







現役グラビアカメラマンでありエンジニアでもある西川和久氏による生成AIグラビア連載の第26回は、ついにローカルPC上で使えるようになったStable Diffusion 3 Mediumモデルについて。
『生成AIグラビアをグラビアカメラマンが作るとどうなる?連載』記事一覧』
■ ローカルPCで生成可能なStable Diffusion 3 Medium、遂に登場!
連載第22回に、画像生成モデルStable Diffusion 3が「4月17日、Stability AI Developer PlatformのAPI経由で利用可能」と書いた。
それから遅れて約2ヶ月。やっとローカルPCで生成可能なStable Diffusion 3 Medium(以降、SD3 Medium)が6月12日にリリースされた。

API形式の利用だと、コストがかさむのはもちろん、Promptや生成した画像を調べ肌色過多の場合は表示できないという、グラビアを扱う筆者にとって致命的な問題がある(笑)。
SD3 Mediumがリリースされたことで、ようやくSD 1.5やSDXL同様、普通にローカルPCで生成可能になった!ただし、商用利用不可。個人レベルでの商用利用は、クリエイターライセンス($20/月)を契約しなければならない。
なお普通に肌の露出が多い程度はOKだが、いわゆるNSFWな肌色過多は出せない様、意図的にコントロールされている。またこの影響で、ある意味致命的な問題も発生する。この辺りの話は次回にしたいと思う。
SD3 MediumのMediumとは、2B(20億)パラメータでの構成という意味となる。対してAPI版はLargeと呼ばれ8B(80億)パラメータで構成されている。従って、全く同じ設定でも、解釈の度合いが異なるため、同じ出力にはならずMediumの方が劣ってしまうのは残念なところ。
SD3 Mediumの特徴をおさらいすると…。
全体的な品質とフォトリアリズム
プロンプトの理解
テキスト生成
リソース効率
ファインチューニング
をStability AIは挙げている。1は実際生成すると分かるが、ハマると物凄い絵を叩き出す(ハズレもある)。SDXLで十分と思っていたが、これを見てしまうと見劣りするようになってしまった。
2は3つのテキストエンコーダーを搭載したことで、複雑なPromptが理解できるようになり、普通の英文でOKになった。
もちろん従来のタグ区切り、例えばwoman, 20 years old, at cafe的な形で書いても大丈夫だ。
3は、”a yellow camisole with the words 'SD3 Rocks' on it. ”などと書くと、黄色いキャミソールの上にSD3 Rocksと文字が書かれる(日本語はNG)。
4と5は特性上同じことを意味しており、今回は2Bとモデルが小さいため、生成環境はSDXLと同レベルで大丈夫。またFine Tuneなど学習もそれほど大容量のVRAMを必要としない。
中でも一番気になるのはやはり画質。早速SD3 Mediumの絵をご覧いただきたい!
■ 早速生成してみる
まずSD3 Mediumで特徴的な画像を2枚。1枚目は画質や絵柄に注目。SDXLが出た当初はstability.ai社のsd_xl_baseしか無く、肌はツルツル、日本人どころかアジア系/東洋系が出ないなど、いろいろな問題があった。
その後、Fine Tuneされたモデルなどが数多く作られた結果、現在のように不自由なく使えるようになったのだ。少なくともSDXLリリース後、半年近くかかっただろうか?
それがご覧のようにbaseモデルでいきなりこの出来栄え。画質はもちろん日本人風もOK。驚くべき仕上がり具合だ。
 |  |
SD3 Mediumはいきなりこの高画質!日本人もOK
Promptの左右を判断し、加えて指定した文字も書かれている
次は、先に書いた2番目の項目、プロンプトの理解。Promptの一部を抜粋するとこう書かれている。
On the left, there is a young japanese woman her 20s, wearing a red mini dress. On the right, there's a young korean cute woman in her mid-20s wearing a yellow camisole with the words 'SD3 Rocks' on it. She has yellow hair.
つまり左は赤いミニドレス。右は黄色い髪の毛とキャミソール、そして服の上にSD3 Rocksの文字。これが見事に再現さている。
実は従来のSD 1.5とSDXLは、ザックリ上下は理解しても左右は理解出来なかったのだ。
