









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第8回目は、マイクロソフトによるText-to-Speech技術、3Dシーンやアバター生成技術など、5つの論文をまとめました。
生成AI論文ピックアップ
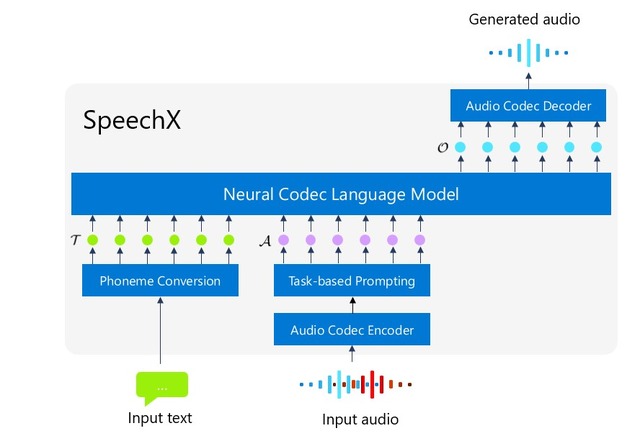
任意の人の声でテキストを読ませるText-to-Speechモデル「SpeechX」 米Microsoftの研究者らが開発
本研究では「SpeechX」という多様な音声編集タスクを処理できるモデルを提案します。このモデルは、クリーンな音声信号だけでなく、ノイズのある音声信号でも、さまざまな音声合成タスクを処理できます。例えば、以下のようなことを可能にします。
ゼロショットTTS(指定したスタイルで文章を音声合成)
音声コンテンツ編集(間違った言葉を自然言語で修正)
背景を保持した音声コンテンツの編集(背景音を保持したまま、会話を自然言語で修正)
ノイズの除去(録音に混入した不要な背景音を除去)
目標話者の選択(混声の中で一人の人物に照準を合わせる)
スピーチの削除(人の声を自然に消す)
SpeechXは、Microsoftによる以前の音声モデル「VALL-E」と同様の言語モデリング手法を採用しており、テキストと音響の入力に基づいてニューラルコーデック言語モデルのコードを生成します。多岐にわたるタスクを処理するために、マルチタスク学習の設定で追加のトークンを組み込む仕組みを導入しています。これにより、音声の強化や変換タスクにおいて、一貫性のあるアプローチを提供し、拡張可能なモデリングを実現しています。
LibriLight(自動音声認識システムの学習用ベンチマーク)からの6万時間の音声データを使用した実験の結果、すべてのタスクで専門モデルと比較して同等または優れた性能を示し、SpeechXの有効性が実証されました。特に、音声編集中に背景音を保持したり、ノイズ除去や目標話者の抽出など、拡張された機能を実証しました。
デモサンプルはプロジェクトページで確認できます。
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, Takuya Yoshioka
Project Page | Paper
映像から3Dシーンを生成できるVideo-to-3Dモデル「Neuralangelo」のコードが公開
2023年6月にNVIDIAなどの研究者らによって公開された論文「Neuralangelo」のコードが公開されました。Neuralangeloは、異なる視点から撮影された2D映像から、映像に映る建物や物体、風景といった実世界のシーンを3Dに変換するVideo-to-3Dモデルです。
この技術の登場は、1年前にNVIDIAが発表した「Instant NeRF」という先進的な技術に続くものです。Instant NeRFは2Dビデオから鮮明な3Dシーンを迅速に作り出せる能力を有していましたが、生成された3Dモデルには詳細な構造が欠けるなどのアーティファクトがありました。
Neuralangeloは、Instant NeRFのこれらの課題を克服する改良が施されています。これによって、深度や他の補助入力を必要とせず、多視点画像から微細な3D表面構造を効果的に復元することが可能になりました。また、RGBビデオキャプチャからの大規模シーン再構築も可能になりました。


