AIアバターサービスのHeyGenが大きく進化しました。
■HeyGenの新機能
この連載では主に高度なリップシンクができるサービスとしてHeyGenを紹介してきましたが、実はHeyGenの主力は、TTS(Text To Speech)で動画でしゃべらせるAIアバター「Video Avatar」にあります。
実際にカメラで収録した動画を元にAIモデルを構築し、同じくトレーニングしたボイスモデルと合わせて、本人に近い、おしゃべりする動画を作成できるというものです。
ただ、この収録のハードルがなかなか高く、しかもトレーニングはHeyGenに任せて出来上がるまでしばらくかかります。筆者のように、もう収録が不可能な人物でのアバター構築は不可能です。
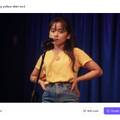
一方、「Photo Avatar」では、顔写真・画像があれば、そこにテキストやオーディオを与えて口パクをさせる、いわゆるリップシンクは可能。筆者がこれまでHeyGenでやっていたリップシンクはこの方法を使っていました。
画像は本物でも、AIで生成したものでもかまいません。ただし、顔の一部しか動かなかったり、髪の毛の動きが不自然だったりと、限界もありました。このため、最近ではHedra、Runway Gen-3といった、新世代のリップシンク機能を使うことが多いです。
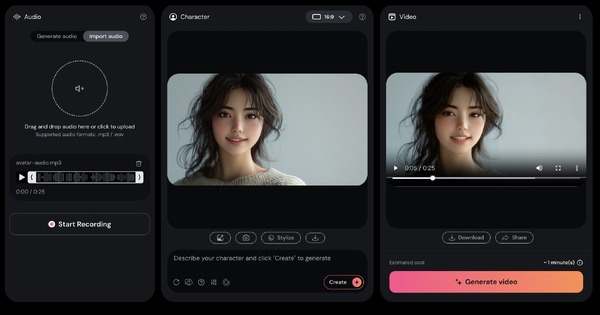
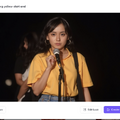
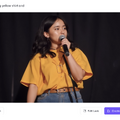
そんなときに登場したのが、Photo Avatarを拡張する新機能。20枚の顔写真があれば、そこからプロンプトで動くアバターを生成し、高精度なおしゃべりができるとしています。
Stable DiffusionやFLUX.1で、Dream BoothやLoRAで学習してAIモデルを構築し、そこから静止画を生成するのと同じように、「動かせるAIモデル」を作れるのです。
■顔写真を20枚集め、学習する
妻の学習用の写真は既に揃っているので、それらを入力してやってみることにしました。
