


「AIオリジナル曲のリップシンクミュージックビデオを爆速で作る方法」について解説します。AIでなければ自分で弾き語りして自撮りするのが一番簡単なんですが、それは置いといて(笑)
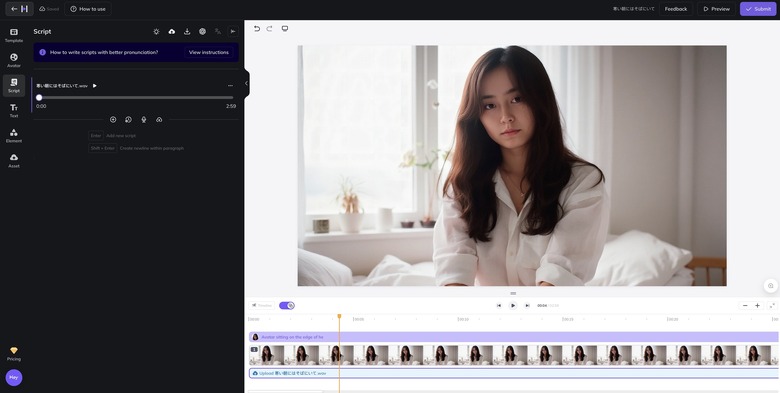
まず、完成形から。
歌手が一人で歌っているだけのシンプルなミュージックビデオです。作曲・演奏・歌唱はSuno v4ですが、映像はHeyGenだけという構成。
今時はこれだけで完成してしまうのです。そのプロセスも非常にスムーズで簡単なものになっているので、作り方を紹介します。
まず、曲を作りましょう。
テーマ(タイトル)を考える
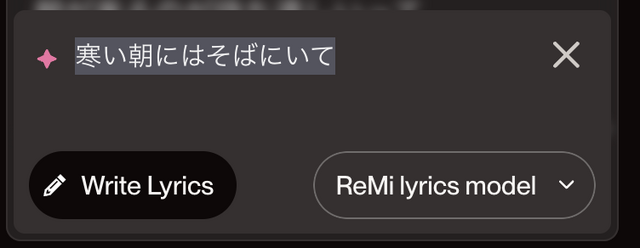
Suno v4では歌詞を考えるのがすごく簡単になりました。ReMiという作詞エンジンを使うと、短いフレーズ(タイトルになりそうなもの)を入れるだけで、日本語の歌詞を作ってくれるのです。
それで出来上がったのは、こんな歌詞。
[Verse]
あなたの寝顔を見ているよ
寝てるふりしてね
ふとんの中で夢を見て
二度寝とかしてね[Chorus]
朝が来るのが待ち遠しいって
思っていたのに また起きられない[Bridge]
日が暮れる頃
ひんやりした空気
わたしの頬ついた[Chorus]
ごめんね ごめんね
本当はちがうの
あなたもごめんね ごめんね
本当はちがうの[Verse]
寒い朝には そばにいて
つめたくなったらね
ふとんの中で火をたいて
あたためるからね[Chorus]
朝が来るのが待ち遠しいって
思っていたのに また起きられない
歌詞はちょこちょこ修正を入れています。
タイトルにはキーワードがそのまま使われました。
曲調はAOR(いわゆるシティポップ)にしました。プロンプトはこんな感じ。
AOR, west coast sound, sophisticated rock, smooth rock, clean guitar, rhodes piano, horn section, backing chorus, jazz-rock fusion elements, polished, layered harmonies, tasteful guitar solo
このプロンプトはいい感じのAOR曲ができるので、ぜひ使ってみてください。ClaudeにAOR用のプロンプトを考えさせたものです。
いい曲が出るまでガチャ
あとはいい曲が出るまでガチャ(Create)。
11回のガチャで22曲を生成し、そのうちの17番目のテイクを採用しました。
▲22曲を生成したうちの1つを採用
OKテイクが決まったら、WAVファイルをダウンロードします。これまでは、ここでStem化の作業をして、ボーカルとオケに分離していたのですが、それはしなくても大丈夫です。
Stemは不要
Stem化はもういらないのです。というか、ボーカルトラックだけにすると、日本語の歌詞を発音した場合に「あ」「お」が口を大きく開きすぎてしまい、表情が崩れてしまいがちなのですが、オケと混ざっていると、そこまで不自然にはならないという知識を経験則で得ました(日本語のみ)。オケの部分のほとんどは無視してくれるのですが、たまにギターソロなんかを口ずさんでくれて、それがまた味だったりします。
つまり、プロセスが1つ減って質が上がったわけです。
ちなみに、この歌声は、妻の歌声を元にしたSunoのペルソナという仮想シンガーで、どことなく本人の歌声に近いものなので、ボイチェンせずにそのまま使っています。ここでもまた1つプロセスが減ります。Logic ProでのStem分離やVocoflex、RVCへの変換、そしてミックスダウンも不要となります。
歌手のステージ衣装を決める
次にボーカリストの背景や衣装を決めましょう。スタイリストはあなたです。
顔が比較的大きく映っている画像であればOK。ただし、顔の前にマイクとかあるのは避けましょう。
というのは、この画像にはリップシンク(口パク)をしてもらうからです。
リップシンクができる動画サービスにはたくさんあります。筆者がよく使っているのはRunway Gen-3 Alpha TurboとHeyGen Photo Avatar。Runwayが最大でも40~50秒くらいしか生成できないのに対し、HeyGenは、筆者のプランでは5分間までのリップシンクができます。
さらに、20枚の写真からAIアバターモデルを作成済みなので、あとはプロンプトを指定するだけで好きなシチュエーションのポートレート画像が作り放題。Runwayの場合、Image to Videoでの元画像が必要なので、そこにはFLUX.1 [dev]のLoRAを用いているですが、これも不要。
曲調にあった画像プロンプトを指定するだけで、リップシンクの準備ができるのです。
このプロンプト、思いつかなかったら、LLMに頼ることもできます。
Sunoが作った歌詞をコピペして、「この歌詞にあった世界観の主人公の女性の写真用プロンプトを考えて」と指定しました。
a young Japanese woman sitting on the edge of her bed in early morning, soft morning light streaming through the window, wearing white cotton pajamas, long dark hair slightly messy, melancholic expression, ethereal atmosphere, cozy bedroom interior with white bedding, cool morning mist visible outside, cinematic lighting, soft focus, kodak portra 400, 85mm lens, shallow depth of field
これの先頭をAvatarに変えれば、そのままHeyGenのプロンプトに使えます。
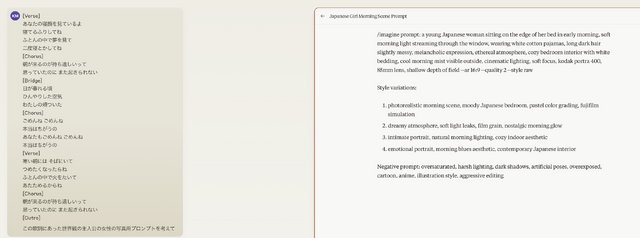
HeyGenの画像生成機能はなかなか優秀で、へたをするとFLUX.1に匹敵するレベル。それをそのままリップシンク動画にできるのですから使わない手はありません。

