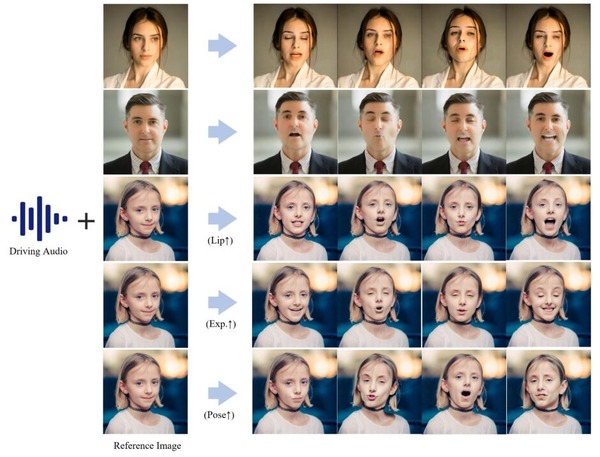



おもしろそうな動画AIの新技術が相次いで登場しています。中でも、オープンソースで発表された、画像内のキャラクターに歌わせる「Hallo」に注目が集まりました。
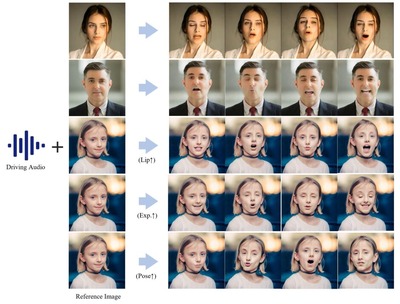
そんな中、同じくオーディオに合わせたリップシンクができる別の技術が登場しました。Hedraという、ゴジラと対決しそうな、これまで聞いたことのない会社の「Character-1」というサービスです。


リップシンクは動画生成AIサービスが多く手掛けてきましたし、オープンソースソフトもいくつかありますが、満足できるものがなかなかないというのが現状です。
筆者が現在リップシンクでメイン使いしているのは、HeyGenです。Sad TalkerはAUTOMATIC1111のプラグインとして無料で使えますが、リップシンクが不自然で、商用サービスとして先行してたD-IDも不自然さが目立ちました。
HeyGenは1曲まるごとのリップシンクができるうえに、PikaやRunwayのリップシンクでは口を開けた際に下の歯だけ見えるなど不自然さがあるのに対して、口を開けても違和感が少ないのは大きなメリットです。
しかし、髪の毛のボリュームがあるとその部分が固定されて見えてしまい、不自然さが目立ってしまいます。このため、リップシンクを使うときにはショートヘアにするなどの工夫をしていました。
こうした問題点を解消できるのではないかと期待大なのが、Hedra Character-1とHalloです。
■感情豊かな表現と高速処理が売りのHedra Character-1
では、まずHedra Character-1から試してみます。
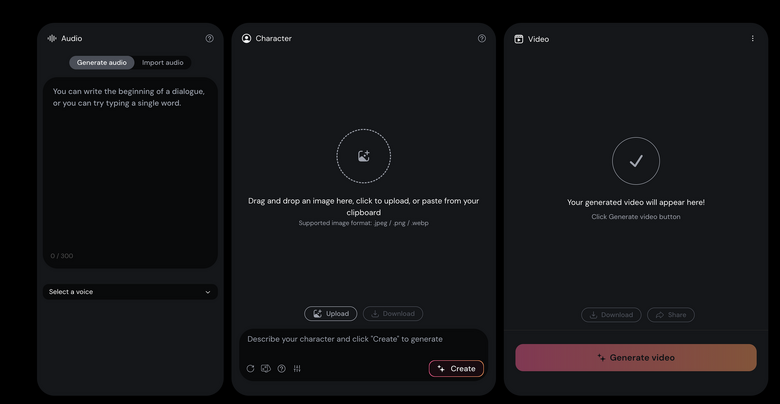
画面は、オーディオの入力画面、キャラクター画像の入力画面、そして生成動画のプレビューとに大きく3分割されています。
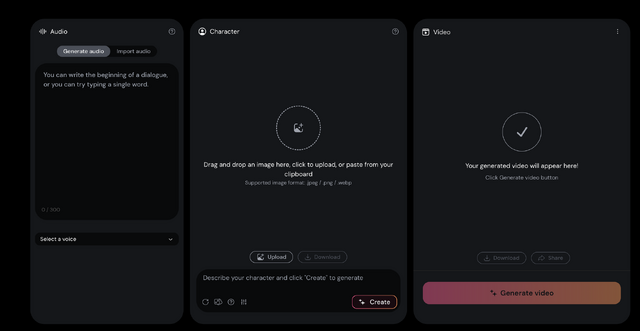
(▲画像:Hedra Character-1のユーザーインターフェース)
参照するオーディオはアップロードすることも、テキストを入力してプリセットキャラクターに喋らせた音声を使うこともできます。
