




Facebookでは「~年前の自分の投稿」を再度シェアするよう促してくるお節介な機能があります。これにより気づくことも多く、自分はけっこう重宝しています。さて、そのFacebookが思い出させてくれたのが、2022年12月17日の自分の画像投稿でした。

同日、生成AIを自分で使ってみた最初の記事をテクノエッジのこの連載コラムで公開。その後の生成AIブームに乗っかった形で新しい技術を試していくという流れができました。
というわけで、ここを起点に、2023年のちょっと前からの生成AIの動きを自分の取り組みを中心にまとめてみます。一般ユーザーが実践できるものとしてどのように進化してきたかを振り返る手掛かりになれば幸いです。
2022年12月:特定人物の画像生成でカスタム学習が可能に
AI研究家の清水亮さんが運営しているAI画像生成サービス「Memeplex」が、画像生成エンジンであるStable Diffusionでカスタム学習を可能にするDreamBoothを誰でも使えるようにしたのが2022年12月24日のこと。特定人物の複数の写真をカスタム学習させることで、その人物の特徴を持った画像を生成できる機能を、Memeplexの有償サブスクリプション会員限定で提供し始めました。その少し前からこの機能は清水さんのnote記事購入者が利用できるようになっていて、それを元に書いた記事が、「AIと呪文で、もう逢えない妻の新しい写真を捏造した」という記事(2022年12月17日)です。

この当時は、Stable Diffusionをローカルマシンで動かしたり、DreamBoothを使えるようにするためには相当のスキルが必要で、目的とする画像に到達するためのハードルはかなり高いものでした。さらに、ベースにするAIモデルの選択やプロンプトの組み方などの情報が少なく、西川和久さんがまだこの分野で記事を書かれていなかった時期でもあります。
試行錯誤しながら書いた記事がちょうど1年前の「AIという異世界カメラ。旅立った妻の美しい姿を写す呪文の唱え方」(2022年12月27日)。

2023年1月:AIボイスチェンジャーとChatGPTの登場
この時点で、他界した妻の画像を生成AIで作っていることに対する反感が生まれています。そうした反感コメントに対する筆者の考えを述べた記事も書きました。今も、ほぼ付け足すことはありません。

こうして生成した妻の画像を、10年前から取り組んでいる、従来型音声合成による妻の歌声と組み合わせたミュージックビデオを作って公開したところ、音声合成についても機械学習を使った画期的な技術があることをコメントで教えてもらいました。やってみるものです。


教えてもらった技術は、「Diff-SVC」と呼ばれる、Diffusionモデルを使ったオープンソースソフト。いわゆるボイスチェンジャーソフトですが、特定個人の音声を学習し、その人の声の特徴を模倣できるものです。同様のことは従来でもあったのですが、その元データのラベリングや補正処理をほとんど無しで済ませられることが画期的でした。それを試してみたのが1月19日の記事です。

Diff-SVCを使った歌声の作例としては、日本では最初期に近いものでした。筆者が自分で歌ったものをDiff-SVCで妻の歌声に変換し、それにStable Diffusion(Memeplex)で生成した妻の画像を組み合わせたミュージックビデオも公開しました。
12月にアナウンスされた「第一回AIアートグランプリ」には、このミュージックビデオをそのままAIアート作品として応募しました。締め切りは1月末だったので、かなりギリギリ。同一人物のAI画像合成と音声合成をまとめることができたのは、時期的にこのタイミングが最速だったからです。

一方で、今や大きな社会問題となっている、アーティストの歌声を勝手に真似ることがソフトウェアの開発に悪影響を及ぼすことになった事例もありました。この問題は今も引きずっています。

絵、音が先行した生成AIですが、一般的に大きな広がりを見せることになったきっかけはなんといってもChatGPTの登場でしょう。
筆者が最初にChatGPTを使ったのは1月30日の記事でした。作曲のための補助として。このときのChatGPTには作詞とコード進行を担当してもらい、演奏とメロディーラインは自分で作るというものでした。これが「Suno」の登場で一気に完成形まで行けちゃうのだからその後の進化スピードがすごいです。

2023年2月:AIアニメーション技術が続々登場
1月ほどの勢いはないものの、2月も画像生成AIの進化は続きます。最初にきたのは、GIFアニメーションを作るツール「Tune-A-Video」。1枚の静止画を数枚のカクカクした動画にする技術です。最近の動きと比べるとずいぶんプリミティブなものですが、当時としては画期的なものでした。