Neuralangelo: High-Fidelity Neural Surface Reconstruction
Zhaoshuo Li, Thomas Müller, Alex Evans, Russell H. Taylor, Mathias Unberath, Ming-Yu Liu, Chen-Hsuan Lin
Project Page | Paper | GitHub
安定したビデオ合成ができる動画処理技術「CoDeF」 中国の研究者らが開発
「CoDeF」という新しい設計により、ビデオに対して調整もせずに画像処理のアルゴリズムをビデオ処理に直接適用することが可能になります。
CoDeFは、ビデオ全体の静的コンテンツを集約するモジュール「Canonical Content Field」と、時間軸に沿って各フレームへの変換を記録するモジュール「Temporal Deformation Field」から構成されます。
入力ビデオに対して、これらの2つのフィールドがレンダリングパイプラインを通じて共同で最適化されます。さらに、最適化プロセスにいくつかの正則化を導入することで、ビデオからの意味情報を伝搬させるようにしています。
実験の結果、CoDeFは、訓練なしで画像からビデオへの変換やキーポイントトラッキング、セグメンテーションなどに拡張することができることが示されました。比較実験では、既存の類似手法に比べ約4倍の品質向上を実現し、また従来10時間以上かかっていた処理が約300秒で完了するなど、効率の向上も実現しました。
さらに、アルゴリズムを単一の画像にのみ適用するという戦略により、既存の動画から動画への変換手法と比較して、処理されたビデオにおける卓越したフレーム間の整合性を達成し、水や煙などの非剛体オブジェクトさえも追跡することが可能となりました。


CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Hao Ouyang, Qiuyu Wang, Yuxi Xiao, Qingyan Bai, Juntao Zhang, Kecheng Zheng, Xiaowei Zhou, Qifeng Chen, Yujun Shen
Project Page | Paper | GitHub
写真1枚から着衣3D人体モデルを高精度に生成する技術「TeCH」
TeCHは、1枚の全身写真からアニメーション可能な高精度の3D着衣人体モデルを生成する手法です。特に、人体の見えない部分(背面など)の再構築に成功し、これまでのぼやけた表現や矛盾を解消しました。
具体的には、入力画像の意味情報を2つに分割し、衣服や外見の特徴を捉えます。1つ目の意味情報は、衣服のスタイルや顔の特徴などをテキストとして解釈します。もう1つは、テキスト化できない細かい外見や特徴を「DreamBooth」で解釈します。
これら2つの意味情報を元に、ジオメトリとテクスチャの最適化を行います。さらに、低解像度3Dモデルから高解像度3Dモデルを合成する「DMTet」に基づくハイブリッド3D表現も提案し、忠実度の高い仕上がりでありながらコストを抑えたシステムを構築しています。
実験により、TeCHが他の手法と比べて高い精度で3D人体モデルを再構築できることが確認されました。不可視領域の予測も成功し、一貫した高品質のテクスチャとジオメトリを生成できることがわかりました。

TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Yangyi Huang, Hongwei Yi, Yuliang Xiu, Tingting Liao, Jiaxiang Tang, Deng Cai, Justus Thies
Paper | GitHub
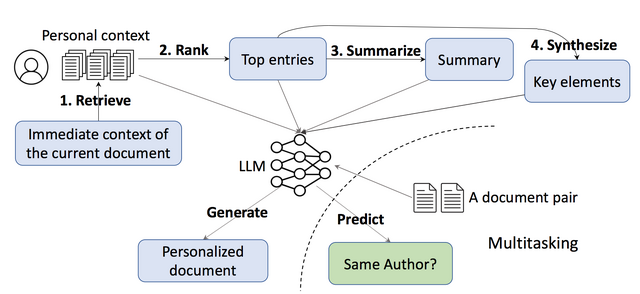
ユーザー特化のAIチャットボットが作れるアプローチ Google含む研究者らが開発
この研究では、大規模言語モデル(LLM)をユーザー特化にパーソナライズするテキスト生成のためのアプローチを提案しています。
この手法は、ユーザーが過去に書いた文書などから関連情報を取得し、新しい文書を生成します。具体的には、過去の関連情報の検索、ランク付け、要約、重要な要素の抽出、これらを統合したテキスト生成を組み合わせます。
さらに、読み書きのスキルが相互に関連していることに着目し、LLMの読解能力を向上させるための補助タスクを導入しています。このタスクはモデルによってテキストをより深く理解させ、よりパーソナライズされたコンテンツを生成するのに役立ちます。
提案されたモデルは、個人のメールコミュニケーション、ソーシャルメディアの議論、製品レビューなどのデータセットで評価され、各データセットで高いパフォーマンスが示されました。
Teach LLMs to Personalize — An Approach inspired by Writing Education
Cheng Li, Mingyang Zhang, Qiaozhu Mei, Yaqing Wang, Spurthi Amba Hombaiah, Yi Liang, Michael Bendersky
Paper







