

中国開発のオープンソース謳うAI作曲ソフト「YuE」(Yeah!と発音するらしい)。自宅のPCにインストールして楽曲を生成できたので、そのAI作曲体験をまとめました。

まずは最初にできた楽曲を。
では、ローカルマシンへのインストールに時間を巻き戻します。
YuEは非常に重いソフトで、現時点ではNVIDIAのかなり強力なGPUが必要です。また、インストーラは付属しておらず、ターミナルでコマンドラインを駆使する必要があります。
筆者はGitHubページにあるインストール方法に従って数時間トライしてみましたが、ライブラリやバージョン関連の問題が多発し、先に進めない状態になりました。
現時点では、Makiさんによる解説記事がいちばんまとまっています。筆者はMakiさんが成功したというXでの投稿を見て、「できるんだ!」と試行錯誤を続けた次第です。
また、公式認定の解説動画も公開されました。
動画ではスムーズにインストールされていますが、筆者はけっこうつまづいています。
まず筆者の環境から、Windows 11マシン(Core i7 + RTX 4090)に、Anacondaのターミナルを使ってインストールを始めました。
GPUメモリを節約するために必要とされるFlashAttention 2をインストールするのですが、これがなかなかの難物で、依存するライブラリをChatGPTに尋ねながら修正してもいっこうにインストールできません。失敗の嵐です。

数時間後、どうしてもできなくて、成功している方々の環境を見てみると、どうもLinuxでやっているようです。
これはWindowsではダメだと確信し(西川和久さんにもLinuxを使えとさんざん言われていますw)、WSL2をインストールして再挑戦。
CUDAのドライバなどAI向けの環境を設定後に試すと、今度はFlashAttention 2の難所をなんとか切り抜けることができ、YuEのインストールは完了できました。
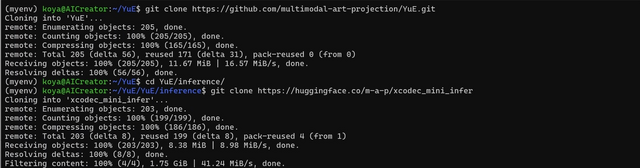
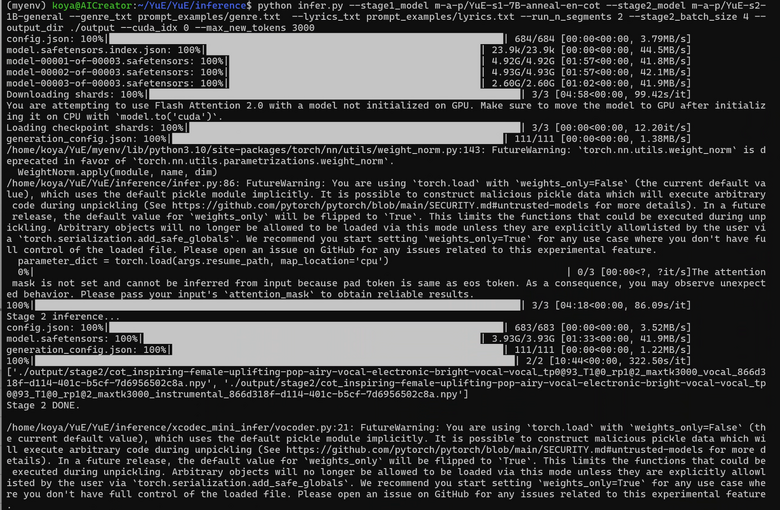
ここでようやく推論(楽曲生成)に入ることができます。使用する主なパラメータは2つ。音楽スタイルと歌詞です。
これらを入れた推論用のコマンドをターミナルに打ち込み、生成を待ちます。
python infer.py --stage1_model m-a-p/YuE-s1-7B-anneal-en-cot --stage2_model m-a-p/YuE-s2-1B-general --genre_txt prompt_examples/genre.txt --lyrics_txt prompt_examples/lyrics.txt --run_n_segments 2 --stage2_batch_size 4 --output_dir ./output --cuda_idx 0 --max_new_tokens 3000
歌詞と音楽スタイルはサンプルにあったものをそのまま使用しています。
歌詞(lyrics.txt)は[Verse]や[Chorus]などのタグが入った英語のもの。フォーマットはSunoやUdioと同じです。
[verse]
Staring at the sunset, colors paint the sky
Thoughts of you keep swirling, can't deny
I know I let you down, I made mistakes
But I'm here to mend the heart I didn't break[chorus]
Every road you take, I'll be one step behind
Every dream you chase, I'm reaching for the light
You can't fight this feeling now
I won't back down
You know you can't deny it now
I won't back down[verse]
They might say I'm foolish, chasing after you
But they don't feel this love the way we do
My heart beats only for you, can't you see?
I won't let you slip away from me[chorus]
Every road you take, I'll be one step behind
Every dream you chase, I'm reaching for the light
You can't fight this feeling now
I won't back down
You know you can't deny it now
I won't back down[bridge]
No, I won't back down, won't turn around
Until you're back where you belong
I'll cross the oceans wide, stand by your side
Together we are strong[outro]
Every road you take, I'll be one step behind
Every dream you chase, love's the tie that binds
You can't fight this feeling now
I won't back down
音楽スタイル(genre.txt)はカンマ区切りもしない、英語の音楽用語の羅列で良いみたいです。
inspiring female uplifting pop airy vocal electronic bright vocal vocal
使用できるタグリストも用意されているのは親切ですね。
最初の推論はこのようになりました。
SunoやUdioと違い、生成プロセスを見ることができるのは非常に興味深いです。
最終的に、59秒のモノラルMP3ファイルが生成されました。
ただ、それだけではなく、ボーカルのみ、インストのみのMP3ファイルも生成されています。

