
AIリップシンクにまた大きな動きがありました。「sync.」という新顔の登場です。
AI動画四天王、Luma AI Dream Machine、Runway Gen-3 Alpha、KLING、Viduが勢揃いしたことで、動画制作はとても簡単になり、品質も高まりました。いずれも画像から動画を作成できるImage to Videoをサポートし、中でもRunway Gen-3は音と口の動きを同期させるリップシンク機能まで持っています。
日本人のImage to VideoではKLINGとViduの方が相性良いのですが、リップシンク機能を内蔵しているので、筆者が普段やっているミュージックビデオ制作においてはRunway Gen-3をメインにせざるをえません。このためにRunwayの有料プランでのクレジットを使い果たし、10回ほど追加課金をする羽目になってしまいました。
なぜかというと、動画を生成し、その中からリップシンクに使えるものがあれば、さらにリップシンクを生成するからで、10秒の生成には5~10回くらいの試行錯誤が必要だからです。そこで決心して、上限なく使えるUnlimitedプラン(月額1万4000円)に変更したところです。Exploreモードという、ちょっと優先度は落ちるけども追加クレジットなしで無限に生成できるプランです。
そのタイミングで、新しいAIリップシンクサービスを見つけてしまいました。それが「sync.」です。


■sync.はどんな動画でも口パクできる
「sync.」という、きわめてググラビリティの低いサービス名を持つリップシンク。技術自体はwav2clipという名前で2020年から稼働している、この世界では長い歴史を持つのですが、FLUXと組み合わせた作例を見るとかなりいい感じに進化してそうなので、試してみました。

具体的には、これまでのリップシンクがImage to Videoだったのに対し、Video to Videoが可能である点。この一点で価値があります。HeyGen、D-ID、SadTalker、Hedra、Character-1、いずれも元になる静止画を参照してリップシンクできますが、すでにできてしまった動画に、音声だけをリップシンクさせるということはできませんでした。
つまり、顔以外にも動きのあるリップシンクをするのにHeyGenのExpressive AvatarやRunway Gen-3 Alphaに頼る必要がないということです。
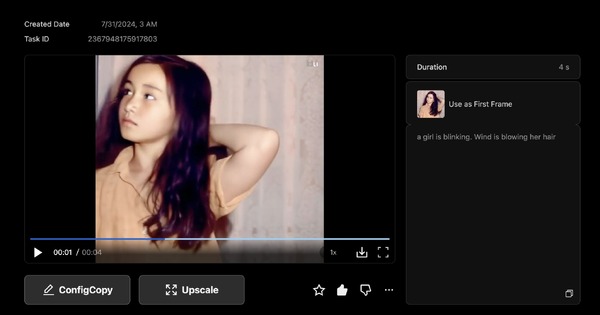
アジア系の人物を動かすのに、Runwayのモデルは最適とは言い難いものでした。日本人の人物画像を参照して「a girl is singing」としても、非常に大げさな動きになり、その結果、途中から欧米人の顔になって同一性を保持できなくという確率が非常に高いのです。そのため、大きな動きにならないように「a girl is talking slowly」といった、動きの少ない指示をして、うまく行ったものだけをリップシンクにしていました。
アジア系のアニメーションだけならば、KLINGとViduが非常に良い動きをつけてくれます。7、8割の確率で同一性も維持できます。
いくつか試してみて、性能的にも問題なさそうだったので、有料プランにしました。無料枠もあります。
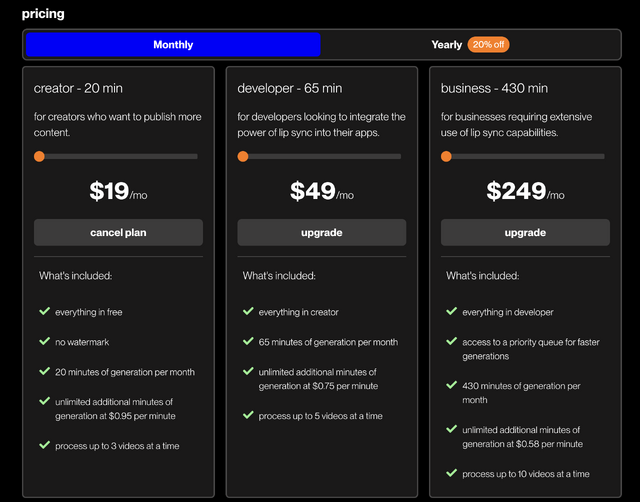
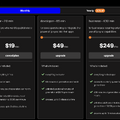
(▲sync.の料金プラン)
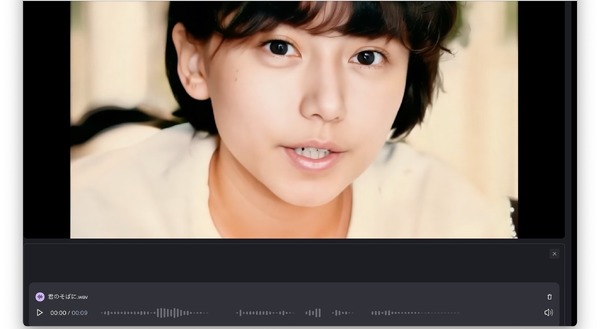
では作例です。元にした動画はGen-3 Alpha、Vidu、KLINGの3種類。中の人物が大きく動いても破綻はほとんどなく、口の動きもかなり忠実にトレースしています。
■これまでのリップシンクの問題点とsync.の改善点
リップシンクではこれまで、HeyGenが最も優秀だったのですが、口を上下に開きすぎ、まだ実験中であるExpressive Photo Avatarでは精度が出ずに、しかも現状ではスクエア画像に限定されるという課題が残っています。
sync.のリップシンクはその辺りがうまく解決されていて、Gen-3 Alpha単独のリップシンクでうまくいかない場合には頼った方が良さそうです。
Viduは8秒まで、KLINGもおそらく昨日から10秒のImage to Video生成が可能になり、Start FrameだけでなくEnd Frameの指定もできるようになりました。
動画生成の選択肢が広がった分、それぞれのサービスの得意・不得意を把握し、複数同時に動画生成して、出来上がったものから良いクリップを選別してリップシンクを施せば良いのです。
もう1つの作例は、Stable Diffusionで生成した1枚の人物写真を起点としてそれぞれの動画生成AIで出力。

