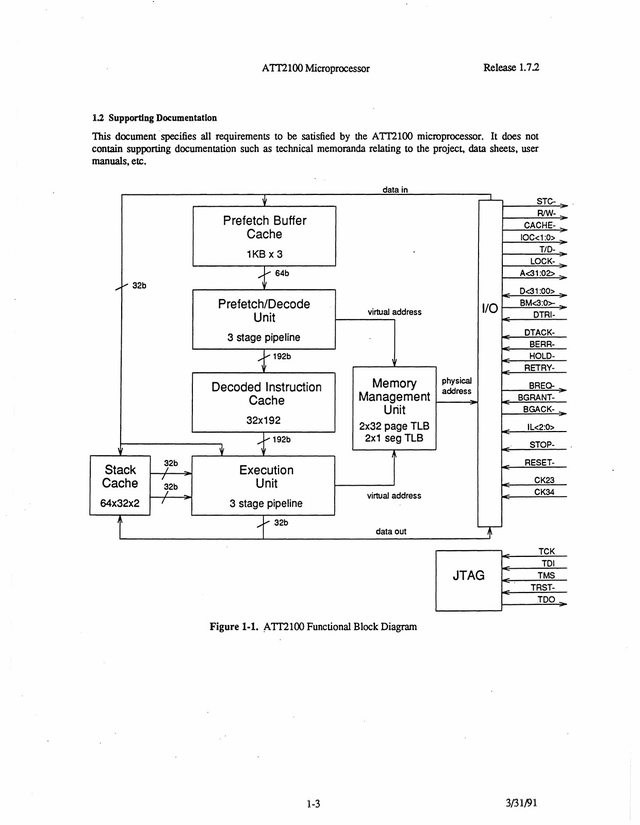
▲Photo07:I/Oがかなり充実したほかJTAG I/FとMMUまで追加された。Stack Cacheの容量も倍増している
AT&Tは当時WE32000シリーズ(元はBellmac 32という名称だった)という1980年代に開発された32bitプロセッサを社内のシステムに使っていたが、WE32000/WE32100/WE32200と3世代を経たところでAT&Tはこの32bitプロセッサの開発をこれ以上行わないことを決定。代わりに当初はSPARCを採用することを考慮し、最終的にMIPS R3000の採用を決めている。
ちなみにこのWE32200に続く製品開発の打ち切りを受けてDitzel氏はAT&Tを辞してSun Microsystemsに移籍した。
ただR3000は高性能ではあるが高消費電力でもあり、また回路規模も大きい。低消費電力かつコンパクトなMPUも必要ということで、CRISPをベースに開発されたのがこのATT2100シリーズである。
命令数は58に増え、その中には12の浮動小数点演算命令も含まれている。もっともATT2100では命令定義こそされたもののインプリメントはされなかった。
ATT2100はCMOSで製造され、電源は3.3V。動作周波数は20MHzとされているまたLow Power Standby Modeも実装されている。Photo07で判るようにDRAMのI/Fも内蔵しており、最小限の外部チップだけで動作するので、組み込み向けなどにも向いた構成だったと思われる。ただこのチップ、どこまで広く利用されたのかがさっぱり判らない。
またATT2100の後継製品があるのか、あるいは定義だけで実装されなかった浮動小数点演算命令が実装されたバージョンがあったのかも不明である。というのは、上に書いたWE32000シリーズを打ち切ってMIPSに鞍替えしたのはAT&TのComputer Systems Groupであったが、AT&T MicroelectronicsがこのATT2100シリーズを手掛けたらしい。
アップル、ジャン=ルイ・ガセー、ラリー・テスラー
実を言うと、1988年にApple ComputerがAT&Tに未公開の資金(一説には600万ドルらしい)提供をして、2nd GenerationのCRISPの開発を依頼したという話がある。
これはAppleのNewtonに採用される予定だったもので、これを進めていたのはJean-Louis Gassee氏だったが、その後AppleからGassee氏が追放されると、後任になったLarry Tesler氏(VP, Advanced Products Group)はARMコアの採用を決め、この2nd Gen CRISPの話は消えてしまった。
ATT2100はまさにこの2nd Gen GRISPだったのではないかと筆者は疑っている。昔のcomp.archに、「ATT2100とHobbitは同じものだ」という投稿もあり、最初のHobbitはこのATT2100を流用したものと筆者は考える。
Go、PenPoint、そしてEO
さて話はここからちょっと飛ぶ。1987年、Jerry Kaplan/Robert Carr/Kevin Dorenの3氏はGo Corporationを設立した。1992年1月にはPenPointと呼ばれる製品をNCR、MicroSlate、IBMの3社が発売している。
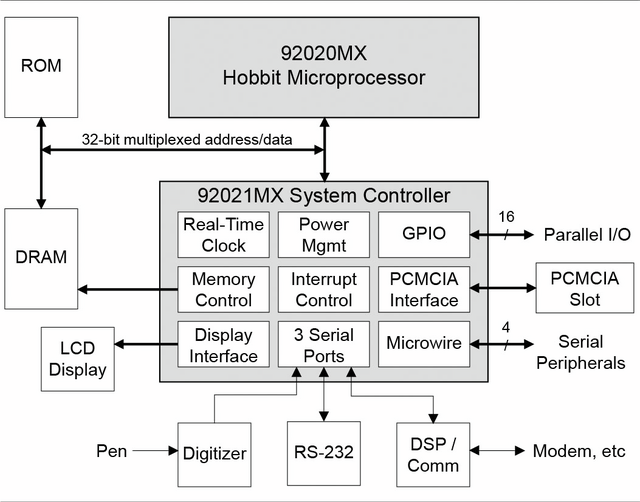
