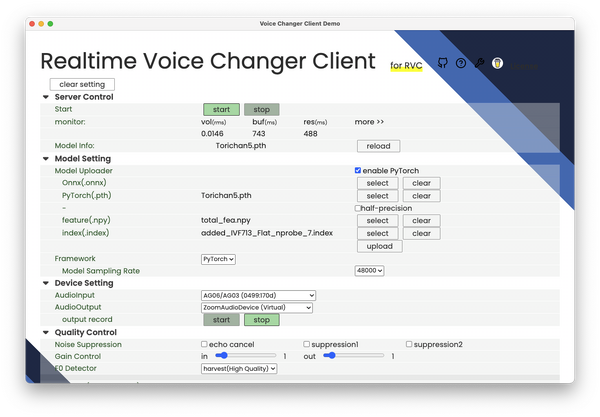
わずか3秒の元音声から本人そっくりな音声合成が可能な技術「VALL-E X」が誰でも使える形で公開されました。オープンソース版で、ローカルマシンからWebUIで利用できます。さっそくインストールして使ってみました。
以前、ディープラーニングベースの音声・歌声合成ソフトであるDiff-SVC、リアルタイム処理が可能なAIボイチェンRVCを紹介したとき、自分は記事タイトルに「驚異の」という形容詞を付けました。それでも学習には数十分の本人による音声データが必要で、そこまでのデータを用意するのは容易ではありません。それに対してVALL-E Xでは元データが3秒あれば本人に似た声を生成できるのです。
これはごく短いオーディオデータしか残っていない人の声(故人や声を失ってしまった人)を再現する場合には大きな福音ですが、その一方でディープフェイクボイスとして詐欺に使われたりと、大変な脅威と見る人も多いでしょう。それは、この技術を開発したマイクロソフトの行動が示しています。
マイクロソフトが、たった3秒間のサンプル音声から誰かの声をシミュレートし、テキストを読み上げさせられる独自の音声AI「VALL-E」を発表したのが今年の1月。

マイクロソフトはこの技術が社会的に害をもたらす可能性を認識しているとして、そのコードを公開することは差し控えていました。
「使い方を誤ればティープフェイクの音声版にもなり得る」とまで危険視していたこの技術をさらに改良した「VALL-E X」をマイクロソフトがリリースしたのが3月。
今回取り上げる「VALL-E X」は、シンガポール在住の研究者であるPlachtaaさんがこの論文をもとにオープンソース実装したものです。マイクロソフト自身が公開したわけではないので注意が必要です。詳しくはこちらの記事をどうぞ。
VALL-E X の OSS実装を試す
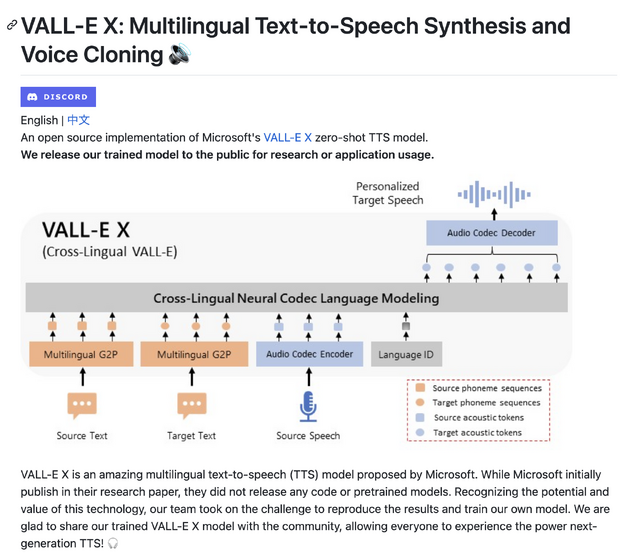
マイクロソフト版になかった日本語もサポート