学習に使ったのは21枚。アップロードすると、それらの画像が学習に適しているかどうかをチェックされます。
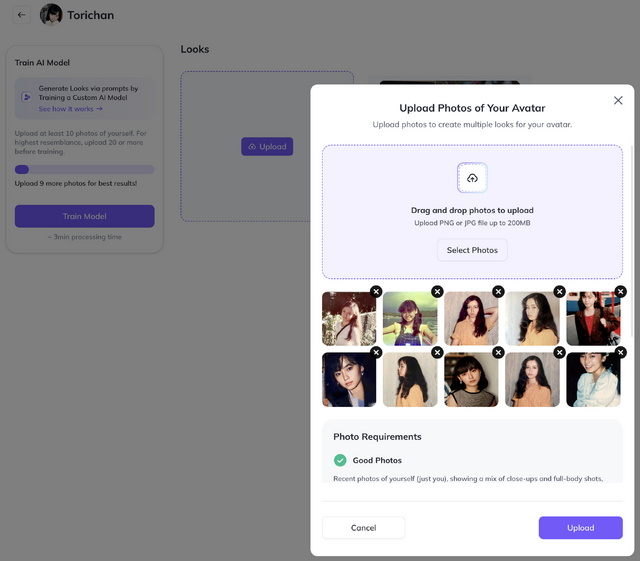

最初は11枚で済ませようとしましたが、「あと9枚追加すれば、より良い結果が期待できます」と教えられたので追加。
学習が終わったら、名前を付けると、AIモデルの出来上がりです。Dream BoothやLoRAのように、ここから無限にその人の画像を生成できます。
やり方は、テキストプロンプトで、「Avatar ~」で指定するだけ。細かい数値設定はなく、画像の縦、横、正方形という指定のみ。
生成された画像はそれぞれなかなかの出来です。ハズレがない感じ。
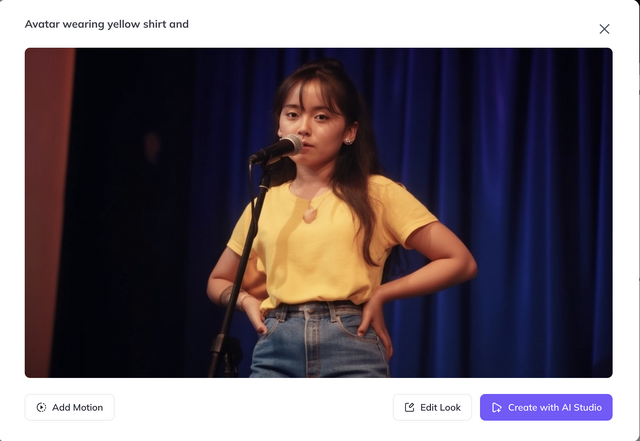
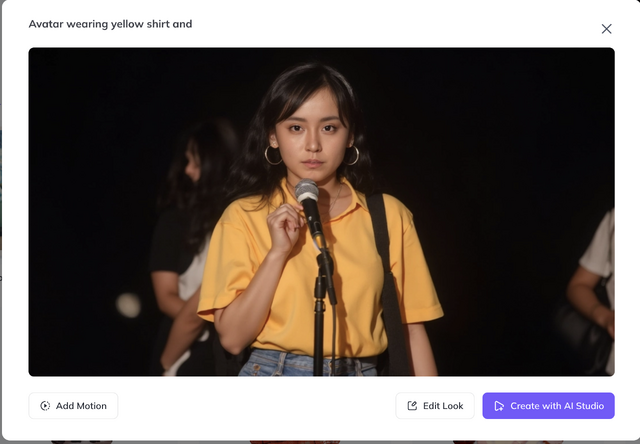
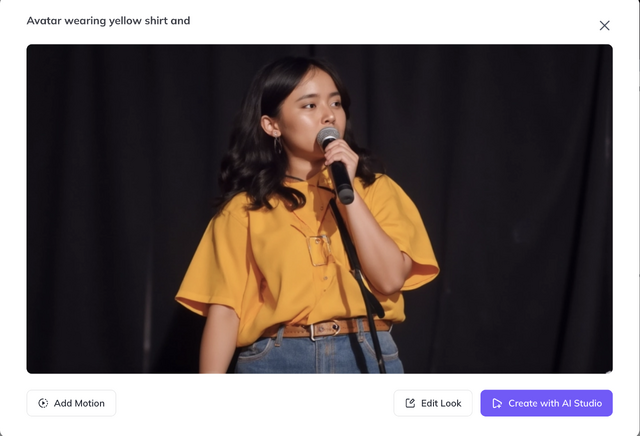
筆者はこれまで、Stable Diffusionとその派生モデルではDream Boothを、FLUX.1 [dev] ではLoRAを使って、妻の画像を生成してきましたが、それらと比べても遜色のないものです。
HeyGenではさらに、ここで生成した画像に喋らせることができます。
例えばRunway Gen-3では、生成した動画に対してリップシンクのための下準備をしてからオーディオデータを与えることで喋らせることが可能ですが、HeyGenではワンストップでその作業ができます。
Suno AIで作った曲のボーカルパートをオーディオデータとして取り込んで歌ってみました。
全体の動きは良いのですが、日本語で「あ」「お」のときに口を大きく開きすぎる傾向があり、ここはなんとかならんかなと思います(Photo Avatarのときからそうでした)。Runwayの方が自然な口の動きになります。
HeyGenとしては、歌わせることは想定しないと思うので、仕方ないことではあります。
プロンプトから衣装、髪型、背景を生成してそのままリップシンクができるというのは超便利なのですが、口の開く程度をパラメータで調整できてほしいですね。
