







動画生成AIはわずか1カ月ちょっとで急激な進化を遂げました。この期間の進化を、人物Image to Videoに絞ってまとめてみます。
WWDC24でApple Vision Proの日本での発売とApple Intelligenceが発表された直後の6月中旬、Soraに匹敵するレベルの高精度で、写真から動画を生成するLuma AIのDream Machineが登場したのが始まりでした。

2週間後には2枚の写真の中割りができる機能を実装。アジア系の人物に弱い弱点を補完できる、自然な遷移が可能となりました。


さらにその動画をループさせることも可能になりました。


通常のImage to Videoだと外国人化してしまいがちなDream Machineですが、2枚の中割りやループの場合には本人性をある程度維持した動画になる確率が高くなっています。
■Dream MachineにEnd Frame搭載
Dream Machineはさらに、End Frameという機能を搭載しました。最後の画像だけを指定し、そこに至るまでの5秒間を描画してくれるのです。
使い方はちょっとトリッキーで、Start Frameの画像をまず選び、上の両矢印ボタンでEnd Frameに入れ替えるのです。


ターゲットフレームが決まっている分、より自然な動きができるようです。
これに対して、中国以外では新登場のKLING AIの場合は、現時点では中割り機能やEnd Frameは使えません(予定はされています)が、ベースがアジア系ということで、1枚の写真から動画を生成した際にも自然な変化を見せてくれます。
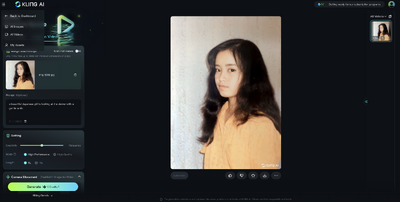
下の作例では正面から横顔に変化していますが、本人の横顔と比較しても違和感がありません。



上の作例でも大袈裟なジェスチャーにならず、自然な仕草と表情となっています。この写真は他のImage to Videoではことごとく失敗していたものですが、非常にうまく動画化しています。
日本人の写真を動画にする場合にはKLINGの優位性が際立っています。現在は無料で毎日6回の生成しかできないので、「早く課金させてくれ!」という気持ちです。
もう一つのSora世代動画生成AI、Runway Gen-3ですが、まだImage to Videoが実装されていないので、これの登場も楽しみです。特にRunwayはGen-2のリップシンク機能がかなりよくできているので、大いに期待しています。
Runway Gen-2のリップシンクは、まず人物写真から動画を生成し、その動画にオーディオを当てはめて動かすというもので、HeyGenなどが顔を固定した状態でしかリップシンクできないのに対し、顔を大きく動かしたり、カメラが移動しながらでも口と音声が同期できるところに特徴があります。Gen-3の精度でImage to Videoでも可能になれば、他では得られないリップシンク動画が生成できるでしょう。

(▲Runway Gen-3ではカメラが移動しながらリップシンクできている)
Gen-3 AlphaでのImage to Videoが一時的に有効になっていたという投稿がいくつかありました。これは期待していいかもしれないですね。
7月30日追記:Runway Gen-3のImage to Videoとリップシンク機能が公開されたので使ってみました。
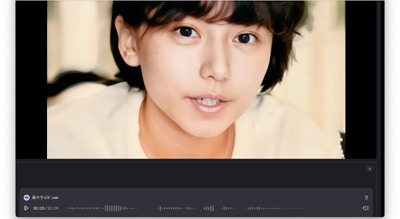
■HeyGenのExpressive Photo Avatarによる表現力のあるリップシンク
HeyGenのリップシンクも進化を遂げています。従来のリップシンクであるPhoto Avatarの表現力を高めた、Expressive Photo Avatarを実験的に導入しています。
3秒から30秒の長さのオーディオクリップと1枚の人物画像から高精度なリップシンク動画を生成するというもの。従来のPhoto Avatarは顔が正面のもの以外は歪んでしまっていましたが、新バージョンでは違和感がないです。
さらに、参照するオーディオデータにしたがって身振りや表情の変化、角度を勝手に変えたりできるため、より自然なリップシンクとなっています。
2枚の写真からDream Machineで生成した動画から、角度の違う写真を取り出し、それを元にして10パターンくらいのリップシンクを生成。それでミュージックビデオを作ってみました。
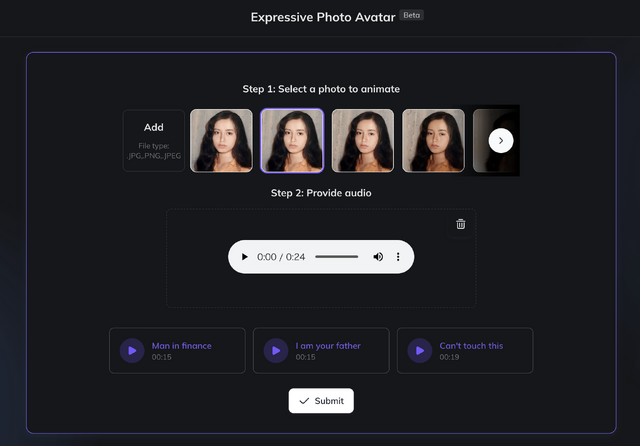
正面以外でも破綻なくリップシンクができています。手振りも勝手に入れてくれます。

