


この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第92回)では、ByteDanceが発表した2つのモデル、動画生成AI「Seaweed-7B」とGPT-4o超えという画像生成AI「Seedream 3.0」を取り上げます。
また、1分くらいの長い生成映像でも一貫性を保つように強化するAIツール「FramePack」をご紹介します。さらにAIと人間の声が区別できるかを実験した研究に注目します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、さまざまな最先端AIモデルに「逆転裁判」をプレイさせて推理能力を調査した研究を単体記事で掘り下げています。
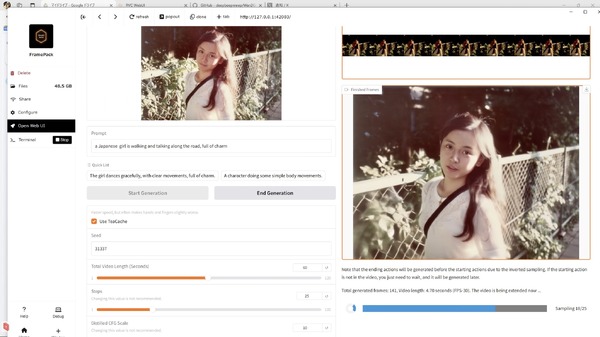
“長時間の映像でも破綻しにくくする”動画生成AI向け強化技術「FramePack」をスタンフォード大学が開発
スタンフォード大学の研究チームが開発した「FramePack」は、映像を生成する動画生成AI向け強化技術です。既存の動画生成モデルに適用することで、計算負荷を増やすことなく長時間でも品質の劣化が少ない動画生成を可能にします。
FramePackは動画生成AIの次フレーム予測に関する2つの主要な課題である、「忘却」(Forgetting)と「ドリフト」(Drifting)を解決する技術です。
「忘却」とは、モデルが以前のコンテンツを記憶し、一貫した時間的依存関係を維持することが困難になる記憶の減衰を指します。一方、「ドリフト」とは、時間の経過とともにエラーが蓄積することによる視覚品質の段階的な劣化を指します。
これらの問題を同時に解決しようとするとジレンマが生じます。記憶を強化して忘却を緩和する方法は、エラーの蓄積と伝播を加速させ、ドリフトを悪化させる可能性があります。逆に、エラーの伝播を遮断し時間的依存関係を弱めることでドリフトを軽減する方法は、忘却を悪化させる可能性があります。このトレードオフが次フレーム予測モデルの進化を妨げています。
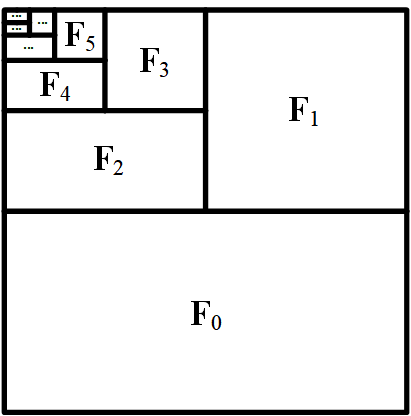
FramePackはこの両方の問題に対応するため、入力フレームの重要度に基づいて圧縮する手法を採用しています。最新のフレームなど重要なフレームは最小限の圧縮に留め、重要度の低いフレームには高い圧縮率を適用します。この仕組みにより、動画の長さに関係なく、処理に必要なメモリ容量を一定に保つことができます。
またドリフトを解決する方法も開発しました。通常の動画生成では前から順にフレームを作成していきますが、この方法では最初と最後のフレームを先に生成してから中間を埋めていくか、あるいは逆順でフレームを生成します。特に、最初のフレームが高品質の場合、それに近づくように逆順で生成すると全体的な品質が向上することがわかりました。これによりエラーの伝播を防ぎます。
実験では、HunyuanVideoやWanなどの既存の動画生成モデルにFramePackを適用(ファインチューニング)し、画質の明瞭さ、美的品質、動きの滑らかさなど複数の指標で評価した結果、優れた性能を示しました。
実際の結果として、RTX 3060 6GBのノートパソコンを使用して、13Bのモデルにより30fps・150フレーム(5秒)の動画や、さらに1800フレーム(60秒)もの長い動画が生成されています。また、RTX 4090では1フレームあたり1.5~2.5秒で生成できるとのことです。


Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
Lvmin Zhang, Maneesh Agrawala
Project | Paper | GitHub
大規模な計算リソースに頼らない動画生成AI「Seaweed-7B」をByteDanceが開発
従来の動画生成モデルは大量のGPUリソースを必要とすることが一般的です。例えばMovieGenは6000台以上のNVIDIA H100 GPUを使用しています。このような高い要求は、動画生成モデルのイノベーションを妨げる可能性があります。