せっかくワンストップでミュージックビデオができると思ったのですが、自然な口パクにするには元のボーカルデータの「あ」「お」を曖昧母音にする必要がありそうで、そこまでしなくちゃいけないとなると、ハードルが上がります。
ここで、もう1つのAIトレーニングができることに気づきました。
声もトレーニングできるのです。いわゆるボイスクローン。ここではTTS、つまり、セリフをテキストで入力すれば、それを本人の声で喋らせることが可能になるのです。
■しゃべり声をクローンする技術の歴史
筆者は妻の歌声を再現するために、Diff-SVC、RVC、Vocoflex、Seed-VCといったボイスチェンジャー機能を使ってきました。これは元の音声があって、声質だけを変更するというやり方です。
テキストデータから本人のような音声を生成できるものとしては、「Open JTalk」というものがあり、2016年に自分の声で試しました。
もっと簡単に使えるものとしては「コエステーション」があり、2018年に実際に試したこともあります。
生成AIの登場以降は、さらに進化しています。
最近では「Fish Speech」という新しいオープンソースのボイスクローンTTSが登場しています。日本語もサポートしているので、使ってみました。イントネーションがかなり変ですが、使えることは使えます。
さて、そんな中、HeyGenのボイスクローンTTSを使う必要性があるかというと、2つポイントがあります。
まず、動画モデルと統合されているので、オーディオデータを解析して反映されるより自然なものになるのではないかという期待。
もう一つは、HeyGenのボイスクローンTTSは、おそらくOpenAIの技術だからです。OpenAIが3月末に「Voice Engine」を発表したとき、アーリーアダプターとして挙げていたのがHeyGenでした。
■HeyGenでボイスクローンしてみた
妻の声で喋ってもらうとして、何を話してもらおうかとしばらく悩みました。本人の声と姿である必然性が要求されるからです。
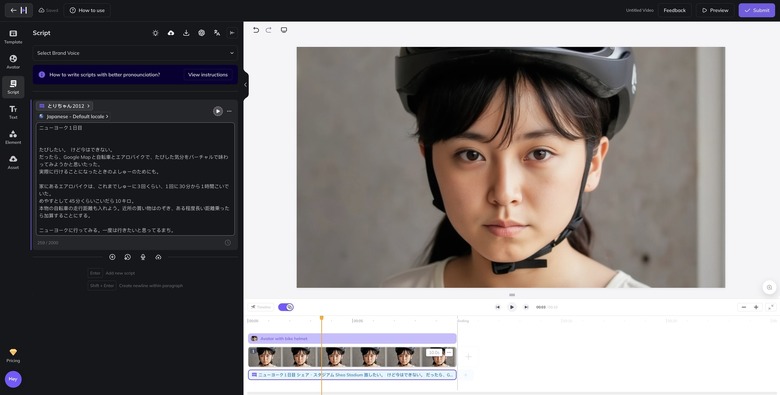
