








1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第4回目は、Googleが開発した、昨今の生成AIの根幹をなすTransformerモデルの後継をうたう、マイクロソフトの技術など、5つの論文をまとめました。
生成AI論文ピックアップ
Transformer同等の性能でメモリ効率がよく高速なモデル「RetNet」 Microsoft含む研究者らが開発
昨今の大規模言語モデル(LLM)の基盤アーキテクチャとして活用されている、Googleが開発したモデル「Transformer」は、コンテキストのトークンの関連性を一度に処理するため重たく、特に長い文章ではその欠点が顕著に現れます。
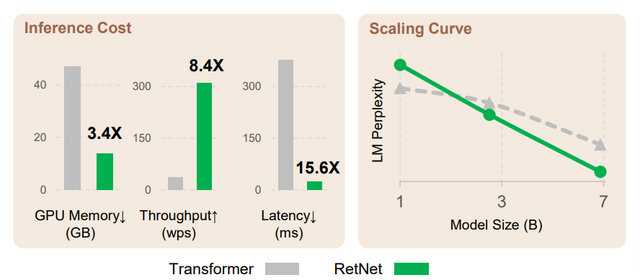
今回マイクロソフトの研究者らが提案したアーキテクチャ「Retentive Network」(RetNet)は、Transformerと比較して学習速度が速く、低遅延であるだけでなく、メモリ効率にも優れ、同等性能以上の精度を示す点でも優位性があります。このようにRetNetは、優れた推論効率と有利な学習並列化による高速化を実現し、競争力のある性能を発揮します。
これらの利点から、論文タイトルで表しているように「Transformerの後継モデル」として理想的だと述べています。
将来的には、モデルサイズと学習ステップの面でRetNetをスケールアップすることを計画しており、またマルチモーダルな大規模言語モデルを学習する際のバックボーン・アーキテクチャとしてRetNetを採用する予定です。さらに、RetNetモデルをモバイル機器などのさまざまなエッジデバイスに展開する意向もあります。
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, Furu Wei
Paper | GitHub
Meta、商用利用可能な大規模言語モデル「Llama 2」発表
米Metaは新しい大規模言語モデル「Llama 2」(Large Language Model Meta AI)を発表しました。これは研究者向け「LLaMA」の後継であり、商用利用が利用規定内であれば可能な形式で一般に公開されました。
ソースコードや重み付けも公開されており、開発者は、Llama 2を基盤としたあらゆる大規模言語モデル(LLM)アプリケーションを構築できます。基本的にはライセンス料など必要なくサーバ代だけで済む低コストでの利用が可能です。ただし、月間7億人以上の大規模商用利用には追加ライセンスが必要です。
Llama 2はGoogleが開発したアーキテクチャ「Transformer」を採用しており、モデルサイズは70億、130億、700億パラメータの3種類があります。700憶パラメータのモデルはGPT-3.5-turbo-0301と同等の性能を示しています。入力の上限は4096トークンとなっています。
Llama 2は公式サイトから直接ダウンロードするだけでなく、Microsoft Azureを介しても利用可能です。AWS、Hugging Face、その他のプロバイダーでも利用できる予定。
著者の数が68人と多く、Metaの意欲が感じられます。
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom
Project Page | Paper
画像内の物体テレポーテーションAI「AnyDoor」 アリババ含む研究者らが開発
この研究は、「AnyDoor」と呼ばれる物体テレポーテーションを行う新しい技術を提案しています。この技術は、シーン画像内のターゲットオブジェクトを、正確で自然な配置で移動させ、周囲の背景と調和させる方法を使ったインペインティング手法です。
具体的に、この技術によって以下の3つのことが可能になります。(1)画像内の物体を指定した位置に移動させること。(2)画像内の複数の物体を入れ替えること。(3)画像に写っていない物体を追加して配置すること。この能力を応用する例としては、バーチャル試着などの実用的なアプリケーションが紹介されています。
従来の方法とは異なり、AnyDoorはゼロショットで高品質なID一貫性のある合成を生成することができます。これを達成するために、IDおよびディテールに関連する特徴でターゲットオブジェクトを表現し、それらを背景シーンと相互作用させて合成します。
具体的には、識別可能なIDトークンを生成するためにID抽出器を使用し、補足としてディテールマップを得るためのディテール抽出器を設計します。IDトークンとディテールマップを、事前に学習させたテキストから画像への拡散モデルに注入します。これにより、AnyDoorは高品質な合成を実現します。


