






1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第6回目は、盗作するリスクを回避する音楽生成AI、複数のAIが協力してソフトウェア開発するフレームワークなど、5つの論文をまとめました。
生成AI論文ピックアップ
AI同士がソフトウェアを開発する大規模言語モデルを用いたフレームワーク「MetaGPT」
本研究は、効率的な人間のワークフローを模倣する大規模言語モデル(LLM)駆動の複数エージェントによる協調フレームワーク「MetaGPT」を提案するものです。このフレームワークでは、人間による1行のテキスト指示(具体的なソフトウェアの要望)から、その指示に応じたソフトウェアを開発します。
MetaGPTは、役割定義、タスク分割、プロセス標準化、およびその他の技術設計を通じて、複数のエージェントを管理し、ソフトウェアの協調的な開発を実現します。
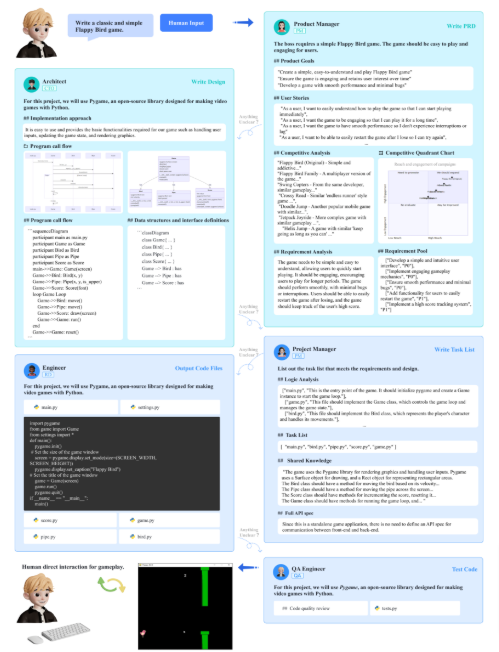
具体的には、人間からの要望を受け取ると、プロダクトマネージャー(PM)が要求分析と実現可能性分析を行い、プロセスを開始します。その後、アーキテクトがプロジェクトの具体的な技術設計を行います。プロジェクトマネージャーは、各要件に対応するためのシーケンスフロー図を作成し、エンジニアが実際のコード開発に取り組み、品質保証(QA)エンジニアが包括的なテストを行います。このようにMetaGPTは、実世界の作業進行をエミュレートするように設計されています。
AutoGPT、AgentVerse、LangChain、およびMetaGPTを使用して、Pythonゲーム生成、CRUD2コード生成、簡単なデータ分析タスクの包括的な実験を実施しました。結果は、コードの品質と期待されるワークフローへの適合性の両面で、MetaGPTが他の同等の手法よりも大幅に優れていることを示しました。
以下の図は、「古典的でシンプルなFlappy Birdゲームを書いて」という人間の要望からスタートしたソフトウェア開発プロセスの模式図を示しています。
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu
Paper | GitHub
音楽にキャプションを付けるAIデータセット「LP-MusicCaps」 音楽から画像、音楽から動画の生成デモも登場
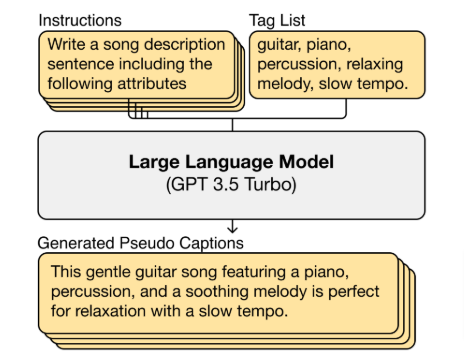
この論文では、音楽トラックに対して自然言語による説明(キャプション)を生成する大規模言語モデル(LLM)ベースの新たなアプローチを提案しています。このアプローチを用いて「LP-MusicCaps」と呼ばれる音楽キャプションデータセットが作成されました。このデータセットには約2百万のキャプションと50万のオーディオクリップのペアが含まれています。
この音楽キャプションデータセットは、音楽と言語のデータセット収集に要するコストと時間を大幅に削減し、音楽と言語を結びつける分野の研究を進展させる可能性を秘めています。
既にオーディオから画像を生成するデモも登場しています。このデモでは音声をLP-Music-Capsに送り、音声キャプションを生成し、Llama2を使ってキャプション画像に変換します。推論には音声の最初の30秒だけを使用します。
さらに、オーディオから動画を生成するデモも登場しています。このデモでは、音声をLP-Music-Capsに送って音声キャプションを生成し、Llama2でキャプション画像に変換し、最後にZeroscopeを介してオーディオから3秒のビデオを生成します。
LP-MusicCaps: LLM-Based Pseudo Music Captioning
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, Juhan Nam
Paper | GitHub | Hugging Face
16,000以上のAPIを操作する大規模言語モデルのためのフレームワーク「ToolLLM」 WeChatやTencent含む研究者らが開発
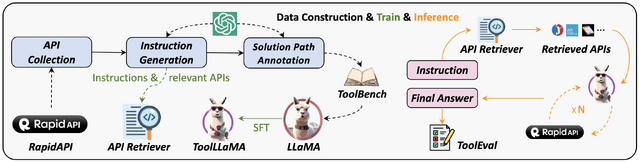
この研究では、大規模言語モデル(LLM)が16,000以上の外部APIを自然言語で理解し、操作するための新しいフレームワーク「ToolLLM」を提案しています。
具体的には、まず「ToolBench」と呼ばれるコンポーネントで、ソーシャルメディア、電子商取引、天気などの多様なカテゴリに属する16,464のAPIを収集し、各APIのドキュメントなども自然言語処理を用いて理解し、命令チューニングデータセットを作成します。これはChatGPT(gpt-3.5-turbo-16k)を用いて自動的に構築されます。
次に、ToolBenchデータセットを利用して、LLaMAを微調整した「ToolLLaMA」というコンポーネントにより、具体的なAPI呼び出しを生成します。