実はこれにAT&Tも絡んでいた。1992年の秋に開催されたCOMDEX Fallで、AT&TはEO-440 Personal Computing Systemなる手書き入力システムを搭載したPDA(というには結構デカい、今でいうTabletサイズ)を発表しているが、ここに使われたのがHobbitであった。

▲EO(出典はJerry Kaplanの個人サイト)
このEO-440を開発したのはEO Personal Communicatorという会社で、ここはGo Computingからのスピンアウト組で構成されていたのだが、1992年にAT&Tに買収され、AT&Tが発売元になった。といってもAT&Tが自身で製造していたわけではなく、マシンの製造はPanasonic、チップはNECがセカンドソースの形で製造を行っていた。
さてそのHobbitチップ、1992年にAT&T 92010として発表される。プロセスは0.9μmのCMOSプロセスが利用され、電圧3.3Vで20MHz駆動時の消費電力は400mW。13.5 DMIPSというのは、CRISPと大体同程度の性能と考えれば良い。ちなみに量産時の価格は当初50ドル未満とされたが、後に35ドルまで下がった。
同時に92011(System Management Unit)、92012(PCMCIA Controller)、92013(Peripheral Controller)、92014(Display Controller)などの周辺チップも発売され、これらを込みにした価格でも100ドル未満という話であった。
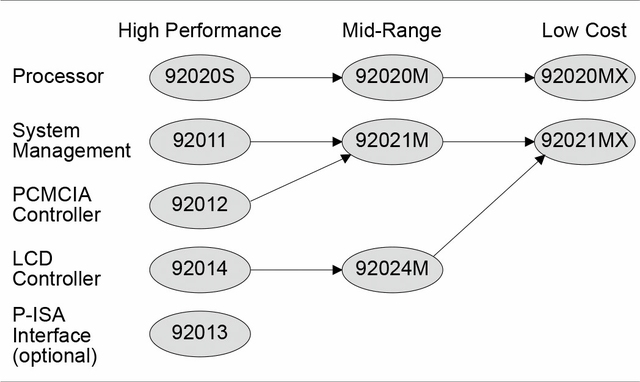
翌1993年には、0.7μmプロセスに微細化するとともに、Prefetch Bufferを1KB×3から2KB×3に増量したAT&T 92020Sも発表される。
動作周波数は変わらず20MHzであったが、キャッシュ増量の効果で性能は16 DMIPSに向上。その一方で消費電力は210mWまで下がっている。周辺チップは92021M/92021MX(System Management Unit)と92024(Display Controller)が用意されたが、この92021MXが全部入りのハイエンドで、これ一つで全部賄えるようになっている(Photo08)。
▲Photo08:出典はMicroProcessor Report Vol.7 No.14。PDA的な製品であれば、確かにこれだけで全部カバーできる
突然の別れともう一つの分岐点
AT&Tはこれに続き、さらにこのHobbit製品のバラエティ展開を考えていた(Photo09)のだが、1993年末にAT&T Microelectronicsは一転してHobbit製品の販売中止を決定する。
▲Photo09:出典はPhoto08に同じく。このロードマップを出した直後に打ち切りを決めるあたりがAT&T
理由は不明だが、思ったほどに売れないと見切ったためだろうか? 悲しいのは、このニュースをEO-440を開発していたグループが公式発表まで知らなかったことだ。NECにセカンドソース委託をしていたからすぐに製造に困りはしないとは言え、先が無いのは明白である。結局EO-440は大した実績も残せないまま市場から消えていった。
もう一社、HobbitのユーザーだったのがBeである。
Appleから追放されたGassee氏が興した会社であり、自社の独自OSであるBeOSの開発を行っていたのだが、このBeOSのターゲットがHobbitであった。ただこちらもHobbitの販売中止を受け、ターゲットをPowerPCに変更することを余儀なくされた。

▲PowerPC 603を搭載して発売されたBeBox(出典はGasseeの個人ブログ)
かくしてHobbitは大した成果を出すことなく、市場から消えることになってしまった。




