







Googleの大規模言語モデル(LLM)である「Bard」が、日本のユーザーでも使えるようになりました。ウェイトリストへの登録が必要ですが、数分で利用可能になります。なお、利用可能になったというメールは送られないので、しばらくしたらページをリロードしてみてください。

▲右側のJoin waitlistをクリックすると数分で利用可能に
日本で使えはしますが、「Experiment、実験」が末尾についている現バージョンは米国式英語のみの対応で、日本語を含めた他言語には対応していません。英語でのプロンプトに「translate it to Japanese」と命じても、翻訳をしてくれません。
なお、Googleのスンダー・ピチャイCEOがポッドキャストで「Bard」の改良を予告していましたが、これは4月10日に行われたことが更新履歴で明らかにされています。
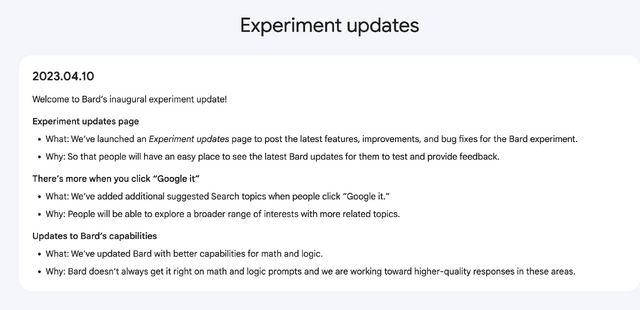
▲Bardの更新履歴
ここでは数学と論理処理をより適切に行えるなったとあります。このポッドキャストでピチャイCEOは、それまでが軽量版LaMDAであったのに対し、新バージョンではより進んだPaLMにアップグレードすると話していました。
Bardに「Is current Bard is based upon PaLM?」と聞いてみたところ、その通りであると回答しました。パラメータ数は5400億。6144個のTPU v4チップで学習させたそうです。
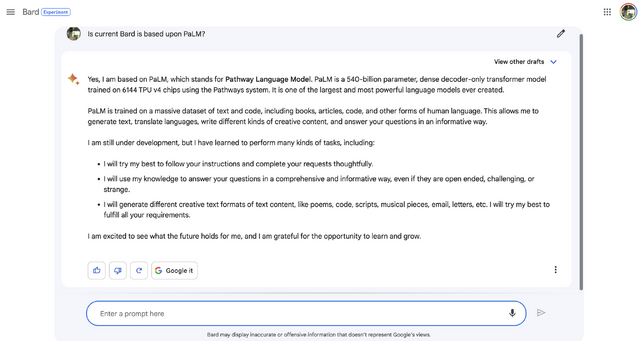
▲PaLMについての詳細な説明をしてくれました
回答の末尾には、良い、悪いの評価ボタンとリロード、そして「Google it」という関連検索用のボタンが設置されています。