続いてリップシンクが可能になりました。いわゆる口パクですね。オーディオデータに合わせて口を中心とした自然な顔のアニメーションを可能にする技術です。以前からCrazyTalkなどの技術はありましたが、機械学習を使ってより自然なものにできています。2月14日の記事で紹介した「D-ID」という有料サービスは今では性能的にちょっと遅れたものになってしまいましたが。ミュージックビデオに使うにはこの時点で最高のサービスでした。
さらに、1枚絵を拡大・縮小しながら次々にアニメーションを展開できる技術「Kaiber」も登場します(3月2日)。手描きアニメーションでやったとしたらどれだけ工数がかかるだろう、という表現を一発でできるのはすごい可能性を感じるものです。この有料サービスは今もサブスクしていて、たまに使っています。

3月:第一回AIアートグランプリ受賞
3月12日、予想もしていなかったことが起きます。筆者が投稿した作品「Desperado by 妻音源とりちゃん[AI]」が第一回AIアートグランプリを獲得。生成AIアートの大規模なコンテストとしては日本で初ということもあり、マスコミにも大きな注目を浴びることになりました。他のコンテスト入選作品を含む解説記事も書きました。

今振り返ると、この時の佳作入選作の中に、第二回AIアートグランプリを「明日のあたしのアバタイズ」で獲得した/快亭木魚さん、優秀賞を「幻視影絵」で獲得した実験東京の安野貴博さんの名前がすでにあるのが確認できます。
4月:AIボイチェンの決定版「SVC」登場
4月に入ると、画像生成AIのStable Diffusionは基本解像度が上がり、モデルも格段に良くなったSDXLが登場。

一方、AIボイチェンはDiff-SVCから新たなエンジン「SVC」へとバトンタッチされます。こちらはより精度が高く、少ない元データで、学習時間も短くて済む上、推論も高速という、いいことだらけのソフト。最初からWeb UIで使えます。妻音源とりちゃん[AI]は、これ以降ずっとSVCを使っています。さらに、ノートPCでリアルタイム変換できるソフトも登場し、リアルコナン君ごっこもできるように。Shiftallのmutalkを使って、リアルな場でAIボイチェンする実験もやってみました。

最終的にこの手法は岸田首相にまで伝わることになります。
5月:ChatGPTのモバイルアプリ登場
OpenAIのチャットAI「ChatGPT」は、ブラウザベースのサービスなので、モバイルでももちろん使えるのですが、iPhone、Androidのアプリはまだ登場していませんでした。

まずは米国版から登場。日本語版も5月26日には使えるようになりました。驚くべきはその音声認識技術。日本語と英語を混在させたものも、ほとんど間違わずに認識できます。これはSiriを大きく上まる出来で、それ以降、ChatGPTアプリを使う頻度は非常に高くなりました。

6月:WWDCで期待のAppleGPTは出ず。テレビ出演。西川和久さんのAIグラビア連載スタート
6月といえばWWDCの月。これだけ生成AIが騒がれているのだから何らかの発表があるだろうと期待して書いた予想が完全な大外れとなりました。
・「ChatGPT」アプリの登場で“生成AIとSiriの関係”はどう変わる? AppleのAI戦略を予想する
その後Appleは地味な論文をちょこちょこ出していて、スモールフットプリントなLLMを使えるようにする方向で動いているのは確かなようなので、予想したところに向かっている気はするのですけどね。
さて、6月は個人的に大きな動きがありました。テレビ出演です。3つのテレビ番組による自宅取材が続けざまにあり、それが放映されることになりました。妻の歌声を再現するテレビ取材は、2021年にNHKにされたことがあり、初めてではありませんが、生成AIブームへの世間の関心の高さはすごいなあと実感しました。その中でも一番長い時間放映された、6月15日放送「News23」の内容に触れた記事がこちら。

テレビ放送よりも取材時のフッテージを追加したディレクターズカット版を作ってもらって、それがYouTubeで公開されています。とてもよくまとまっているのでご覧いただければ。
テレビ取材が第一回AIアートグランプリよりもこの時期に集中した理由は、おそらく「ビートルズ最後の新曲」のせい。「音楽、故人、AI」というキーワードに引っかかったのが筆者の事例、ということなんだと理解しました。

そしてここで西川和久さんによる新連載「生成AIグラビアをグラビアカメラマンが作るとどうなる?」がスタート。自分も西川さんの別媒体の記事で勉強していただけに、なんとも実用的な連載スタートに興奮しました。

7月:新連載「生成AIウィークリー」スタート
で、西川さんの連載に無理やり乗っかっていったコラムも。

生成AI用に、超縦長ディスプレイも購入しました。この後でさらに買い足して、現在、3枚の1メートル超級縦型ディスプレイを生成AI画像表示に活用しています。

そして、7月にはさらなる生成AIの新連載「生成AIウィークリー」が始まります。筆者が前職で編集を担当していた、Seamlessという論文紹介サイトの山下裕毅さんが、毎週月曜日に前週の重要生成AI論文5本をまとめて解説するというもの。「毎日がゲームチェンジャー」な生成AI界隈ですが、そのエッセンスをまとめ読みするのはこの連載が最適です。