そこで、妻が2006年に短期間書いていたブログ「仮想自転車旅日記」の冒頭部分をしゃべってもらうことにしました。これは、エアロバイクを漕ぎながら、走った距離をいろいろな場所に当てはめて、その土地を走った想像をしながら書いたブログです。今でいう、Zwiftみたいなことを18年前にやっていたわけです。
元のボイスデータとなるしゃべり声は、1988年の8mmビデオから使いました。一定の長さがある、比較的クリアな音声はこのくらいしかなかったからです。
最適なボイスクローンのためには2分間のオーディオデータが必要だそうです。
2012年に、韓国のドキュメンタリー番組に出演したときのビデオから、1分30秒くらいしか集められなかったのですが、とりあえずできました。
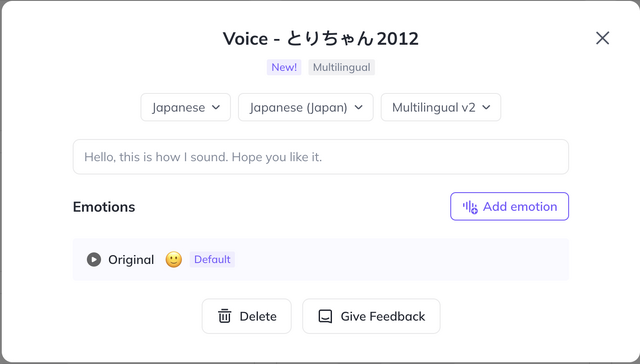
これで、妻の姿と声で、自由におしゃべりしてもらえるようになりました。文章の内容に合わせ、自転車のヘルメットを装着してもらいました。
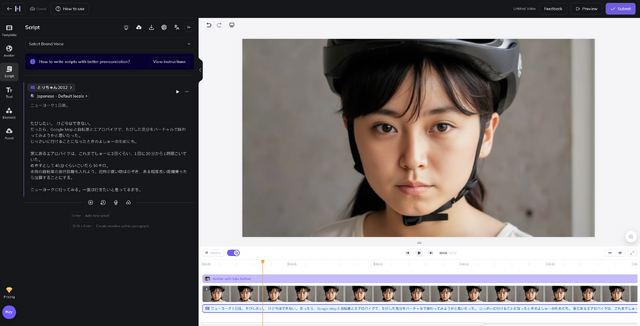
ブログの文章を、読み間違えしないように少しだけ修正し、動画を生成します。
似ているかというと、ちょっと微妙ですが、全体にピッチを少しあげれば近くなる気もします。あと、ヘルメットが動いてしまっているのは仕方ないか。
面白いのは、別の言語に置き換えられるというところ。ここにOpenAIのVoice Engine技術が使われているようです。
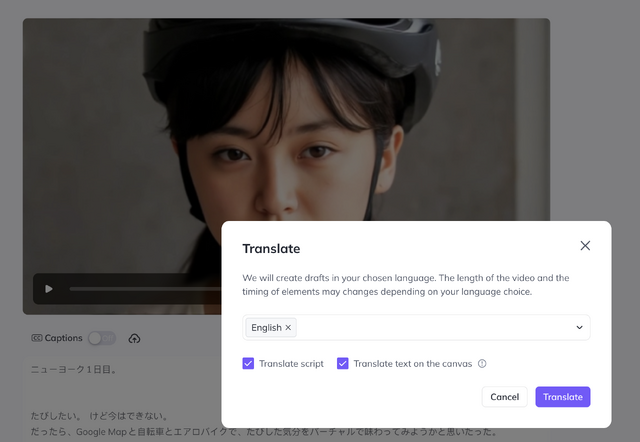
Hedraでも同様のボイスクローンを実装していますが、現在のところ日本語には未対応。
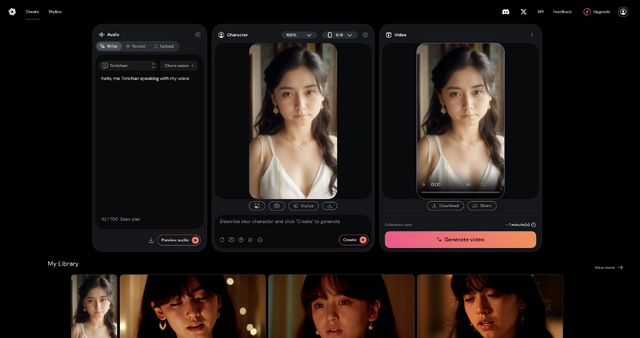
HeyGenではインタラクティブに応答ができる「Interactive Avatar」もベータ版で提供しています。現時点ではカスタマイズはできませんが、AI Photo Avatar、ボイスクローンと組み合わせれば、リアルタイムで対話することも可能になりそうです。
一方で、動画生成AIの方も、ファインチューニングに動いているようです。KLINGは現在、一部ユーザーに、キャラクターの一貫性を持たせる新機能を開放しているようです。
筆者のところにはまだきていませんが、使えるようになったら報告します。