


画像生成AI「Midjourney」のWeb版が誰でも使えるようになり、25枚まで無料で画像を生成できるようになりました。
AI開発ベンチャーのIdeogram AIは、テキストから画像を生成する高性能なAIモデル「Ideogram 2.0」を発表しました。Flux ProやDALL-E 3よりも高い評価を得ています。このモデルは現在、ideogram.aiとiOSアプリで無料で利用可能となっています。
イラスト生成AIサービス「NovelAI」の初代画像生成モデル(キュレート版、フル版、ベータ版V1.3)が無料で公開されました。ローカルでモデルを試してみたい場合はダウンロードして使用することができます。商用利用は不可、研究や個人利用に限られます。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第61回)では、AIがAIエージェントを自動設計して改善を続けて進化するシステム「ADAS」や、NVIDIAの長時間動画を理解する「LongVILA」を取り上げます。
また、画像と言語のトランスフォーマーモデルを1つに統合した「Show-o」や、多層パーセプトロンとは異なるニューラルネットワーク「KAN」の科学特化バージョン「KAN 2.0」をご紹介します。最後に、3億枚以上の人間画像データで学習した動く人を高精度に理解するMeta Reality Labsの「Sapiens」を取り上げます。
(生成AIウィークリーの連載記事一覧 | テクノエッジ TechnoEdge)
生成AI論文ピックアップ
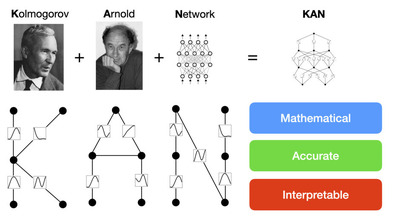
新星ニューラルネットワーク「KAN」の科学分野に特化したバージョン「KAN 2.0」登場
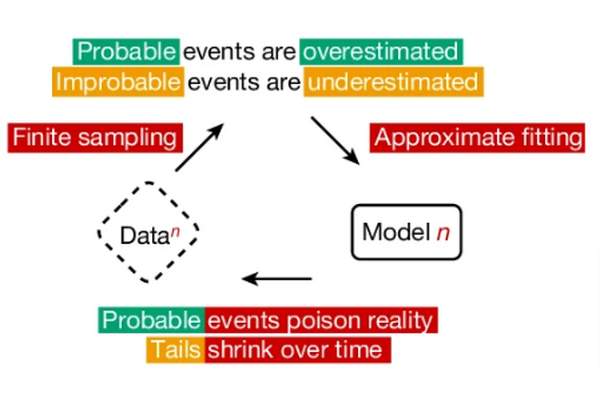
「KAN 2.0」は、「KAN」(Kolmogorov-Arnold Network)を科学分野に活用するためのフレームワークです。KANとは、最近登場したニューラルネットワーク(NN)アーキテクチャで、これまで多用されてきた「MLP」(Multi-Layer Perceptron、多層パーセプトロン)とは異なるアイディアでありながら高性能と期待されている新星です。
KANの特性を簡単にいうと、MLPがノードに固定の活性化関数を持つのとは異なり、KANはエッジに学習可能な活性化関数を特徴としています。
本研究では、そのようなKANと科学的知識を融合させる双方向のアプローチを提案しています。科学からKANへの方向では、既知の科学的知識をKANに組み込む方法を示しています。例えば、重要な特徴量、モジュール構造、数式などの形で科学的知識を表現し、それらをKANの初期構造に反映させます。
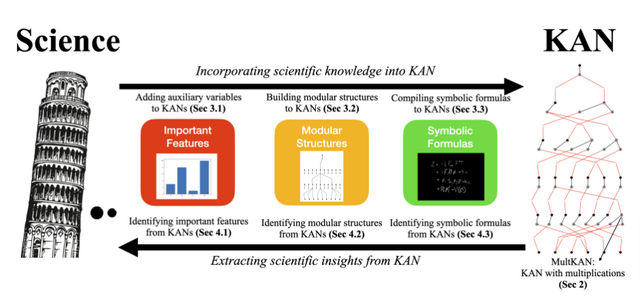
KAN 2.0: Kolmogorov-Arnold Networks Meet Science
Ziming Liu, Pingchuan Ma, Yixuan Wang, Wojciech Matusik, Max Tegmark
Paper | GitHub
画像と言語の理解・生成を1つのトランスフォーマーモデルに統合するAIシステム「Show-o」
「Show-o」は、画像や言語を理解し生成する能力を一つのシステムに統合することを目指しています。従来のマルチモーダルモデルは、画像の理解と生成、テキストの理解と生成といったタスクを別々のモデルで行っていますが、Show-oはこれらを一つのモデルで実現します。
具体的には、テキストを処理する自己回帰モデルと画像を扱う拡散モデルを組み合わせることで、様々な種類の入力データに対応できるようになっています。
Show-oの特徴的な点として、テキストと画像の両方を同じような形式のデータ(離散トークン)として扱うことが挙げられます。また、「オムニ注意機構」と呼ばれる新しい仕組みを導入し、テキストと画像のデータを適切に処理することができます。
学習方法においても工夫がなされており、次のデータを予測する課題とマスクされたデータを復元する課題を組み合わせて学習を行います。さらに、3段階に分けた訓練過程を採用することで、効率的にマルチモーダルなタスクに対応できるようになっています。
Show-oは現在、Phi-1.5モデルをベースにしており、1.3Bのパラメータを持っています。実験結果では、Show-oは画像の理解や生成といったタスクにおいて、同等かそれ以上のサイズの専門モデルと同等以上の性能を示しました。また、画像生成において従来の自己回帰的な方法と比べて約16倍少ないサンプリングステップで済むなど、高速化の可能性も示しています。
さらに、Show-oは画像のインペインティングや拡張、ビデオキーフレームとテキスト説明の生成などの追加タスクもサポートしており、多様なアプリケーションに対応可能です。
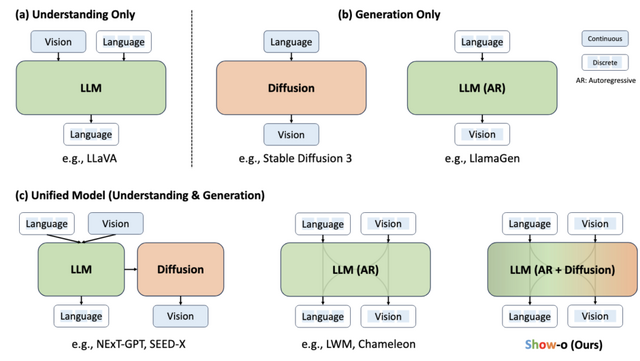


Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou
Paper | GitHub
AIがAIエージェントを改善し続ける自動設計システム「ADAS」
従来、強力な汎用エージェントの開発には、基盤モデルをエージェントシステムのモジュールとして組み込む手動設計が主流でした。本研究では、人間の介入なしにAIによって独創的で強力なAIエージェントシステムの設計を自動化する「ADAS」(Automated Design of Agentic Systems)という新たなアプローチを提案しています。

(自律AIが自律AIを改良し続ける自動設計システム「ADAS」発表。手動設計を大幅に上回る性能 | テクノエッジ TechnoEdge)

長時間動画を理解できる視覚言語モデル「LongVILA」をNVIDIAなどが開発
NVIDIAなどの研究チームが開発した視覚言語モデル「VILA」(Vision-Language Alignment)を基盤とし、長いビデオを理解できる「LongVILA」が新たに開発されました。
VILAは、画像や短い動画の理解に優れた性能を示していましたが、LongVILAはその能力を大幅に拡張し、長時間の動画処理を可能にしました。具体的には、従来の8フレームから256フレームまでの処理能力を実証し、最大1024フレームまで処理可能となりました。
LongVILAの訓練パイプラインは、VILAの設計を踏襲しつつ拡張した5段階で構成されています。マルチモーダルアライメント、大規模事前学習、教師あり微調整という最初の3段階はVILAと同様です。これに加えて、LLMのコンテキスト拡張、そして長い動画での教師あり微調整という2段階を新たに導入しています。特に最後の段階では、新たに開発された並列処理システム「MM-SP」 (Multi-Modal Sequence Parallelism) システムを用いて、効率的に長いコンテキストの学習を行います。
モデルの性能評価では、LongVILAは長いビデオの理解タスクで優れた結果を示しました。VideoMMEベンチマークでは、256フレームを使用して全体スコア50.5を達成しました。長時間ビデオキャプション生成タスクでは、100本の長時間ビデオに対してキャプションを生成し、その正確さ、詳細さ、文脈理解度を評価しました。結果として、8フレームから256フレームに増やすことで、平均スコアが2.00から3.26へと大幅に向上しました。



LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Fuzhao Xue, Yukang Chen, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, Song Han
Paper | GitHub
動く人間を詳細に理解できるMetaのビジョンモデル「Sapiens」、3億枚以上の人間画像データで学習
この研究は、人間中心のビジョンモデルファミリー「Sapiens」について紹介しています。Sapiensは、0.3Bから2Bまで用意されており、2Dポーズ推定、身体パーツのセグメンテーション、深度推定、表面法線予測という4つの基本的な人間中心のビジョンタスクに対応しています。