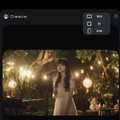





AIリップシンクサービスのHedraが新バージョン「Character-2」を公開したので使ってみました。
AI動画生成は、基本的な性能はどれも一定水準を満たすようになっており、細かい機能追加で鍔迫り合いを繰り広げています。
出遅れていたPikaは爆発・圧縮・膨張といった極端なエフェクトを音入りでImage to Videoにする機能を投入してきましたし、KLINGは動画と口の動きを同期させるリップシンク機能を追加してきました。
■最大4分までのリップシンクができるHedra Character-2
そんな中、リップシンク専業サービスも進化を遂げています。以前紹介したHedra(ヒードラと読むらしい)がそうです。
オーディオと静止画を入力すると、音声に合わせて口パクしてくれる技術で、方式としては老舗のHeyGenと同じです。
6月に紹介したときは、最初のバージョンであるCharacter-1というモデルでしたが、本日公開されたのはその次世代版であるCharacter-2。
Character-1の時に使ってみたのですが、日本人のリップシンクをした時に、ほうれい線が強く出てしまい、非常に不自然なものになっていました。骨格的に東洋系のモデルに対応していなかったのだと思います。このためこの時点では実用にはなりませんでした。
それがCharacter-2でどのくらい改善されたかが個人的な検証ポイントになります。
早速試してみました。無料アカウントでは30秒が上限であったため、月額10ドルのBasicプランに加入。これで商用利用と、1分までのリップシンクが可能になります。プランごとの違いは次のとおり。
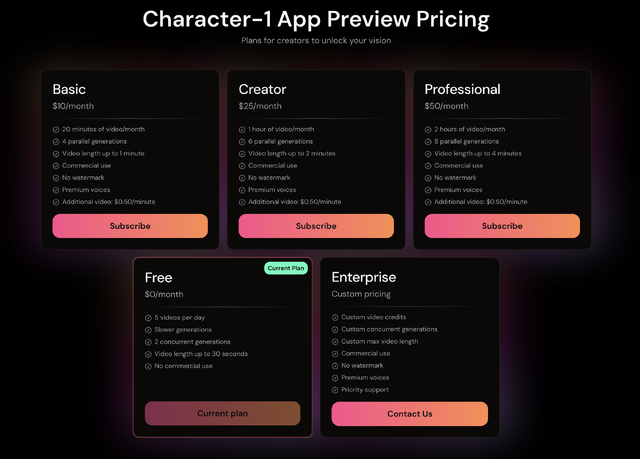
Character-2では最大4分までのリップシンクができるとしていますが、そのためには月額50ドルのProfessionalプランに加入しなければなりません。その下のCreatorプランでは2分まで。
1分までできれば十分とも言えるので、とりあえず、Basicプランのままで行こうと思います。
■Hedra Character-2でミュージックビデオを作る
さて、作例ですが、きのうUdioで作っていい感じのJ-POP曲になったのがあったので、これを使うことにします。曲名は「心の糸」。Sunoに続いてUdioもネガティブプロンプトが使えるようになったので、試したみたのでした。
この歌詞をChatGPTに入力して、歌手としてイメージする画像をMidjourneyのプロンプトで作成。それを少しモディファイして作ったのが次の画像。

