4月18日に登場した、驚異的な動画生成AI「FramePack」が大きな反響を呼んでいます。
筆者は自宅のWindowsマシンにインストールして以来、RTX 4090 GPUを酷使しながら生成し続けています。今回はその後のお話です。
■FramePackで2分以上のAI動画を生成してみる
Gradioを使ったWeb UIでは、最大2分間の制限がありますが、実は設定を変えることでさらに長時間の一発生成が可能です。こちらも試してみました。
240秒、4分に設定して試したところ、5時間ちょっと……ではなく、12時間43分かかってしまいました。これは、Gradioの設定値をいじったせいなのか、単にマシンに別の負荷がかかっていたせいなのかは不明。
再度検証中ですが、やはり4分間(240秒)設定にすると、最初のフレーム生成の段階ですごく時間がかかっています。ただ、PCを再起動して試したら、そこまで時間はかかっていません。
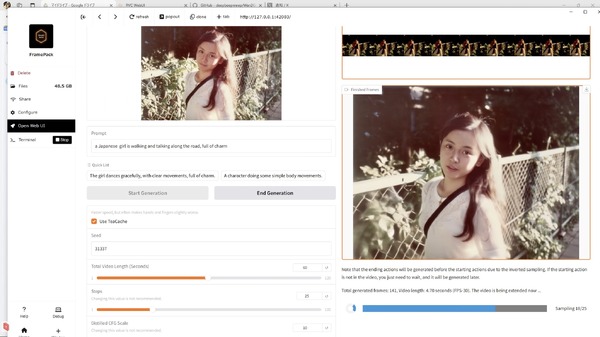
さて、これだけの長さの動画でキャラクターの一貫性は保たれていたでしょうか?
結論からいうと、大きく逸脱することなく、4分間、維持できていたのです。
 |  |
 |  |
FramePackは入力した画像から逆向きに1フレームずつ生成していく仕組みなので、最初に出てくるフレーム(画面左上)が最後の方に生成された画像となります。
手に赤みが移ったり、唇の赤がよりくっきりしたり、全体からグラデーションが薄れ、のっぺりした画像になってしまうといった変化はありますが、本人性は保たれていて、動きも不自然な部分はないように思えます。
作例では、FramePickをRTX 4090で12時間以上回して生成した4分間(240秒)のサイレント動画から、MMAudioでリップシンクの歌入りサウンドを生成しています。MMAudioの処理は1、2分で完了。いくつか試した中で良いものを選びました。
さらにそのボーカルをLogic ProのSTEM Splitterで分離し、Vocoflexで妻音源とりちゃん[AI]の声に置き換えてあります。
発している言葉はまったく意味不明の異世界言語で、奇妙な世界の奇妙な歌に仕上がりました。AIが勝手に作り出した歌っている動画の口の形に合わせて、別のAIが声を作っていったのです。
参考のために、Vocoflex変換する前のバージョンも置いておきましょう。
■なぜ長時間動画生成がうまくいかないのか
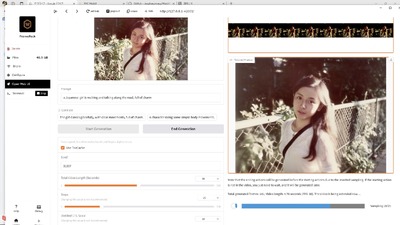
2分間の動画生成も数回試しましたが、ここまでうまくいったわけではありません。
 |  |
 |  |
30秒くらいまではごくわずかな違いですが、1分以上の長さになると、画像が劣化してきます。具体的にはグラデーションの階調が減っていき、派手な色だけが残るようになります。
前面のメインキャラクターよりも背景が壊れがちです。
また、これはFramePack全体に言えるのですが、プロンプトで動きを指定しても、それが動画の長さ全てに反映されるものは少ないのです。例えば、歩く(walking)を指示しても、歩いてくれるのは数秒だけ。あとはほとんど止まっていて、ときどき思い出したように歩き出す、といった具合です。talking、dancing、singingなどは継続して動き続けるのですが、それ以外のどれがうまくいくのかは今のところ情報がまだ少ないのです。
背景のモブキャラはさらに顕著で、普通に歩いているはずの人たちが止まって動かなかったり、動いても後ろ向きに歩き出したり、歩いているように見えても移動していなかったりと、なかなか難しい。これは他の動画生成AIでも見られる現象ではありますが。
その結果、2番目の作例ではオリジナル画像から、背景の歩行者をすべて消去して使いました。それでも背景に映り込んでいる車の劣化は避けられませんでしたが……。
4分動画用のImage to Videoには、背景はできるだけシンプルにした人物のアップ画像を選びました。比較的うまくいったのは、そのおかげではないかと思います。
■AI動画生成は長尺が作れたら終わりではない
4分までの動画が手軽にできるようになり、その過程で気づいたことがあります。それは必要な長さの動画が作れるようになったその次にはストーリーボード、マルチフレームが必要になる、ということです。
そもそもそんな長いロングショット動画、いったい何に使うのでしょうか?