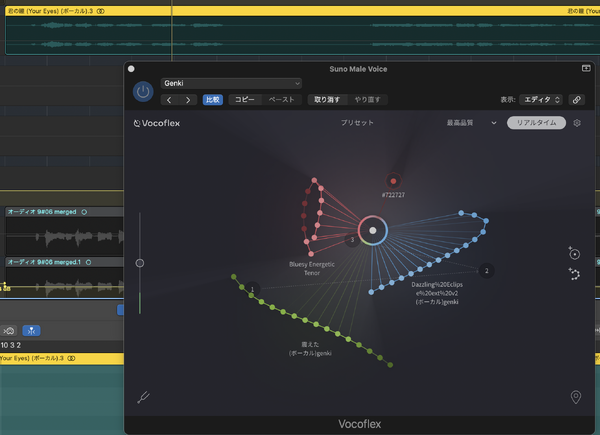
Sunoで作った曲のボーカル(Vocoflexで妻の歌声にボイスチェンジ)とそれぞれの動画クリップをsync.でリップシンクし、繋げたものです。
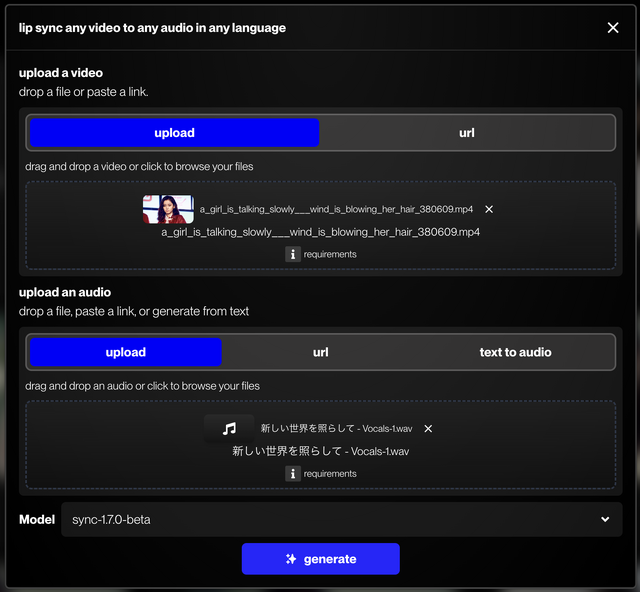
(▲sync.のリップシンクは、動画とオーディオをそれぞれアップロードしてgenerateするだけ)
歌詞の下には、どのような組み合わせでリップシンクしたかを記載しています。
順番としては次のようになっています。
Runway Gen-3 Alpha LipSync:Gen-3 Alphaで生成した10秒のクリップを内蔵機能でリップシンク変換
Runway Gen-3 Alpha + sync.:Gen-3 Alphaで生成した同じクリップをsync.でリップシンク変換
Luma Dream Machine Loop + sync.:Dream Machineのループ機能を使い、長いクリップでのsync.リップシンク変換。動画がループしているのでいくらでも長くできる
KLING + sync.:日本人のImage to VideoはKLINGだと自然。sync.でリップシンク変換
Vidu + sync.:Image to Videoで10秒まで生成できるようになったViduは、動きが大きく、画面の端の方まで攻めていく。sync.でリップシンク変換
いくらでも遊べてしまいます。sync.で生成できる動画の長さに制限はないようなので、動画AIの長時間化でさらに便利になりそうです。
一方で、有料サービスへの支払いは増えるばかりなのです。