マイクロソフト版とこのオープンソースソフトウェア(OSS)版の、われわれにとって重要な違いは、日本語をサポートしている点。マイクロソフト版は英語と中国語のみでしたが、OSS版VALL-E Xでは言語として日英中、さらにそれぞれの言語に対して別の言語のアクセントをつけることも可能となっています。つまり、学習元の音声データが中国語、英語、日本語のいずれであっても、それぞれのネイティブ発音だけでなく、英語訛りの日本語、中国語訛りの英語、といった表現が可能になります。
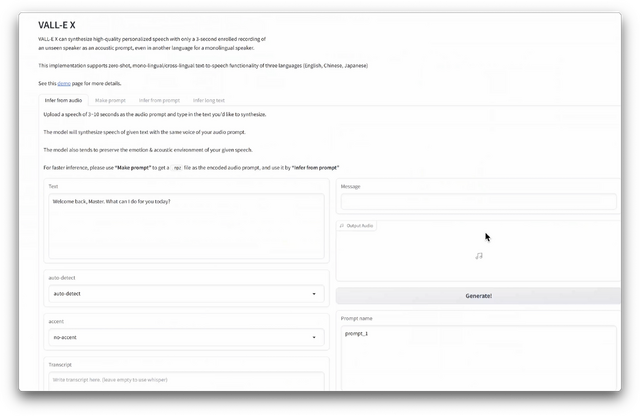
▲OSS版VALL-E XのWeb UI初期画面
ボイスクローンは非常に高速
このOSS版VALL-E Xは、NVIDIA GPU搭載のWindowsマシンにインストールするための方法が公開されており、容易に組み込むことができます。Webブラウザでわかりやすく操作できるWeb UIも最初から実装されているので、学習も推論も簡単に使えます。Hugging FaceとGoogle Colabを使い、オンラインで試すこともできます(Hugging Faceへのリンク)。
今回は、Core i7-13700(13世代)とGeForce RTX 4090のガレリアPCで試してみました。
筆者はこれまで多様な音声合成ソフトを試してきましたが、音源作成がこれほど簡単だったものはありませんでした。なにせ、必要な音声の長さはわずか3秒。それをアップロードして名前をつけ、スクリプト(読み方)を記述して変換すれば、ほぼ一瞬で音源が出来上がります。

▲自分の声を録音した3.4秒のWAVファイルを学習させたが一瞬で完了
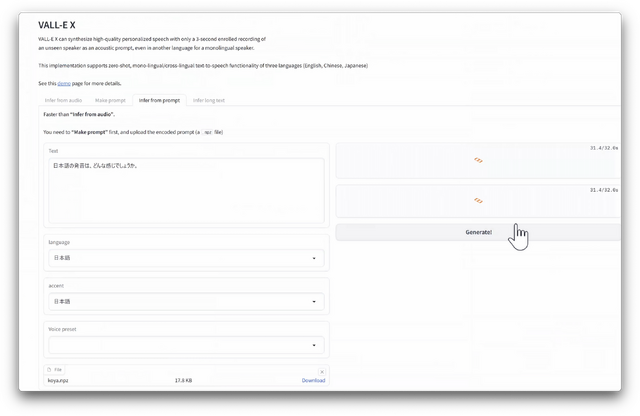
▲左下のkoya.npzというファイルが、学習データ(Prompt)。これをアップロードすることで、その声でのTTSが使えるようになる
解説動画を作ってみたので、どういうものかはチェックしてみてください。
TTS変換速度は改善の余地あり
欠点もあります。学習が一瞬で完了するのに対し、TTSの処理速度が非常に遅いのです。数秒分のテキストから音声生成するのにかかる時間は数十秒。これではリアルタイムでタイピングして音声を生成するといった用途には向きません。このアンバランスさは今後のバージョンアップで改善されると思いますが、現時点ではこの非実用性がかろうじてフェイクボイスの壁となってくれているのかもしれません。しかしそれもごく短期間でしょう。
パンドラの匣、完全に開いてしまった感ありますね。