つまり、ボーカル、インストのオーディオがそれぞれ生成され、それをミックスしているわけです。
これは、後でステム処理する必要もないので便利ですね。
次に日本語の歌詞で、音楽スタイルも変更して推論してみました。
3度ほど試行しましたが、日本語で歌い上げてくれるものの、バッキングがつかずにアカペラ化してしまいます。
推論時間はそれぞれおよそ1分の長さで15分弱。
J-POPが音楽スタイルとして拾われていなかったのが原因かもしれません。genre.txtの中身を見直したらバッキングも生成されました。
vocoder>stemsフォルダに、最新生成分のvocal、instrumentalのファイルが生成されます。
max_new_tokensの値を3000から6000まで上げると、さらに長い曲(70秒)を生成できました。
お聞きのとおり、音質はローファイで、Sunoで言えばバージョン1か2くらい。それでも比較的長い曲も生成でき、歌詞内容の制限もないことから、いろいろと楽しめそうです。
また、AIモデルもいろいろと作れそうなので、伸び代はありそう。
Hugging FaceにGradioを使ったGUIデモページができていますが、重すぎて全く生成できない状態。しかし、Web UI化は期待できそうです。
ただ、オープンソースを謳ってはいるものの、Creative Commons Attribution Non Commercial 4.0(CC BY 4.0)、非商用コンテンツというところには留意しておくべきでしょう。つまり、これはオープンコンテンツではあるが、オープンソースではないということです。
ライセンスに関しては今後、ユーザーが増えるにつれて変更される可能性もあるのではないかと考えています。
追記:実際、変更されました。新しいライセンス条項は次のとおり。
私たちのモデルは、Creative Commons Attribution Non Commercial 4.0 の下でライセンスされています。これは、モデルのウェイト自体を商用目的で使用することができないことを意味します。
一方で、アーティストやコンテンツクリエイターが当モデルから生成された出力をサンプリングし、自身の作品に組み込んで収益化することは推奨しています。その際の唯一の要件は、当モデルの名前である「YuE by M-A-P」をクレジットすることです。
また、私たちは本モデルの不正使用(違法行為、悪意のある行為、不道徳な行為などを含みますが、それらに限定されません)に関して、一切責任を負いません。
本モデルによって生成されたコンテンツや、その使用により生じる結果については、すべてユーザーの責任となります。
さらに1月30日、Apache 2.0へのライセンス変更を発表しました。
YuEモデル(およびそのウェイト)は、Apache License, Version 2.0の下で公開されました。このモデルからは利益を得ていませんが、人間の創造性の向上に役立つことを願っています。
使用と帰属:
私たちは、アーティストやコンテンツクリエイターがYuEによって生成された出力を自由に自身の作品に組み込むこと(商業プロジェクトを含む)を奨励します。 特に公共や商業利用の場合は、モデルの名前(「YuE by HKUST/M-A-P」)を帰属として記載することを推奨します。
独自性と盗作:
YuEの出力から派生した作品やインスパイアされた作品が既存の素材を盗用または不正に複製していないことを確認する責任は、すべてクリエイターにあります。著作権侵害やその他の法的違反を避けるために、ユーザー自身で十分に調査を行うことを強く推奨します。
推奨ラベリング:
ストリーミングプラットフォームにアップロードしたり、公に共有する際は、「AI生成」「YuE生成」「AI支援」「AI補助」などのラベルを付けることを推奨します。これにより、創作プロセスについての透明性を保つことができます。
責任免除:
私たちは、このモデルの誤用に対して責任を負いません(違法行為、悪意のある行為、不道徳な行為などを含む)。 ユーザーは、YuEモデルを使用して生成したコンテンツおよびその使用に起因する結果に対して全責任を負います。 このモデルを使用することで、生成されたコンテンツに関する適用されるすべての法律および規制を遵守することを理解し、同意したことになります。
また、生成AI出力サービスのFALで利用可能(有料)となっています。1ドルで20回の生成が可能らしいです。
Replicateでも同様の出力サービスを始めています。
パラメータを調整して、1分48秒の曲を作ってみました。生成にはおよそ26分。