高精度でリアルタイム処理も可能なAI声質変換ソフト(ボイスチェンジャー)「RVC」の記事が大変な反響を呼びました。Stable DiffusionやChatGPTなど生成系AIがメジャー化する中、世間からはそれほど大きな注目を浴びているわけではありませんが、音声AIも驚くべき速度で進化を遂げています。
記事中でデモとしてお聞かせしたのは、筆者の妻の歌声を高精度に再現するもので、それはこのソフトのおそらく最大の特徴を生かしたものではありません。そこで、また実験をしてみることにしました。
今回は、ポッドキャストbackspace.fmを10年近く一緒にやっている友人であるドリキンのAIモデルをRVCで作ってみました。
backspace.fmはriverside.fmというサーバベースの収録システムを使っており、収録した音声はそれぞれの話者の分を個別にダウンロードできます。以前のエピソードで適当なものをピックアップしてダウンロード。これを素材にします。
元になっているのは1個の長いファイル。2時間以上あります。ここから学習に適した、数秒単位のファイルに切り出すわけですが、これを手作業でやろうとすると大変なことになります。そのまま学習することもできないわけではありませんが、精度がかなり落ちてしまいます。
そこで、RVCの学習からボイチェンまでの流れを丁寧に解説してくれているomizさんの記事を参考に、分割作業を実施しました。学習用のファイルの切り出しの部分でフリーのオーディオ編集ソフトのAudacityを使っているので、それを適用していきます。
ただ、自分のAudacityはバージョンが3.2.5で、解説記事ではバージョン2.4.2をベースにしているので、適宜読み替えて進めていきます。最終的に、ファイルが1時間30分くらいになったので、学習には十分な量になりました。分割したファイル数は3000個を超えました。
ちなみに、RVCは学習のためのボイスデータはそこまで長い必要はなく、数十分あればいいそうです。もちろん、長い方が精度は上がりますが。
これを、ガレリアのRTX 4080マシンで学習させます。学習用音声が入ったフォルダを指定し、名前を付け、あとはボタンを押して待つだけ。2時間後にはファイルが出来上がりました。ちなみに、その翌日に行われたバージョンアップで、学習時間が10分の1まで短縮されたそうです。恐ろしい開発スピードです。さらに、エポックという、学習回数の最大数値が100から1000に上がったので、さらに精度を上げることが可能です。妻音源とりちゃん[AI]のエポックを100から200にしたら、精度が聴いてわかるレベルで向上したので、意味はありそうです。
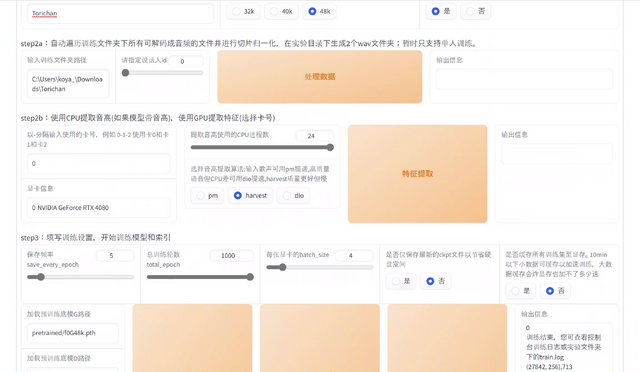
▲最新版RVCでは、エポックの上限を1000まで設定できる
出来上がったAIモデルと関連ファイル、合計3個を、今度は別アプリにコピーします。他のアプリと連携させるためのボイチェンソフト「VC Client」(開発はwokさん)です。