ミュージックビデオのリップシンクやダンス、人間や車、自転車の走行シーンなどは考えられますが、走行シーンやドローントラッキングは、FramePackの現状では難しそうです。
一つのプロンプトだけで動きをつけられるのは、せいぜい数秒から20~30秒くらいまで。それ以上を説得力のあるものにしようとすると、絵コンテや具体的なフレームを数個、置いておく必要があるのです。まあ当たり前のことなんですが。
そうすると、筆者のように動画制作をちゃんと学んでいない人間には大変な困難が待つことになります。
しかし、最近のマルチモーダルなChatGPTやGeminiであれば、こうしたストーリーボードを参照画像を含めて生成できるようにもなるでしょう。
Soraは20秒も本人性を維持できない、今となっては時代遅れのテクノロジーですが、ストーリーボードやマルチフレームといった、必要な機能は備えています。
こうした機能がChatGPTに降りてくれば、最強の動画生成プラットフォームになりうるかもしれません。
実際、ストーリーボードと動画生成を一体化した有償サービスもいくつか登場しています。その一つがSkyReelsです。
SkyReelsは以前使ったことはあったのですが、ストーリーボード機能があるくらいで、基本的な性能はそれほど高くなかった(最長で5秒)ため、そのまま放置していました。
そのSkyReelsで30秒の生成がFirst、Lastフレームで可能になっていたのです。
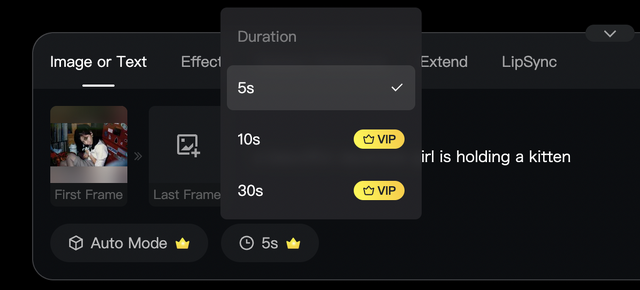
ただし、そのためには現在入っているBasicプランよりさらに上の有償プランに入る必要があります。Standardプランは月額35ドルという、かなり強気な金額。30秒生成は、先週までなら強力な誘引力になったでしょうが、FramePackがある現状、「だから?」となるのは当然です。
ただ、このSkyReelsには面白い点が2つあります。
まず、この運営会社であるシンガポールに本社を置くSkywork AIは、このSkyReels以外に、Murekaという作曲AIのサービスも提供しているという点。
Murekaはこの連載ではまだ取り上げていませんが、SunoやUdioのような、歌詞と音楽スタイルを入力するとボーカルの入った完成曲を生成するサービス。日本語の楽曲にも対応していて、少なくとも日本語の楽曲の完成度についてはSunoに次いで、Udioと戦えるレベルに来ていると思います。Riffusionは生成される曲はいいのですが、日本語の歌詞の発音があやしいのです。
ただ、出来上がった曲のメロディーやアレンジのセンスでいくとまだSunoのレベルには達していないので、筆者はサービスに加入はしたものの本格利用はしていませんし、取り上げる価値もまだないかなあ、というところ。
ですが、このMurekaと動画生成AIのSkyReelsが有機的に結びつくとしたらどうでしょう? ワンストップで歌詞世界を再現するミュージックビデオまでできるとしたら……。
それだけのカードをSkywork AIは握っているということになります。
もう一つの面白い点は、Skywork AIがその独自動画生成技術をオープンソース公開したということ。
近年は、もともとオープンソースAIソフトを出していても、それをビジネスにすると公開を止めてしまうのが一般的となりつつあります。
例えばSunoも、もともとはサウンド生成AIをオープンソース公開していましたが、現在はクローズドとなっています。
■もう一つの「長さ無制限動画生成AI」
Skywork AIが公開したSkyReels V2は、事実上無制限の長さの動画生成が可能だとうたっています。
自社の有償サービスですら30秒までなのに、オープンソースで無制限というのはビジネス的にどうなんでしょうか? 現在はコマンドラインでの処理が必要なので、GradioなどのGUI対応がされたらこの連載でも取り上げたいと思います。
SkyWorks AIは、VLLM、音楽生成といった様々なAI技術を持っているため、これらを使ったワンストップのコンテンツ生成ができるから、プロの方はこっちが楽ですよ、と誘導したいのかもしれません。
多くの企業がこうしたワンストップ型コンテンツ制作サービスへの転換を模索しています。
静止画、動画、音楽、音声対話など個々のAI生成技術を統合してできるようなサービスがこれからは主流となり、個別の技術はローカルPCでもできるようになる。とりあえずはそんな感じでしょうか。


¥540,000
(価格・在庫状況は記事公開時点のものです)