これにより、従来のLLMでは制約があった実世界のAPIの使用において、より高度なタスクを実行することが可能となります。
性能評価のために開発された「ToolEval」によると、ToolLLaMAは複雑な命令の実行や未知のAPIへの汎化において卓越した能力を発揮しました。この汎化性により、ユーザーは新しいAPIをシームレスに組み込むことができ、モデルの実用性を高めることができます。
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, Maosong Sun
Paper | GitHub
目の前の視覚体験と言語を関連付け、より複雑なタスクを解決できるAI「Dynalang」
人間と対話し、世界で行動するためには、エージェントは人間が使用する様々な言語を理解し、それを視覚的な世界と関連付ける必要があります。この研究では、マルチモーダルモデルを使用して言語と映像による視覚的な体験を同時に学ぶことで未来を予測し、より複雑なタスクを解決するAIシステム「Dynalang」を提案します。
従来のRL(強化学習)エージェントは、タスクの報酬に基づいて単純な言語命令を学習しますが、Dynalangでは一般的な知識を伝えたり、世界の状態を説明したり、インタラクティブなフィードバックを提供したりする多様な言語を活用するエージェントを目指しています。
行動を予測するために言語のみを使用する従来のエージェントとは異なり、Dynalangは将来の言語、ビデオ、報酬を予測するために過去の言語も使用することで、豊かな言語理解を獲得します。過去の入力からテキスト、画像、報酬のストリームを予測し、モデルによって想像されたロールアウトから行動することを学習します。
これにより、未来の予測と視覚体験を結び付け、幅広いタスクを解決することが可能となります。実験では、マニュアルに基づいたゲームの解決から、スキャンされた家での複雑な視覚言語ナビゲーションまで、様々な環境でDynalangを評価し、先端のRLアルゴリズムやタスクに特化したアーキテクチャを凌駕しました。特に、言語の複雑さが増して苦戦するケースで実力を発揮しました。

Learning to Model the World with Language
Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, Anca Dragan
Project Page | Paper | GitHub
盗作音楽を作り出さないText-to-Musicモデル「MusicLDM」
Text-to-Music生成にはいくつかの課題があります。その中でも主な懸念事項の1つは、他のモダリティと比較すると、利用可能なtext-musicのペアが少なく、高品質の条件付きモデルを訓練できないことです。なぜなら、音楽生成にはメロディ、ハーモニー、リズム、音色など、ニュアンスの異なる多くの音楽概念を含むため、大規模で多様な学習セットが必要だからです。
さらに、生成された音楽には盗作や新規性が欠如しているリスクがある点も重要です。音楽は著作権法によって保護されていることが多く、既存の音楽と酷似した新しい音楽を生成すると、法的な問題に発展する可能性があります。このため、学習データセットが比較的小さい場合でも、盗作を回避しつつ、新規性のある多様な音楽を生成できるText-to-Musicモデルの開発が重要とされています。
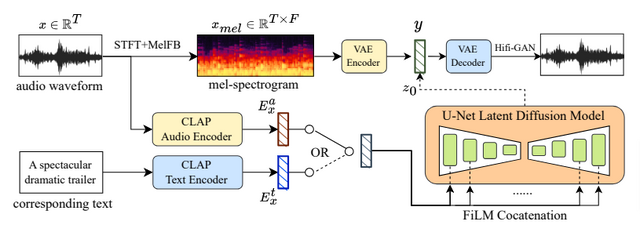
本研究では、これらの課題に焦点を当て、限られた並列学習データから新しいテキスト条件付き音楽を生成するための新しいモデルと学習戦略を開発しました。具体的には、音楽ドメインに適応したText-to-Musicモデル「MusicLDM」を構築しました。このモデルはStable DiffusionとAudioLDMのアーキテクチャを使用しており、CLAP(contrastive language-audio pre-training model)とHifi-GAN vocoderを音楽データサンプルに対して再トレーニングすることで実現しました。
さらに、データ拡張のために「Mixup」という手法を音楽生成用に適用した、「Beat-synchronous audio mixup」 (BAM) と「Beat-synchronous latent mixup」(BLM) を提案しました。これにより、データ制限や盗作問題に対処することが可能となりました。
MusicLDMはAudiostockデータセット(10,000個のテキストと音楽のペア、455時間)で学習され、実験の結果、盗作の音源を大幅に軽減させ、全体的な音楽オーディオの品質も向上させることができ、最先端のモデルを凌駕する結果となりました。
コードと事前学習モデルは8月中旬に提供予定。
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, Shlomo Dubnov
Project Page | Paper | GitHub