VC Clientは他にもさまざまなボイチェンソフトにも対応しているのですが、最近RVCにも対応。さらに、Apple Silicon対応を果たしたので、学習済みのAIモデルを、Mac上で使うことができます。前回はM1 Mac miniでやってみましたが、今度はM2 MacBook Airに組み込んでみました。
VC Clientでは生成した3つのファイルを読み込み、Startボタンを押せばリアルタイム変換が始まります。自分でモニタリングしたところ、品質的にも問題なさそうです。
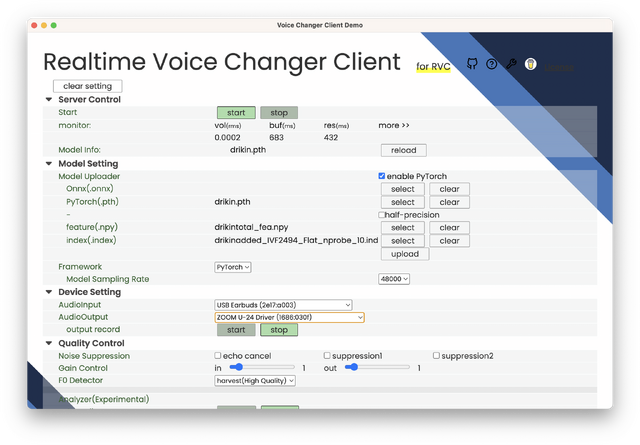
▲VC Clientでリアルタイムボイチェンを起動したところ
よし、みんなに聞いてもらって実験だ
では、リアルタイムでの会話が成立するかどうか試したくなります。VC Clientは、そういった用途に使えるようにできていて、サウンドルーティングソフトやオーディオインタフェースを経由すると、音声チャットソフトで使えるようになります。今回は、オーディオインタフェースを使い、Discordの音声チャットで使ってみました。
backspace.fmの会員制サービスであるBSMの専用Discordで音声チャットを始めたところ、声質については本人との区別がつかないと、ポジティブな感想が集まりました。
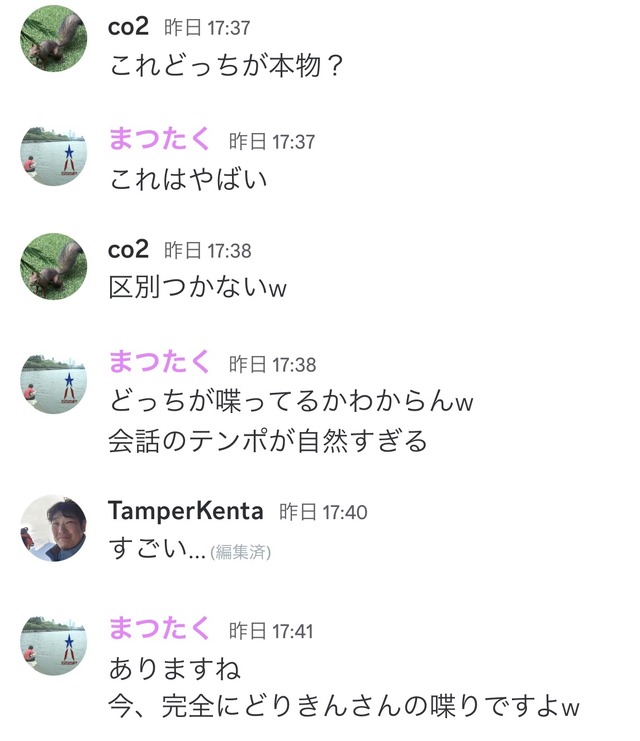
▲Discordで聞いた方々からの感想
そして、そこに本人登場。そのときの様子を、ボイチェン元のドリキンがYouTubeで公開しているので、ぜひ本人ボイスと聞き比べてみてください。
筆者が風邪をひいていて喉の調子が良くないこともあり、ところどころ咳き込む直前というのがわかるとか、語尾の部分とかで違和感はあるようですが、全体的に本人性は非常に高く、自分の声を一番聞いているドリキンが似ているというので、その精度は確かめられたと思います。あとは、本人の話し方の特徴を真似できれば完璧に近い模倣ができるのではないでしょうか。
ドリキンは音声チャット終了後、「神の逆鱗に触れるレベル」とコメントしています。
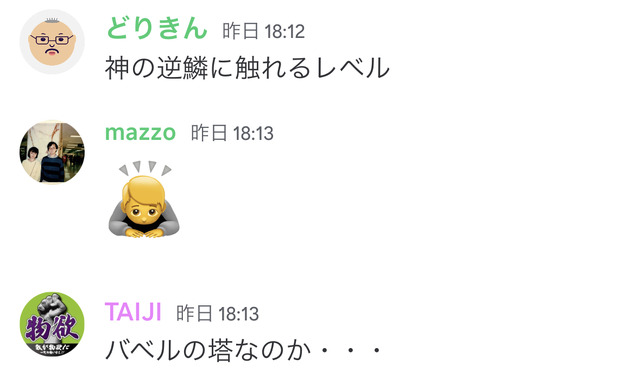
筆者はこういうことを許してくれる友人の声で実験したわけですが、そうでない事例は今後増えそうです。実際、筆者がやる前にドリキンの声でやってみたというコメントも見かけたので、もうすでにそこらじゅうで起きているのだろうなと想像しています。
ポジティブな利用方法は想像できます。声を失った方がお金をかけずに元の自分の声で発声できるようになるのは素晴らしいことです。今回は声質変換ですが、Text2Speechアプリと組み合わせれば、文字入力したものを本人音声で手軽に出せるようになります。オリジナル俳優の声と違和感のない声で各国語の吹き替えも可能になるでしょう。音声の声質と演技が分離して、新たな需要が生まれるかもしれません。
一方、特殊詐欺などの犯罪に使われる可能性を考えると、前回お伝えしたように、対面以外は信用できないという時代が来ているのかもしれません。ある意味、パンドラの匣を開けてしまった感はあります。
次回は、じゃあ対面であれば本当に信用できるのか、といったところの実験もしてみようと思います。