AUTOMATIC1111ではこれを克服するためRegional prompt extensionと言う拡張機能があるのだが、書き方がちょっと面倒で、こんな感じに普通には書けなかった。
また文字もたまに正しく出てくることもあるが、気まぐれ的な状況だった。この二つが一気に解決!先の画質と合わせて嬉しいパワーアップとなっている。
■ 生成環境は執筆時ComfyUI(系)のみ
さて、では生成するのに何が必要か?なのだが、残念ながら執筆時点ではAUTOMATIC1111もFooocusも未対応。ComfyUIのみの対応(ComfyUIをバックエンドに使っていStableSwarmUIなども対応)となる。
この辺りがComfyUIの人気の理由でもあり、単に最新へUpdateすれば自動的にSD3 Medium対応となる。
そしてSD3 Mediumのモデルは以下二箇所でダウンロード可能だ。
Hugging Face
https://huggingface.co/stabilityai/stable-diffusion-3-medium
Civitai
https://civitai.com/models/497255/stable-diffusion-3-sd3?modelVersionId=552771
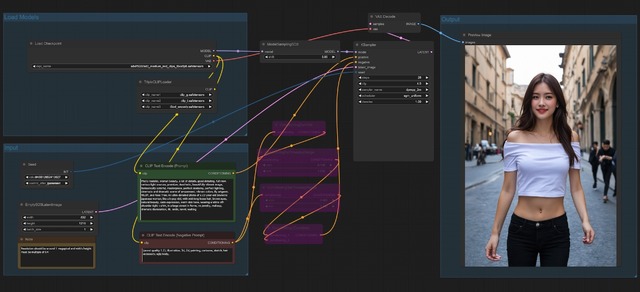
必要なファイルは計4本とWorkflow。Civitaiだとこのようになる。ダウンロードしたSD3 Mediumはmodels/checkpointsへ、他の3本はmodels/clipへ入れれば良い。
SD3 Medium
Text Encoder - Clip L
Text Encoder - Clip G
Text Encoder - T5 XXLFP16 か T5 e4m3fm
そしてWorkflowをセットすると以下のような画面が現れる(モデルはCheckpointとClip3本が1本にまとまっているsd3_medium_incl_clips_t5xxlfp8.safetensorsを使用)。
なお、Workflow中央にある4つのバイパスしたNodeは、Negative Promptを加工している部分なのだが、描写がおかしくなるため使っていない。
もう一つはstability.ai社純正生成アプリのStableSwarmUI。生成速度はSDXLと変わらない感じだ。実は筆者が日頃使っているのはこれだったりする。
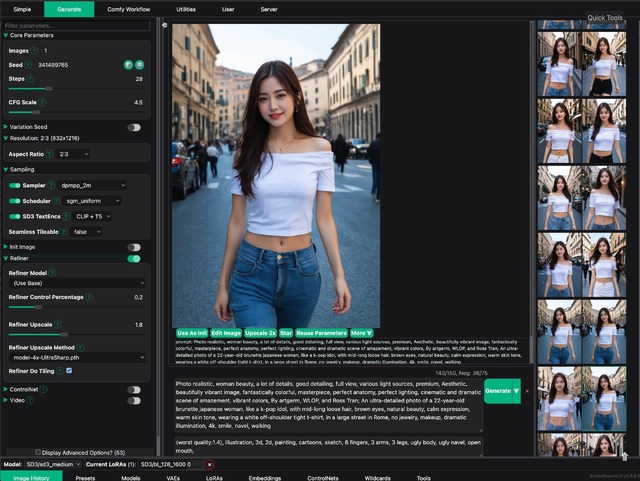
設定でSDXLと違うのはClipの指定があること。CLIP Only、T5 Only、CLIP+T5の3パターンある。通常はCLIP+T5を選択する。
最後にSD3 MediumとSDXL、全く同一設定で比較してみたい。SD3 Mediumは推奨解像度、Step数、CFG数、サンプラーなどSDXLと同じなので何も設定を変えることなく比較可能。
ただサンプラーに関してはSD3 Mediumで使えるものが少なく、SDXLが合わせた格好となっている(dpmpp_2m / sgm_uniform)。他は832x1,216、Steps 28、CFG 4.5。またSDXLに関してはリアル系でいくつか生成し、中でも良いのをピックアップした。
 |  |
SD3 Medium
いかがだろうか?SDXLでも十分綺麗なのだが、SD3を見てしまうと物足りない感じがする。baseモデルでこれだけ出るのだから、今後のFine Tune版に期待が高まる。
■ 今回の締めのグラビア
今回のグラビアはもちろんSD3 Medium(扉の写真も)。ただ純粋なSD3 Mediumではなく、たった数日後に出てきたマージモデルだ。
現在CivitaiにあるSD3 Mediumのマージモデルは2種類あり、一つはSD3用LoRAをSD3 Mediumにマージしたもの。もう一つはSD3 MediumのテキストエンコーダーをSDXL/SD 1.5用に入れ替えたもの。
今回は後者の1つ、wowXLPD_v08Alpha2を使用した。テキストエンコーダーの入れ替えなので、ガラッと絵柄が変わるわけではないのだが、少し変わって面白い。更にSD3 Medium用の試作した顔LoRAを軽く当てている。

本当は口紅を手に持つとかしたいのだが、腕を下ろしているのは苦肉の策。手や指は相変わらずダメ(と言うかSDXLより酷くなっている)。こうしないと、何度ガチャっても使える絵が出てこない。そのままでは面白くないので鏡越しにしてみた(笑)。
次回も引き続きSD3 Mediumの話をしたいと思う。今回書き切れなかったいろいろな情報が山盛りあったりする(つづく)。
入稿後、AUTOMATIC1111はsd3のブランチが出来ていたものの、まだ機能しない様だ。