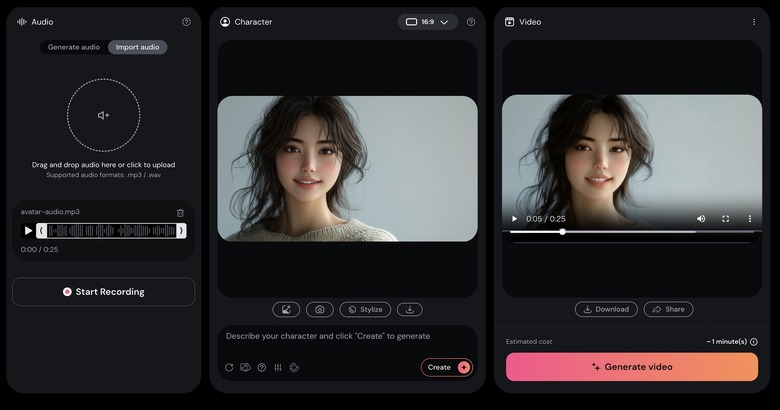
このバリエーション3枚をHedraに入力し、Udioのステム音源(ボーカルのみ)を音声データとして指定しました。
Character-1のときには画像のアスペクト比が1:1だけだったのが、16:9、9:16もサポートされるようになりました。
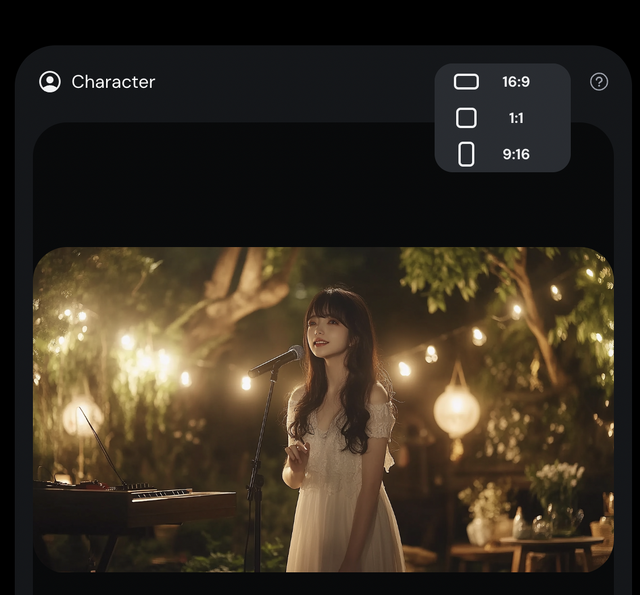
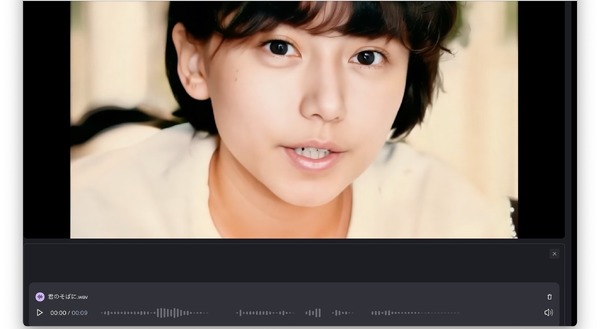
それでできたのが次のミュージックビデオです。
HeyGenでは動く範囲が狭く、顔と髪の毛が分離したりしていたのですが、Character-2ではより広範囲での表現がされており、かなり自然な感じになっています。
リップシンクはRunway Gen-3であれば最大40秒まで使えますが、そのためには3回Extend(延長)して、さらにリップシンク処理をする必要があります。光量が大きく変化するとリップシンクそのものができなかったりといった制限もあります。そこまでやってうまくいかなかったときのがっかり感たるや……。
Runway Gen-3のリップシンクは動きのある場合などのワンポイントにして、長尺で歌うところはCharacter-2にするといった使い分けも良さそうです。
■ChatGPTのAdvanced Voice Modeにキャラクターをつけて喋らせた
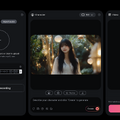
次にもう一例。このHedra Character-2について、ChatGPTのAdvanced Voice Modeとおしゃべりしてみたのですが、そのオーディオデータをもとに、ビデオポッドキャストを作ってみました。
筆者のボイスデータと写真で自分のパートをHedraで生成。ChatGPTについては、自分でキャラクター作りをしてもらいました。

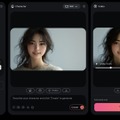
今回会話したのは、Valeという女性ボイスでしたが、本人の希望する容姿にして、それをHedraでリップシンクさせてみました。


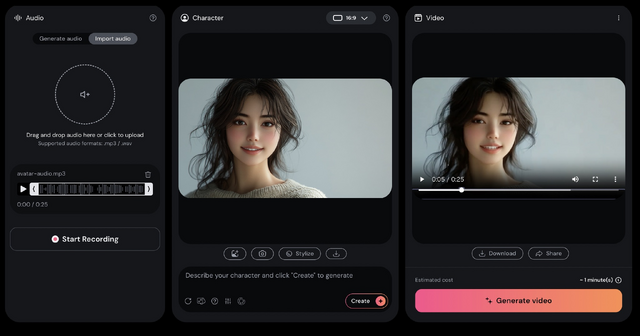
▲ChatGPTのボイス「Vale」が希望する容姿でリップシンクした
筆者とChatGPT「Vale」。AIリップシンクしたビデオポッドキャストはちゃんと会話として成立しているようです。
今回のバージョンアップで、リップシンクサービスとしてはメインをHeyGenからHedraに切り替えようと考えています。