









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第22回目は、AIが不得意とする指の数を修正する技術やStability AIの動画生成モデルなど、生成AI最新論文の概要5つをお届けします。
生成AI論文ピックアップ
人間が話すような音声合成でテキストを読み上げるTTSモデル「StyleTTS 2」 コロンビア大の研究者ら開発
新型のText-to-Speech(TTS)モデル「StyleTTS 2」は、先行する「StyleTTS」を基にしており、より人間らしい音声合成を目指しています。
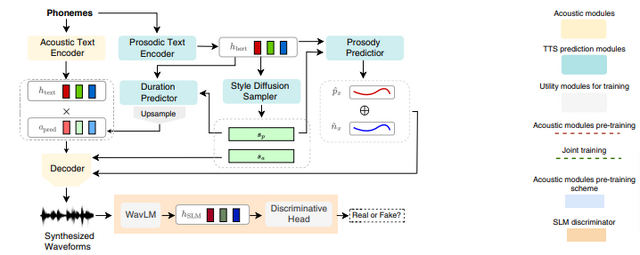
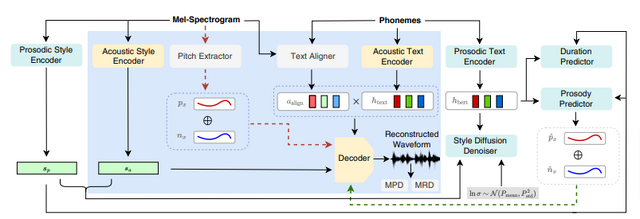
StyleTTS 2は、音声のスタイルを選択するための拡散モデルと、大規模音声言語モデル(Large Speech Language Model、SLM)を組み合わせた敵対的トレーニングを採用しています。これにより、参照音声がなくても、テキストに適したスタイルの音声を自動で生成でき、多様な音声タイプに対応します。
さらに、Wav2Vec 2.0、HuBERT、WavLMなどの大規模な事前訓練済みSLMが使用されており、これらの組み合わせにより、合成された音声の自然さが向上し、より人間らしさが実現されています。
StyleTTS 2によって生成された音声の評価結果は以下の通りです。LJSpeechデータセットでは、ネイティブ英語話者による評価で人間の録音を上回るスコアを獲得しました。また、VCTKデータセットでは、自然さと参照話者との類似性の両方で人間レベルのパフォーマンスを示しました。
さらに、最先端の技術である「NaturalSpeech」と比較して、より高いスコアを達成しました。LibriTTSデータセットでのトレーニングでは、以前の公開モデルを超える自然さを示し、少ないデータ量で高い成果を達成しました。
StyleTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, Nima Mesgarani
Project | Paper | GitHub | Demo
Stability AI、画像から動画を生成するモデル「Stable Video Diffusion」発表
Stability AIは、画像モデル「Stable Diffusion」を基にしたジェネレーティブビデオの最初の基礎モデル「Stable Video Diffusion」(SVD)をリリースしました。SVDは、画像から短いビデオクリップを生成するために設計された潜在拡散モデルです。
このモデルは、与えられた画像を基に、576×1024の解像度で25フレームのビデオを生成するよう訓練されています。これは、もともと14フレームのビデオを生成するSVDを基にファインチューニングされたものです。
これまでの先行研究は主に層の配置に焦点を当てており、データ選択の影響はあまり調査されていませんでした。しかし、訓練データの分布が生成モデルの性能に重要な影響を与えることは明らかです。SVDでは、ビデオ生成モデルの訓練においてデータ選択の重要性に焦点を当てています。
SVDを開発するために、膨大なビデオデータを精査し、適切なデータセットに整理する新しい手法が提案されました。これにより、多くのノイズを含むビデオコレクションをビデオ生成モデル用のデータセットへと変換することが可能となります。
また、ビデオ生成モデルの訓練を3つの異なるフェーズに分け、それぞれのフェーズがモデルの最終的な性能にどのように影響するかを調べています。
SVDは優れたビデオ表現を生成し、それを利用して最先端の画像からビデオへの合成や、カメラ制御用のLoRAなどのアプリケーションにおけるビデオ生成モデルを微調整します。
さらに、ビデオ生成モデルの多視点微調整に関する研究を行い、SVDが3Dの強い事前情報を持ち、以前の方法に比べて計算コストを大幅に削減しながら多視点合成で良好な成果を達成することが示されています。


Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, Robin Rombach
Project | Paper | GitHub | Hugging Face
画像と動画を同時に扱う大規模視覚言語モデル「Video-LLaVA」 北京大などが開発
視覚言語理解の分野で使われる多くの大規模視覚言語モデル(Large Vision-Language Model、LVLM)は、画像や動画を別々の特徴空間に変換し、その後で大規模言語モデル(LLM)に入力として使用します。しかし、画像と動画を統一的に処理する方法がないため、LLMがこれら異なる形式のデータを適切に理解し組み合わせるのは困難です。
この研究では、画像と動画の両方を同時に扱うことができる新しいモデル「Video-LLaVA」を紹介しています。Video-LLaVAは、画像と動画の表現を統一された視覚的特徴空間に整合させ、視覚データの処理前に整合性を確保する新しい方法を提案しています。
結果として、Video-LLaVAはLLMが画像と動画を同時に理解する能力を大幅に強化します。画像理解に関して、Video-LLaVAはmPLUG-owl7BやInstructBLIP-7Bなどの先進的なLVLMを5つの画像ベンチマークで上回ります。
さらに、より包括的な評価のために4つのベンチマークツールキットを利用し、Video-LLaVA-7BはMMBenchでIDEFICS-80Bを6.4%上回ります。ビデオ理解では、Video-LLaVAはMSVD、MSRVTT、TGIF、ActivityNetのビデオ質問応答データセットでそれぞれ5.8%、9.9%、18.6%、10.1%の成績でVideo-ChatGPTを上回ります。



Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, Li Yuan
Paper | GitHub | Demo
テキストから3Dモデルを生成する新型モデル「LucidDreamer」
テキストから3Dコンテンツ作成における最近の進歩は、主にスコア蒸留サンプリング(SDS)による最適化ベースの3D技術を活用しています。SDSは、拡散モデルからの2D結果を3Dに持ち上げ、画像なしで3Dモデルの訓練を可能にする中核メカニズムとして機能します。
SDSは、3Dモデルによってレンダリングされた画像と、拡散モデルによって生成された擬似グラウンド・トゥルース(Pseudo-GT)を一致させようとします。Pseudo-GTとは、実際の正確なデータではなく、拡散モデルによって生成された推測された画像のことです。そのため、3Dモデルはこれら品質の低いPseudo-GTに基づいて更新され、最終的に平均的で、詳細が不足する過度に滑らかな結果になりがちです。
この研究では、事前に訓練された2D拡散モデルから高忠実度のテクスチャや3D形状を抽出するフレームワーク「LucidDreamer」を提案しています。このフレームワークでは、「Interval Score Matching」(ISM)と呼ばれる新しいアプローチを導入し、上記の問題を解決します。ISMでは、DDIM反転を使用して画像の品質を向上させ、拡散プロセス内の二つのステップ間でマッチングを行うことで再構築エラーを減少させています。
研究では、ISMがSDSよりもはるかにリアルで詳細な3D画像を生成することを示しています。さらに、最近登場した3Dモデリング技術「3D Gaussian Splatting」と組み合わせることで、最先端のアプローチ(Magic3D、Fantasia3D、ProlificDreamerなど)に比べて優れた結果を達成しています。
特筆すべきは、これらの競合他社は多段階のトレーニングを必要とするのに対し、LucidDreamerではそれが不要です。これにより、トレーニングコストを削減し、より単純なトレーニングパイプラインを維持することができます。



LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, Yingcong Chen
Paper | GitHub
他に影響を与えず表情や年齢、指の数などを変更。生成画像を緻密に編集できるツール「Concept Sliders」
「Concept Sliders」は、拡散モデルを使用して生成された画像の特定のコンセプト(変更したい内容)を細かく制御するためのツールです。
簡単なテキスト説明や少数の画像ペアを使って、望まれるコンセプトの方向性を学習させるモジュールを訓練します。これらのモジュールを生成時に利用することで、画像内の特定のコンセプトの強度を調整し、繊細な微調整が可能になります。
例えば、被写体の年齢、化粧、髪の色、表情の変更や、指の本数の調整、天気や季節のスタイル変更などが実現できます。これらの操作は、選択したコンセプト以外への影響を最小限に抑えることができる点が特徴です。
Concept Slidersはモジュール方式で設計されており、複数の変更モジュールを同時に活用することで複雑な画像操作が可能です。研究によれば、50種類以上の異なるモジュールを組み合わせても画像の出力品質が低下しないことが示されています。
Concept Slidersは、訓練済みのモデルに適応して使用します。テストでは、Stable Diffusion XLとStable Diffusion 1.4のモデル上でConcept Slidersの性能が示されました。テキストベースで作成されたモジュールを用いて、関連しない他の要素に影響を与えずに、特定の抽象的なコンセプトを制御できること、また、ユーザーが作成した少量の画像データセットから、テキストでは表現しにくい視覚的なコンセプトを扱えることが示されました。
さらに、提案された手法の能力を示すため、Concept Slidersを用いて、StyleGANで学習した特徴やパターンを拡散モデルに転用することが可能であることも示されています。






Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Rohit Gandikota, Joanna Materzynska, Tingrui Zhou, Antonio Torralba, David Bau
Project | Paper | GitHub