HeyGenの現在の主力事業は、こうした楽曲用リップシンクではなく、ビジネス用途のAIアバターです。事前に撮影したビデオをベースに画像と音声のAIモデルを作成し、本人の声で多国語のプレゼンをできるようにしています。
都知事選で使われた一部候補者もおそらくこの技術を使ったものだと思います。企業への導入も進んでおり、例えばセゾンテクノロジーの葉山誠CEOは、社内向けにAIアバターによる英語プレゼンをしたところ、社員は区別がつかなかったそうです。こうしたAIアバターではジェスチャーも交えたプレゼンをできるので、そうした資産が今回のExpressive Photo Avatarに転用されているのでしょう。
■空間AIビデオをVision Proで鑑賞する
AIの新機能はほとんどがサービスベースなので高額なマシンがなくてもすぐに試せるのですが、新しいバカ高いデバイスを手に入れないと実体験できないものがあります。
それはApple Vision Proの空間フォト、空間ビデオです。こうして写真からAI生成した動画を空間映像にしてVision Proで見ると、さらにリアルに迫ってきます。
写真や動画を空間化するためには、Spatial Toolkitという有料アプリが使えます。
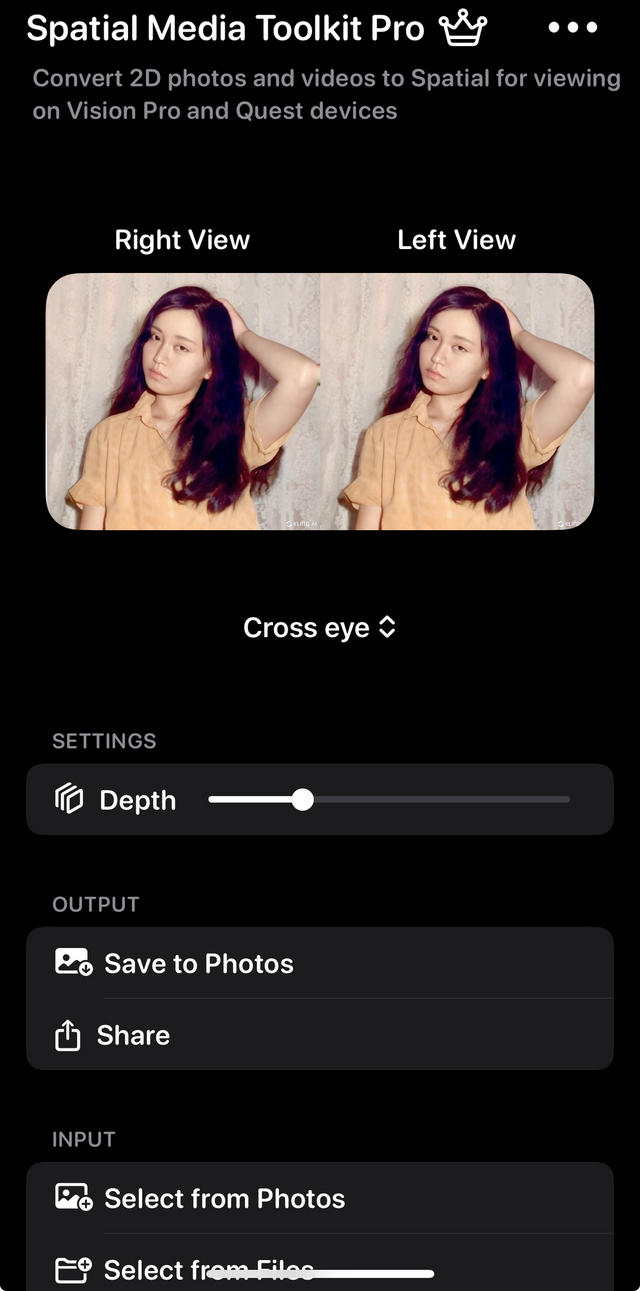

Vision Proアプリもあります。ライブラリの中の2D写真や動画を読み込んでRenderすると、それが空間フォト、空間ビデオにレンダリングされます。保存すると、Vision Proの写真アプリで見たときに、立体視できるというわけです。

(▲Vision Proの写真アプリで空間ビデオを見る)


(▲Vision ProでImmersive Viewにしてみた)
これらの空間ビデオはせいぜい5秒か10秒程度の短いものですが、生成AI動画技術を駆使して使ったミュージックビデオも空間ビデオとして没入することができます。筆者は歌詞やエフェクトなどは全部外したNakedバージョンを作って、自分だけの空間ミュージックビデオを楽しんでいます。

(▲Vision Proで空間ミュージックビデオを見ている)
夢の中にいるような、現実と幻想の世界の間に漂っているような、独特の浮遊感があります。
筆者はこのためにVision Proを購入したのですが、それだけの価値は十分にあったなと思っています。




















![アサヒ飲料 ドデカミンBIG 600ml×24本[エナジー] image](https://m.media-amazon.com/images/I/41B+VulVvYL._SL160_.jpg)