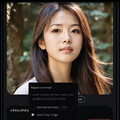
話す・歌うキャラクターはローカルの写真や画像をアップロードすることも、プロンプトで作成も可能です。
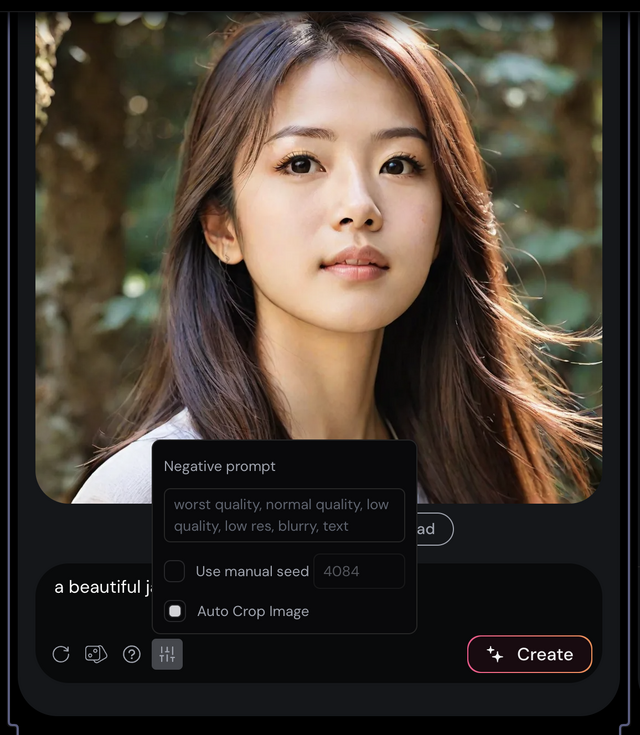
(▲▲画像:プロンプトで生成したキャラクター。ネガティブプロンプトも使える)
まずオーディオクリップをアップロードします。フォーマットはMP3かWAV。長いクリップは先頭から27秒で切られます。アップロードしたクリップはその中で範囲を指定できます。
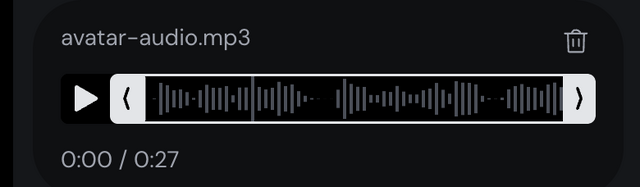
キャラクター画像はできるだけ正面を向いていて、顔が大きく写っているものが推奨されています。アップロードすると顔周辺が正方形に自動クロップされるので、前処理は不要です。
ファイルフォーマットはJPEG、PNG、WebPのいずれかで、サイズは10MB以下。
結果、たしかに感情豊かに表現してくれますし、髪の毛も手などの動きも違和感はありません。ただ、2つの点で問題があります。
まず、アップロードする写真・画像がUnderageと判断され拒絶されることが多いという点。アジア系の顔だとリジェクトされるようです。

長男を出産後の妻の顔もunderageとしてリジェクトされました。

celebrityとしてリジェクトされたものもあります。
もう一つは、学習データが欧米系中心のせいか、少しでも角度が変わると「この人誰?」となるように骨格が変わってしまうところ。確かにかなり骨ばった顔になってしまいます。
日本のことなんて考えてないのはヘドラというネーミングからわかります(たぶん違う)。
作例はかなり欧米化が少ないものを選びましたが、それでも表現が大袈裟すぎたり、もうちょっとなんとかならんかという感じがします。
こちらは欧米化がもっと進んだもの。
感情豊かな表現ができるのはわかるけど、そのレベルはコントロールさせてほしい。アップテンポの激しい曲やラップならばこれでいいけれど(作例もそういうものが多い)、バラードや静かな曲では表現過多に思えます。
ほんと惜しいんだけど、これではHeyGenを置き換えるほどではないです。
■NVIDIA必須。4090でも遅い。細かいコントロールが可能なHallo
対するHalloはどうでしょうか?
