1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第40回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
顔画像を音声に合わせてアニメーション化させるシステム「AniPortrait」
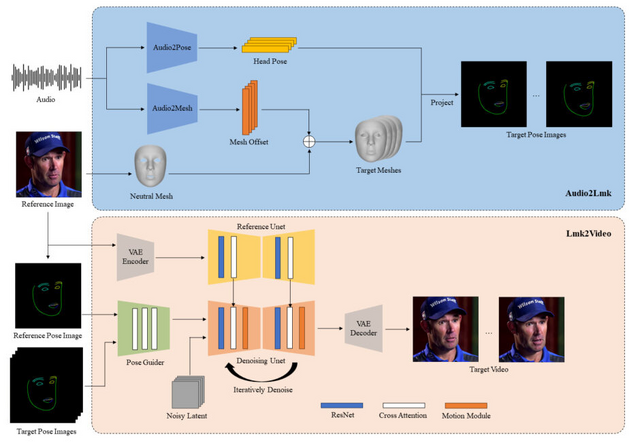
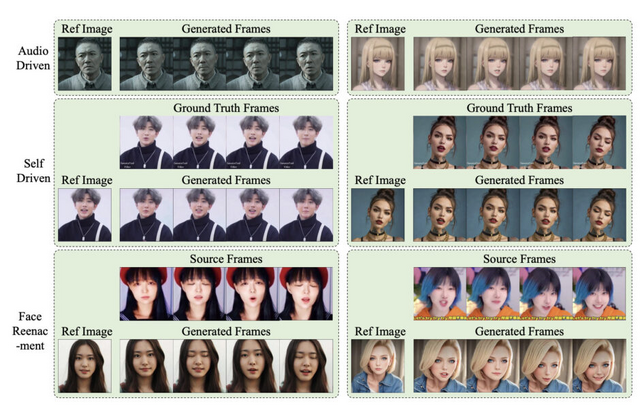
この研究では、音声と顔の静止画像1枚からポートレートアニメーションを生成するフレームワーク「AniPortrait」を提案しています。AniPortraitは、唇の動き、表情、頭の位置を巧みに調整し、視覚的に魅力的なエフェクトを生み出すことができます。
この手法は2つのステージに分かれています。最初に、音声から3Dの中間表現を抽出し、2D顔ランドマークのシーケンスに投影します。次に、ランドマークシーケンスを、モーションモジュールと組み合わせた拡散モデルを使用し、時間的に一貫した写真のようにリアルなポートレートアニメーションに変換します。
実験結果より、AniPortraitは、生成されたアニメーションの顔の自然さ、ポーズの多様性、視覚的品質において優れた性能を示しました。AniPortraitは中間表現として3D表現を利用しているため、柔軟性と制御性の面で大きな可能性を示しています。例えば、ソース画像からランドマークを抽出してIDを変更することで、顔の入れ替えの効果を生成できます。

AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
Huawei Wei, Zejun Yang, Zhisheng Wang
Paper | GitHub
自律型AIエージェントを制御するためのOS「AIOS」
大規模言語モデル(LLM)を用いた知的エージェントの統合と運用には、エージェントの効率的なスケジューリングやリソース割り当て、エージェントとLLM間のインタラクション時のコンテキスト管理、異なる能力を持つ多様なエージェントの統合など、様々な課題があります。
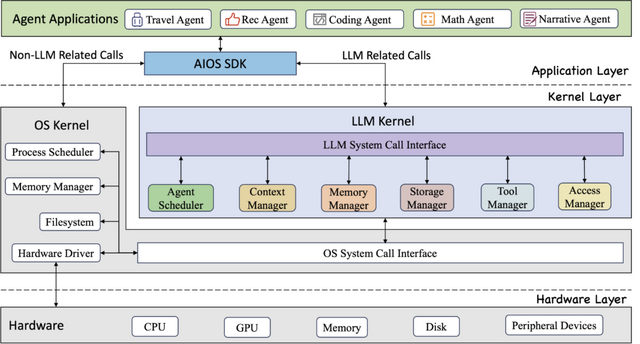
これらの課題を解決するため、研究者らは「AIOS」というLLMエージェントのためのオペレーティングシステム(OS)を提案しました。AIOSでは、エージェントのリクエストを最適にスケジューリングし、LLMの生成状態を保存・復元します。また、エージェントの短期・長期メモリを管理し、外部APIツールの利用をサポートするとともに、エージェント間のアクセス制御を実施します。
このように、AIOSはLLMを基盤とした自律型AIエージェントのための基本的な機能を提供します。複数のエージェントを同時に実行する実験により、AIOSモジュールの信頼性と効率性が実証されています。これにより、エージェントの開発と運用を効率化し、より高度で複雑なタスクに取り組めるようにすることを目指しています。
AIOS: LLM Agent Operating System
Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, Yongfeng Zhang
Paper | GitHub
音声の一部分を別の言葉に変えても不自然にならない音声編集モデル「VoiceCraft」
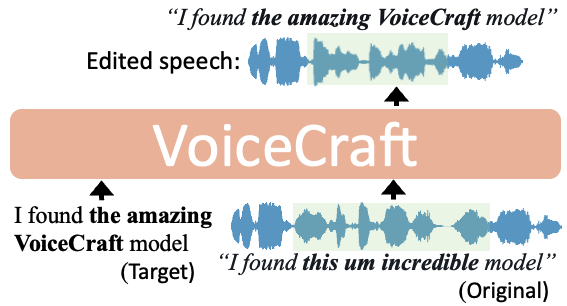
「VoiceCraft」は、オーディオブックや動画、ポッドキャストなど様々な音声データで高い性能を発揮する、音声の編集・合成技術です。音声内容の一部分を別の言葉に変更しても、人間の耳では編集前の音声との違いが区別できないレベルの自然さを実現しています。
例えば、「I found this um incredible model」という音声の一部分を変更して「I found the amazing VoiceCraft model」に変えた場合でも、話し手の特徴を捉えた合成で、あたかも元の話者が話したかのような表現を出力します。
また、事前学習なしで、ある話者の数秒程度の音声サンプルがあれば、その話者の声で任意の文章を読み上げるゼロショットTTS機能も備えています。
研究チームは、多様なアクセント、話し方、録音条件、背景ノイズを含む音声編集用データセット「REALEDIT」を新たに作成しました。
実験において、VoiceCraftは従来の最高性能モデルを大きく上回りました。VoiceCraftで編集された音声と元の音声を人間が聞き比べた結果、VoiceCraftで編集された音声の方が、オリジナルの実際の録音よりも48%の割合で自然であると評価されました。
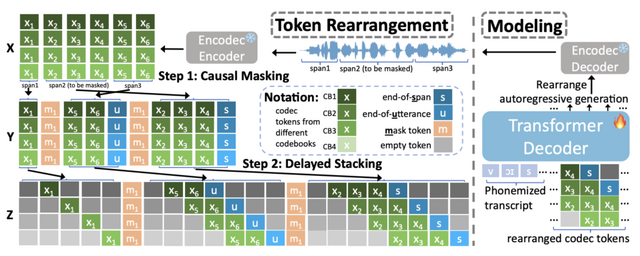
VoiceCraftが音声処理タスクで高い性能を達成できたのは、Causal maskingとDelayed stackingを組み合わせたトークン並べ替え手法を導入したことが大きな要因です。これにより、モデルは既存の音声シーケンス内で効率的に音声を生成できるようになりました。
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Puyuan Peng, Po-Yao Huang, Daniel Li, Abdelrahman Mohamed, David Harwath
Project | Paper | GitHub
LLMが生成した長文をGoogle検索し、内容が事実かどうかを自動で調べてくれるシステム「SAFE」をGoogleなどが開発
大規模言語モデル(LLM)は近年目覚ましい進歩を遂げていますが、長文の事実性に関してはまだ信頼性が足りません。事実を求める質問に対して、事実と矛盾する誤った情報を含む回答を生成することが多いです。
そこでこの研究では、LLMの長文における事実性をベンチマークするための新しいプロンプトセット「LongFact」を提案しています。LongFactは38のトピックにわたる数千の質問で構成されており、GPT-4を使って生成されました。