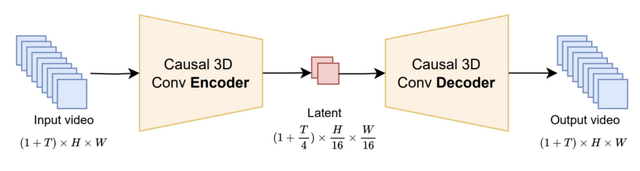
ByteDanceが開発した「Seaweed-7B」は、限られた計算資源で効率的に訓練された動画生成モデルです。
約70億のパラメータを持つこの中規模モデルは、66万5000 H100 GPU時間という比較的少ない計算リソースで訓練されたにもかかわらず、より大規模なモデルと同等以上の性能を発揮しています。
Seaweed-7Bの特徴として、高品質なビデオデータのキュレーション、効率的な変分オートエンコーダ(VAE)の設計、最適化された拡散トランスフォーマー(DiT)アーキテクチャが挙げられます。
評価では画像から動画への生成タスクでSora、Veo 2.0などの有力モデルを上回り、テキストから動画への生成でもトップクラスの性能を示しています。特筆すべきは、14Bパラメータを持つWan 2.1と比較して62倍速く動作しながら、より優れた生成品質を実現している点です。




Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Team Seawead, Ceyuan Yang, Zhijie Lin, Yang Zhao, Shanchuan Lin, Zhibei Ma, Haoyuan Guo, Hao Chen, Lu Qi, Sen Wang, Feng Cheng, Feilong Zuo Xuejiao Zeng, Ziyan Yang, Fangyuan Kong, Zhiwu Qing, Fei Xiao, Meng Wei, Tuyen Hoang, Siyu Zhang, Peihao Zhu, Qi Zhao, Jiangqiao Yan, Liangke Gui, Sheng Bi, Jiashi Li, Yuxi Ren, Rui Wang, Huixia Li, Xuefeng Xiao, Shu Liu, Feng Ling, Heng Zhang, Houmin Wei, Huafeng Kuang, Jerry Duncan, Junda Zhang, Junru Zheng, Li Sun, Manlin Zhang, Renfei Sun, Xiaobin Zhuang, Xiaojie Li, Xin Xia, Xuyan Chi, Yanghua Peng, Yuping Wang, Yuxuan Wang, Zhongkai Zhao, Zhuo Chen, Zuquan Song, Zhenheng Yang, Jiashi Feng, Jianchao Yang, Lu Jiang
Project | Paper
GPT-4o超えうたうByteDanceの新作画像生成AI「Seedream 3.0」、3秒で1K画像を生成
ByteDanceが開発した画像生成AI「Seedream 3.0」は、前バージョンのSeedream 2.0が抱えていた複雑な指示への対応、細かい文字生成、視覚的な美しさ、画像解像度の制限といった課題を解決するために開発されました。
データ処理面では、画像の欠陥(透かしやモザイクなど)を検出して学習から除外するシステムと、視覚的特徴と意味的内容の両方を考慮したデータ収集法により、学習データを増やしました。
また異なる解像度での同時学習や、テキストと画像の情報を統合的に処理する手法を導入し、指示と生成画像の一致精度を向上させています。さらに、AIが画像を生成する過程で重要な処理ステップを効率的に選択する技術により、画質を落とさずに処理速度を4~8倍に向上させました。3秒で1K画像を生成します。
Seedream 3.0の主な改善点は、全体的な能力向上、特に中国語や英語の細かい文字生成の精度向上、高い審美性、そして最大2K解像度のネイティブ出力対応です。特にテキストレンダリングでは中国語テキストの可用性が16%向上し、英語・中国語ともに94%の精度を達成しています。
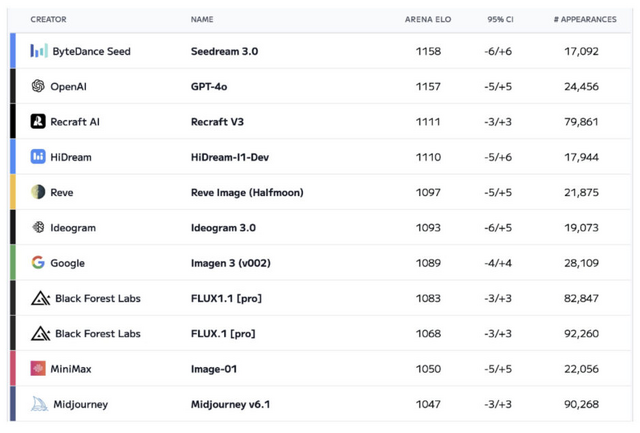