完成音源をアップロードして完成を待つ
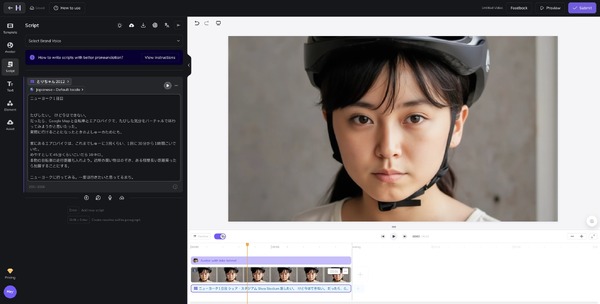
この中から、正面を向いている絵を選び、リップシンクさせる音声をアップロードします。
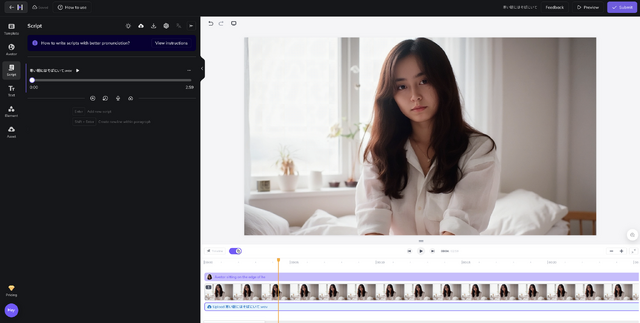
あとは数分間、出来上がるのを待つだけ。
出来上がりましたよメールが届いたら完成です。

HeyGenはiOSアプリもあるので、そのままダウンロードして、X、Facebook、Instagramなどにそのままアップロードできます。
ボーカルトラックだけでなく、オケもミックスされた音声なので、そのまま使えるという手軽さです。
使うツールは2つだけ。仮におしゃべりだけであれば、HeyGenのTTS(Text To Speech)機能を使えば、本人から学習した音声でリップシンクができます。というか、それが本来の使い方です。
あまりに簡単で拍子抜けするレベルですが、生成AI動画サービスが急激に他領域を取り込んできたおかげで、むちゃくちゃシンプルなプロセスで「話すor歌う」動画が作れるようになりました。
作品として完成させるのが目的であれば、いろいろなカットを入れるとか、曲選びにさらに時間を割くといったことも可能です。
SunoとHeyGen、この2つのサービスは、iOSアプリも用意されているので、全てをモバイルだけで完結させることもできます。
同じパターンでもう1曲作ってみました。
今度は自分の若い頃の写真を学習させたHeyGenのアバターに、自分の声をモデルにしたSuno v4のペルソナに歌わせたもの。


¥14,850
(価格・在庫状況は記事公開時点のものです)






![Cardill iPhone16 充電器 タイプc 充電器 type-c 20W PD 急速充電器 [正規MFi認証品/PSE認証済み] USB C-C 充電ケーブル 2M付き Type C 充電器 USB-C コンセント スマホ充電器 電源アダプター タイプC アイフォン 充電器 iPhone16/15/Pro/max/iPad Pro/AirPods その他USB-C機器対応 image](https://m.media-amazon.com/images/I/31w8qLOgZlL._SL160_.jpg)












