








1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第9回目はMetaが2つの重要論文を公開。オールインワン多言語マルチモーダルAI翻訳・書き起こしモデルの「SeamlessM4T」、コーディング専用生成AI「Code Llama」がMetaによるものです。これらを含む5つの論文をまとめました。
生成AI論文ピックアップ
Meta、オールインワン多言語マルチモーダルAI翻訳・書き起こしモデル「SeamlessM4T」を開発
Metaが発表した「SeamlessM4T」は、多言語・マルチモーダル翻訳をサポートする技術で、従来の技術と比べて格段に高い性能を持っています。以下のタスクが1つのモデルに統合されています
約100言語の音声認識
約100の入力・出力言語での音声からテキストへの翻訳
約100の入力言語と36の出力言語をサポートする音声から音声への翻訳
約100言語のテキストからテキストへの翻訳
約100の入力言語と35の出力言語をサポートするテキストから音声への翻訳
開発時には、自己教師あり学習法を用いて100万時間の音声データを活用し、音声表現を学習。
既存の技術と比べて、音声からテキストへの翻訳精度は20%向上し、音声から音声への翻訳精度も58%向上しました。また、背景ノイズやスピーカーの変動に関しても、このシステムは従来のモデルよりも優れた性能を発揮しています。さらに、ジェンダーバイアスや有害な表現に対する評価を行い、翻訳結果の有害性を最大63%削減することを確認。
SeamlessM4Tは研究用ライセンス下で一般公開されており、「SeamlessM4T-Large」(2.3Bパラメータ)および「SeamlessM4T-Medium」(1.2Bパラメータ)が含まれます。
また、「SeamlessAlign」のメタデータも公開されています。SeamlessAlignは、これまでで最大のオープンなマルチモーダル翻訳データセットで、合計27万時間に及ぶアライメントされた音声とテキストが含まれます。

SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Seamless Communication, Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang
Project Page | Paper | GitHub | Hugging Face
Meta、コーディング専用生成AI「Code Llama」を開発
Metaは「Code Llama」という、自社で開発したLlama 2に基づく大規模なコード専用の言語モデルもリリースしました。これは、オープンモデルの中で最先端の性能を持ち、大規模な入力コンテキストやプログラミングタスクのゼロショット指示が可能です。
コードと自然言語の入力をサポートし、コードの生成、補完、デバッグ、そしてコードに関する自然言語の出力が可能です。Python、C++、Java、PHP、Typescript(Javascript)、C#、Bashなどの言語に対応しています。
様々なアプリケーションをカバーするため、基盤モデル「Code Llama」、Python特化型「Code Llama – Python」、自然言語命令を理解するためのモデル「Code Llama – Instruct」として、それぞれ7B、13B、34Bのパラメータで提供しています。
Code Llamaは、HumanEvalで53%、MBPP(Mostly Basic Python Programming)で55%のスコアを記録し、オープンモデルの中で最先端の性能を持っています。特に、Code Llama – Python 7Bは、Llama 2 70BをHumanEvalとMBPPで上回ります。また、すべてのモデルは、公開されている他のモデルをMultiPL-Eで上回っています。
Code Llamaは、研究および商用の両方の利用が可能なライセンスでリリースされています。
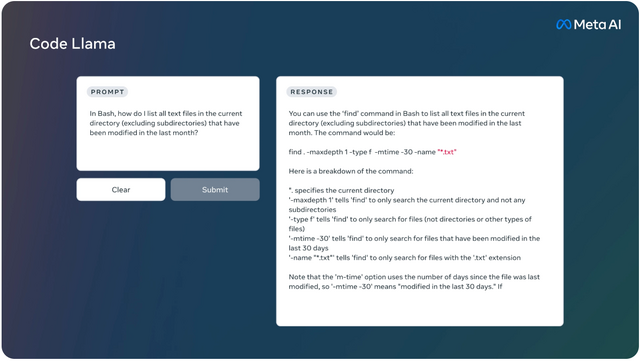
Code Llama: Open Foundation Models for Code
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve
Project Page | Paper | GitHub
“非英語”をマルチモーダル学習するための手法「MPM」 中国の研究者らが開発
最近、画像とテキストを組み合わせたマルチモーダル学習に対する関心が高まってきましたが、成功している例は主に英語に限られており、他の言語はそれに比べて取り組みが遅れています。この遅れの主な理由は、大量の画像とテキストのペアデータが必要であるにも関わらず、非英語のマルチモーダルデータが不足しているためです。
本研究では、データが少ない言語でも効果的に大規模なマルチモーダルモデルを訓練する新しい方法「MPM」を提案しています。MPMは、多言語モデルを活用し、言語間のマルチモーダル学習をゼロショット(事前情報なしで)可能にするものです。
英語の画像-テキストデータだけで事前に訓練されたマルチモーダルモデルが、他の言語でもゼロショットの手法を用いて高い性能を達成し、その言語専用のデータで訓練されたモデルの性能を上回ることが確認されました。
特に、中国語を対象とした際に「VISCPM」という大規模なマルチモーダルモデルを構築し、中国語における最先端の結果を得ることができました。この研究で使用されたソースコードやモデルの重みは公開されています。
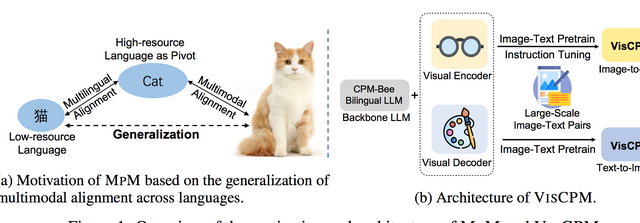
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Jinyi Hu, Yuan Yao, Chongyi Wang, Shan Wang, Yinxu Pan, Qianyu Chen, Tianyu Yu, Hanghao Wu, Yue Zhao, Haoye Zhang, Xu Han, Yankai Lin, Jiao Xue, Dahai Li, Zhiyuan Liu, Maosong Sun
Paper | GitHub
テキスト指示で高い一貫性を保った動画編集が可能な「StableVideo」
生成AIによるビデオ編集の分野では、高品質かつ一貫性のある編集を実現するのは依然として難しい課題となっています。なぜなら、ビデオは連続した画像で構成されており、一部を変更するだけで、全体の一貫性や自然さが失われる可能性があるからです。
この問題を解決するための新しい方法として「StableVideo」というアプローチが提案されています。この方法は、映像の中から代表的な部分、いわゆる「キーフレーム」を選び、それを基に編集を行います。そして、そのキーフレームの編集結果に基づき、ビデオ全体の映像を調整します。
これにより、高品質で自然なビデオ編集を実現するテキスト駆動の拡散ベースのフレームワークが構築されます。この方法を用いると、部分的な編集がビデオ全体に自然に広がり、全体の映像が一貫性を保ちながらも高品質に編集されます。
従来の方法と比べて、StableVideoの方法は、編集の質を向上させるだけでなく、編集作業の複雑さも軽減することが期待されます。

StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Wenhao Chai, Xun Guo, Gaoang Wang, Yan Lu
Paper | GitHub | Hugging Face
風景写真や映像をアニメっぽく加工できる生成AI「Scenimefy」 シンガポールの研究者が開発
アニメの風景シーンを再現するため、シンガポールの研究者が「Scenimefy」という新しい半教師あり学習フレームワークを用いた画像変換技術を提案しています。
提案するシステムは、「StyleGAN」という先進的な技術を利用して、リアルなシーンとアニメの間で疑似ペアデータを生成します。このデータは、教師データとして使用され、高品質なアニメ変換の学習に役立ちます。
CLIPやVGGなどの事前学習モデルを用いて、StyleGANを微調整します。これにより、複雑なシーンの特徴を捉えると同時に、過学習を防ぎます。また、セグメンテーションガイドを使用して低品質なデータをフィルタリングし、より高品質な変換を達成します。
リアルなシーンとアニメの間の詳細な対応関係を学習するための新手法を導入し、アニメ独特のスタイルやテクスチャを正確に再現します。
Scenimefyの有効性を検証するための包括的な実験を実施し、定性的品質および定量的評価の両方で最先端の性能を上回る結果を確認しました。
リアルとアニメのシーンの間には明確なドメインギャップが存在し、このギャップを埋めるためには高品質なアニメ風景のデータセットが必要です。しかし、既存のデータセットには多くの人物やその他の前景オブジェクトが含まれ、そのスタイルが背景とは異なるため品質が低いものとなっています。この研究では、風景のスタイル化に関する将来の研究を支援するための高解像度アニメ風景データセットも提供しています。

Scenimefy: Learning to Craft Anime Scene via Semi-Supervised Image-to-Image Translation
Yuxin Jiang, Liming Jiang, Shuai Yang, Chen Change Loy
Project Page | Paper | GitHub