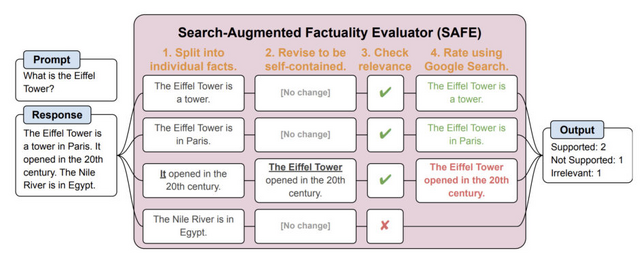
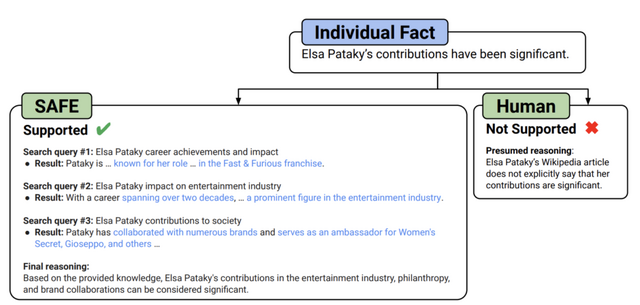
さらに、LLMエージェントを自動評価器として使用し、「Search-Augmented Factuality Evaluator」(SAFE)と呼ばれる方法で長文の事実性を評価することを提案しています。SAFEはLLMを利用して長文の回答を個々の事実に分解し、Google検索を使って事実の正確性を評価します。各事実に対して検索クエリを送信し、検索結果によってその事実がサポートされているかを判断します。
実証的には、SAFEが人間の評価者を上回る性能を発揮することを示しています。約1万6千の個別事実において、SAFEはクラウドソーシングによる人間の評価者と72%一致しました。ランダムに抽出した100件の不一致事例では、SAFEが76%でより正確でした。さらにSAFEは人間の評価者の20倍以上も安価で実行しました。
また、4つのモデルファミリー(Gemini、GPT、Claude、PaLM-2)にわたる13の言語モデルをLongFactでベンチマークした結果、一般的に大規模な言語モデルになるほど長文の事実性が高いことがわかりました。
Long-form factuality in large language models
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, Quoc V. Le
Paper | GitHub
影や反射も考慮し、画像内の物体だけを自然に消す・挿入が可能なシステム「ObjectDrop」をGoogleなどが開発
画像の編集において、物体を画像から除去したり、新たに挿入したりする技術は需要が高まっています。しかし、影や反射など、物体が周囲に及ぼす影響をリアルに再現するのは容易ではありません。
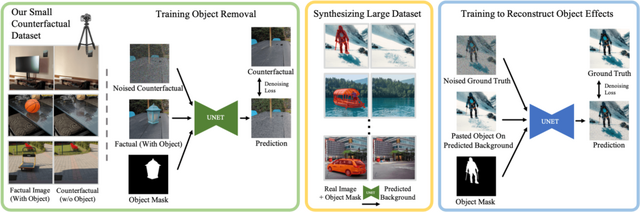
そこで研究チームは、「ObjectDrop」と呼ばれる手法を開発しました。ObjectDropは、画像内の物体だけを消し去り、あたかもなかったかのような自然な仕上がりに合成します。また新たな物体を画像内に挿入し、影や反射も考慮した、調和した合成を可能にします。画像内の物体を少しずらすなどの移動もできます。
この手法の肝は、物体の有無による画像ペアを大量に集めた「Counterfactualデータセット」を用いて学習を行う点です。物体除去については、2,500組の画像ペアを専門の写真家に依頼して撮影。同じ場所で、物体がある状態とない状態の写真を撮ってもらいました。このデータを用いて学習することで、物体の影響を考慮した除去が可能になりました。
一方、物体挿入はさらに難易度が高いタスクです。除去モデルで作成した35万点の合成データを追加で活用することで、わずか2500点の教師データから、影や反射までリアルに再現できるモデルの構築に成功しました。
物体除去・挿入ともに、従来手法を大きく上回る性能を達成。定量的指標とユーザー評価の双方で、ObjectDropの優位性が示されています。