Halloは現在NVIDIAのGPU専用。本家ページにはWindows版のインストール方法が書かれていますが、執筆時点ではWeb UIにはなっておらず、コマンドラインでソース画像とソース音源を指定する必要があります。
これでは使いにくいということで、Gradioで動くようにしたDocker版とPinokio版を有志の方が公開してくれています。今回はそのPinokio版を使って、自分のGALLERIAマシン(Core i7 + RTX4090)にインストールしてみました。
PinokioはAIアプリケーションを簡単にインストールできるブラウザアプリで、注目すべきAIアプリが登場すると、比較的早く対応してくれます。Pinokioを使うと、コマンドラインをほぼ使うことなく、簡単にインストールが可能です。
さて、そのPinokio版(Gradio版)Halloですが、画面はこんな感じです。
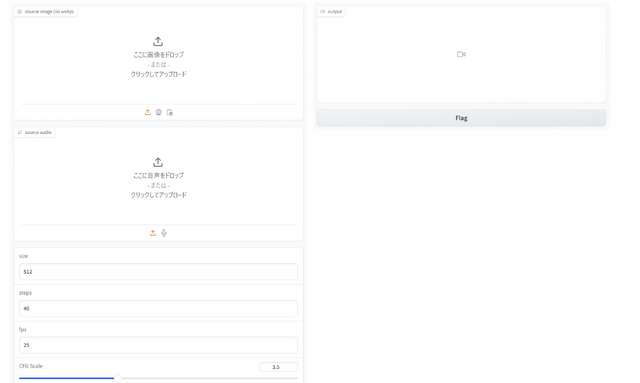
Hedra Character-1と同じく、元サウンドと元絵があるやり方。参照オーディオとキャラクターの絵をそれぞれ入力します。
参照オーディオは後でトリミングが可能。画像は自動的に正方形トリミングしてくれないので、あらかじめクロップしておく必要があります。
オープンソースのリップシンクとしてよく使われてきたSad Talkerとは段違いの性能がありますが、それでも弱点はあります。
髪の毛の色がときどき不自然に白っぽくなるのと、推論(処理実行)にすごく時間がかかることです。4090を使っても1秒あたり1分かかるというところでしょうか。
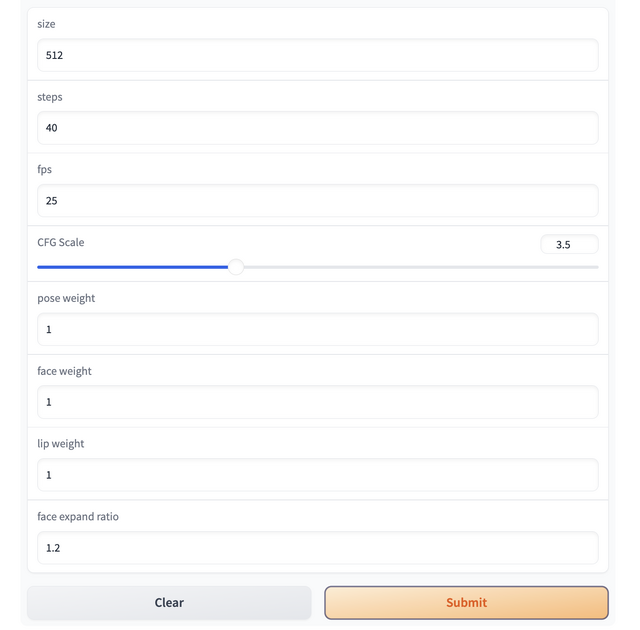
しかし、それを補う利点もあります。それは細かいパラメータ設定。画面サイズ、ステップ数、FPS、CFGスケールといった画像生成Aiにお馴染みのパラメータに加え、ポーズ、顔、唇、顔の拡張比率といったところも微調整できるようになっています。
ステップ数を増やせば画質は向上するはずで、追い込んでいけば、より自然なリップシンクが可能になると思います(処理時間は増えますが)。
それでもローカルマシンだけで時間があるときに一括処理ができることを考えると、現時点ではこちらをメインに据えた方が良さそうです。
Hedra Character-1もHalloもまだ最初のバージョンが出たばかり。古参であるHeyGenとSad Talkerも頑張ってリップシンク業界を盛り上げていってほしいものです。