評価結果では、GPT-4oをわずかに上回り、Recraft V3、HiDream、Reve Image、Imagen 3(v002)、FLUX1.1 Pro、Midjourney v6.1などの他のモデルを凌駕し、Artificial Analysis Arenaの総合評価で首位を獲得しました。







Seedream 3.0 Technical Report
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, Wei Liu, Yichun Shi, Shiqi Sun, Yu Tian, Zhi Tian, Peng Wang, Rui Wang, Xuanda Wang, Xun Wang, Ye Wang, Guofeng Wu, Jie Wu, Xin Xia, Xuefeng Xiao, Zhonghua Zhai, Xinyu Zhang, Qi Zhang, Yuwei Zhang, Shijia Zhao, Jianchao Yang, Weilin Huang
Project | Paper
あなたはAIと人間の声を区別できますか? DeepSpeak生成の音声で600人以上を対象に実験
AI音声技術の急速な発展により、人間が本物の声とAIによる音声クローンを区別することがますます困難になっています。選挙妨害や金融詐欺など、深刻な問題も発生しています。
UCバークレーの研究者らは、220人の話者から録音されたDeepSpeakデータセットを使用し、604人が聞いて区別できるかを調査しました。
各話者の音声クローンは、ElevenLabsのInstant Voice Cloning APIを使用して生成されました。これはバイデン偽ロボコールでも使用されたのと同じ技術です。
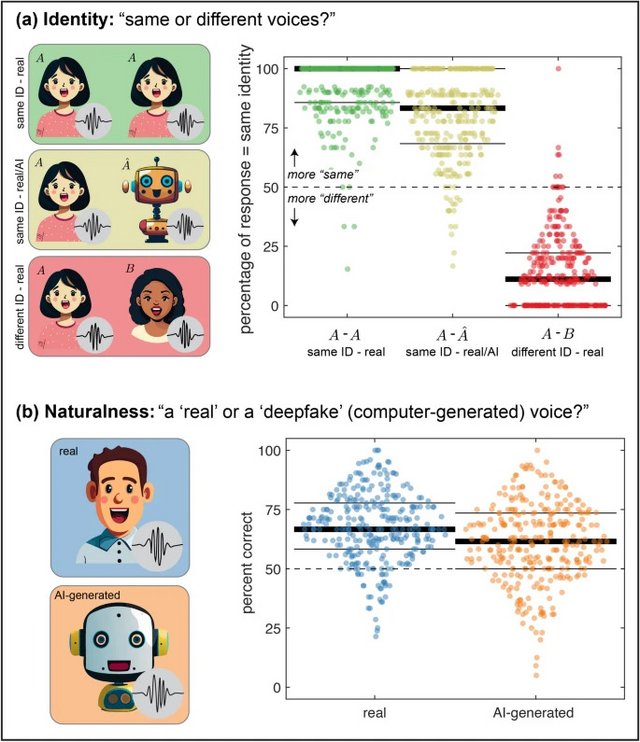
研究チームは2種類の実験を行いました。1つ目の実験では、参加者304人が2つの音声を連続して聞き、それらが同じ人物からのものかどうかを判断するよう求められました。
結果は、実際の同一人物の音声を聞いたとき、参加者は正確にそれを同一人物と判断できましたが、実際の音声とそのAIクローンを聞いた場合、参加者の約80%が同じ人物の声だと判断してしまいました。これはAI音声クローンが非常に説得力を持つことを示しています。
2つ目の実験では、参加者300人が1つの音声を聞き、それが実際の人間のものかAI生成かを分類するよう求められました。参加者は実際の人間の音声を67.4%の正確さで本物と判断し、AI生成音声を60.8%の正確さでAI生成と判断しました。どちらも単なる偶然(50%)よりは良いものの、この結果は人間がAI生成音声を確実に検出できないことを示しています。
研究では、音声の長さと内容の種類が検出精度に影響することが分かりました。長い音声クリップほど、AIと本物の音声の区別が容易になりました。また、台本に沿った発話よりも、自然な会話形式の方がAI生成か否かの判断が容易でした。この発見は、不審な電話を受けた場合、相手に対して長い、オープンエンドな質問をすることで、音声がAI生成かどうかをより良く判断できる可能性を示唆しています。
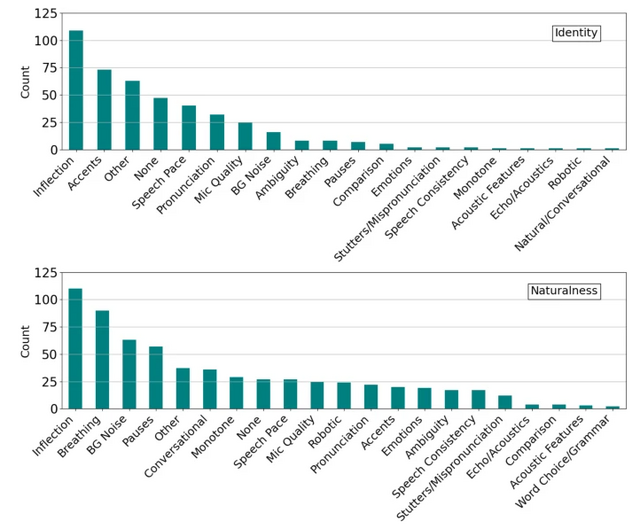
実験後、参加者は音声を区別するために使用した戦略を報告しました。最初の実験では「抑揚」「アクセント」が、後の実験では「抑揚」「呼吸」「背景ノイズ」が最も頻繁に報告された戦略でした。
また、成績上位20%の参加者と下位20%の参加者では使用する戦略に違いがありました。上位の参加者は「スピーチのペース」をより重視する傾向がある一方、下位の参加者は「会話性」を重視していました。これは、呼吸音などの一部の手がかりが誤解を招く可能性がある一方、スピーチのペースやアクセントはAI音声クローンの検出に有効である可能性を示しています。
People are poorly equipped to detect AI-powered voice clones
Sarah Barrington, Emily A. Cooper & Hany Farid
Paper