AnyDoor: Zero-shot Object-level Image Customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, Hengshuang Zhao
Project Page | Paper | GitHub
生成AIの処理が高速になる「FlashAttention-2」 米スタンフォード大の研究者が開発
Transformerの入力シーケンス長を拡大することは困難です。なぜなら、Transformerの核心であるAttention層は、入力シーケンスの長さに対して2次関数的な増加で処理時間とメモリの要求が増えるからです。
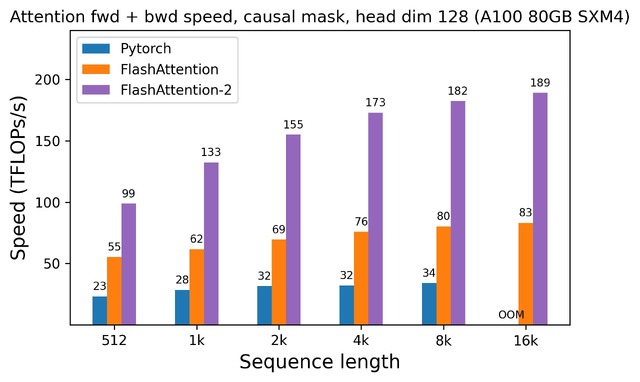
1年前、論文の著者であるTri Dao氏がFlashAttentionをリリースしました。FlashAttentionは、Attentionを高速化し、近似なしでメモリ使用量を削減する新しいアルゴリズムです(2次関数ではなく線形の特性を持っています)。これにより、FlashAttentionはベースラインよりも2-4倍高速になります。
そして、今回、FlashAttentionをさらに改良した次期バージョン「FlashAttention-2」を発表しました。A100 80GB SXM4 GPU上で、さまざまな設定の異なるAttentionメソッドの実行時間を測定しました。その結果、FlashAttention-2はFlashAttentionよりも約2倍高速であることがわかりました。さらに、PyTorchの標準的なAttention実装と比較すると、FlashAttention-2は最大9倍の高速化を実現しました。

FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao
Paper | GitHub
脳活動から音楽を生成するAI「Brain2Music」 Googleや阪大などの研究者らが開発
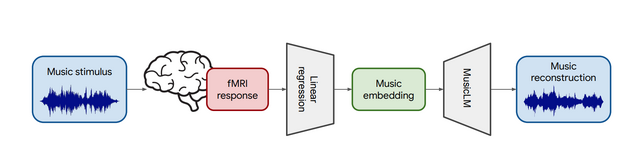
本研究では、音楽を聴いているときに観察される人間の脳活動から音楽を再構成する方法「Brain2Music」を提案します。この手法では、まず機能的磁気共鳴画像法(fMRI)を使って脳活動を取得します。ユーザーがヘッドフォンで音楽を聴いている間に記録されたfMRI信号を活用します。
次に、テキスト記述から音楽を生成できるGoogleの音楽生成モデル「MusicLM」を活用します。研究チームは、人間とMusicLMが同じ音楽を聴くと、MusicLMの内部表現が特定の部位の脳活動と相関することを発見しました。
この知見から、fMRIで得られた脳活動データをMusicLMの入力として活用することで、ユーザーがどのような音楽を聴いたかを予測し、元の音楽に意味レベルで類似した音楽を再構築することが可能となりました。
生成された音楽は、ジャンル、楽器編成、ムードなどの意味的な特性に関して、ユーザーが聴いた音楽に類似していることが確認されました。
Brain2Music: Reconstructing Music from Human Brain Activity
Timo I. Denk, Yu Takagi, Takuya Matsuyama, Andrea Agostinelli, Tomoya Nakai, Christian Frank, Shinji Nishimoto
Project Page | Paper


