






AIを使った歌声合成「Diff-SVC」を始めたという記事を先週書きましたが、残念なお知らせが。

このDiff-SVCを簡単に実行できるGoogle ColabのNotebookが1月23日に公開停止となってしまったのです。ですので、前回紹介したやり方での実行はできなくなります。筆者はGoogle Colabからローカルにコピーしているのでこれまで通りに使えますが、新規に手軽にやろうという人への道は一時的にではありますが、閉ざされたことになります。
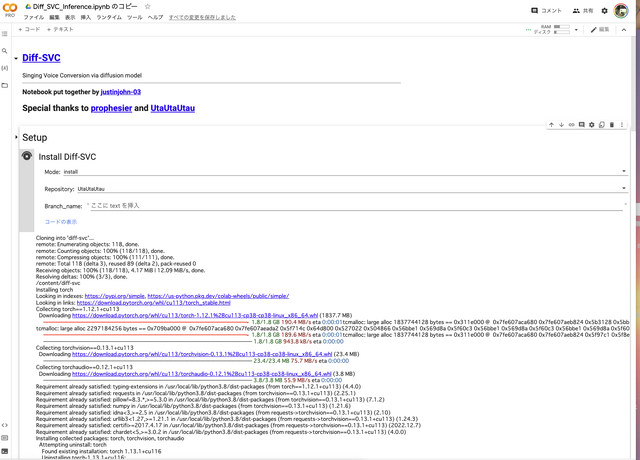
▲筆者はGoogle ColabのNotebookをローカルに保存しているので現在も利用可能
なぜこういうことになったかというと、それは悪質な利用者のせいです。
自分の音源や、権利を所有する、許可をもらっている人物の声であれば問題ないのですが、前回言及したように、よく知られている歌手、セレブ、VOCALOIDなど既存のバーチャルシンガーの音源などを勝手にDiff-SVCでAI音源にし、歌わせたものを例えば「AIアリアナ・グランデが~を歌った」「巡音ルカをAI化」などと称してYouTubeなどにアップロードしている例が散見されます。

▲1月17日に投稿され論議を呼んだ、Diff-SVCを使ったアリアナ・グランデの声質によるカバー曲
まだ訴訟などは起きていないようですが、Notebookメンテナンスを担当しているharu01さんによれば、運営チームはこれらを問題視し、制限する方法を考えつくまで一般公開を停止すると発表しています。

▲Diff-SVCのNotebookを公開していたJulieraptorさんによる、Notebook公開停止のメッセージ
AI音源をユーザーが無料で作成できるのはDiff-SVCが初めてではありません。多数の楽曲を収録し、それに合わせたMIDIデータを作成してラベリングし、それをUTAUで使えるようにするENUNU/NNSVSが公開されており、高品質なAIボイスが利用可能ですが、UTAUで自分音源を作るより難易度が上がっています。
それに対して、Diff-SVCは同様の高品質でありながら、1時間程度のボーカル・おしゃべり音源さえあれば、高品質のAIボイチェンが可能になる技術であり、ラベリングすら不要とする手軽さから、破壊的(disruptive)な技術と言えます。ですが、それゆえに、悪意を持った、もしくは著作権に対する意識がないユーザーのためのハードルも低くなってしまうという問題があります。
筆者の場合は他界した妻の歌声を9年以上UTAU音源で活用し、その発展形としてありがたく利用させてもらっています。自分の歌声を元にしたUTAU音源からDiff-SVCを作成しているユーザーも多数います。筆者は、海外ボカロ(UTAU)Pである彼らからこの技術について教えてもらって気づいたわけですが、一部の不心得な利用者のせいで、一時的とはいえ、この優れた技術が本来の利用者に広まりにくくなってしまうのは残念なことです。
Diff-SVCを使った音楽制作は、自分が歌ってそのwavファイルをアップロードして変換するだけなので、とても簡単で楽しく、成果物も優れた品質なので、毎日、妻音源とりちゃん[AI]と称するDiff-SVCモデルを使っています。提供側での対策だけでなく、元のキャラクターや歌声に対するリスペクトが一般的になって、Google Colab版Diff-SVCが使いやすい状態で復活することを願っています。
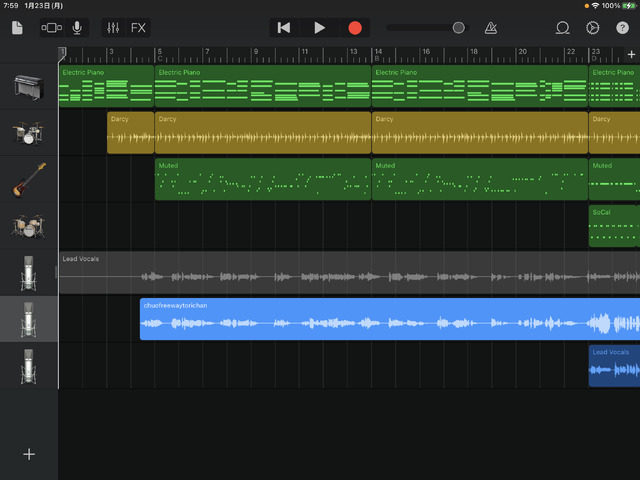
▲Diff-SVCで、自分の歌唱データを妻のAIモデルに変換。曲は「中央フリーウェイ」