8月:AnimateDiff、VALL-E X登場
Tune-A-Videoとはレベル違いのAIアニメーション技術「AnimateDiff」が登場します。一躍話題になり、AUTOMATIC1111でも実装されましたが、Memeplexで簡単に使えるようになったので試してみました。商用ソフトとしてRunwayのGen-2も使えるようになり、AIアニメーションの幅が大きく広がっています。

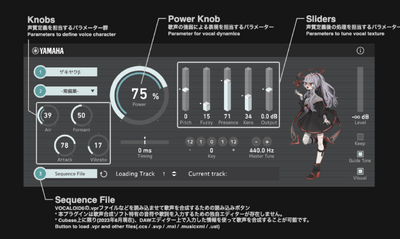
一方、AI音声合成では2つの大きな動きをレポートしました。まず、ヤマハのVOCALOID。VOCALOIDはすでにAI技術を組み込んでいますが、それとは異なる新しいラインの実験的プロダクトを無償で公開しました。それが、「VOCALOID β-STUDIO」。そのベータ版ユーザーに選ばれたので、試してみた記事も書きました。
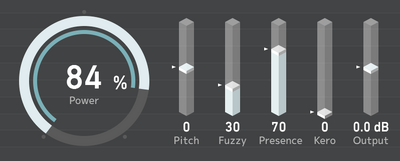
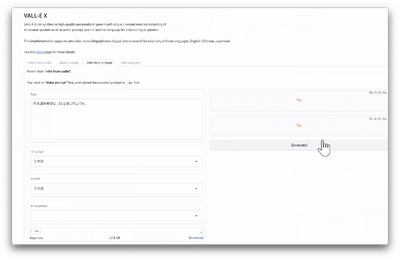
もう一つのAI音声合成技術は、以前マイクロソフトが発表したものの技術の公開は差し控えた「3秒の学習で本人そっくりの音声」を実装してしまった「VALL-E X」。推論に時間がかかるのが難点ですが、実際に使ってみて恐ろしさを感じるほどでした。
9月:より高度なリップシンク「HeyGen」、欠けた写真を甦らせるPhotoshop Firefly、バーチャルヒューマン
以前紹介したリップシンク技術「D-ID」は、口を開けすぎたり顔が横を向いたときの歪みが不自然だったりと、使い所が難しかったのですが、代替技術が2つ出てきました。一つはオープンソースの「SadTalker」。これはAUTOMATIC1111にも組み込まれているので簡単に使えます。もう一つの「HeyGen」はかなり精度が高く、これならば長尺のリップシンクでも違和感なく見ることができます。これを使って「時をかける少女」カバーを作ってみたという記事です(サムネの鶴書房版書籍はまったく注目されず)。

一方で、写真の修復にAIを使う技術も紹介しています。Adobeの生成AI技術であるFirefly。Photoshopの生成AI技術がベータ版ではなく正式版に実装されました。これを使って、妻の顔半分しか残っていない写真を完全なものにするという試み。これがうまくいったのです。驚きでした。

バーチャルヒューマンについての動きもまとめました。Epic GamesのMetaHuman Creatorと、Reallusion Character Creator Headshot Pluginについて紹介しています。Headshotによる、3Dプリンタ出力(等身大)も現在手がけています。

フジテレビ「Mr.サンデー」出演のアーカイブが公開されたので、それも貼っておきます(収録・放映は6月)。
10月:「生成AIグラビア実践ワークショップ」始動
10月は自分の原稿を書く余裕がとれず、その代わりに西川和久さん講師の生成AIグラビア実践ワークショップの準備をしていました。「生成AI GO」という、ブラウザでAUTOMATIC1111を使えるサービスを活用しながら、西川さんのプロンプトをすぐに試して保存までできちゃうという画期的な仕組み。筆者は月額1100円を支払っていますが、それが受講中は無料で使えます。ワークショップは毎月1回開催していますが、テクノエッジ アルファ会員なら追加料金なしで受講できるというお得なプランなので、これからStable Diffusion勉強したいという人も、上級者のテクニックを知りたいという人もぜひ。

11月:OpenAIの変とビートルズ新曲
11月にはOpenAIの開発者向けイベント「DevDay」が開催され、そこでより高性能なLLM「GPT-4 Turbo」、マルチモーダルを進化させた「GPT-4 Turbo with Vision」。さらに、GPTアプリのためのマーケットプレースを発表するなど数々の施策を打ち出しました。その後にはMicrosoftがOpenAIの技術をベースにしたCopilotを全面的に展開する発表を自社イベント「Ignite 2023」で行います。


しかし、その直後にOpenAI内紛が勃発してサム・アルトマン氏がCEOから追放。その後、マイクロソフトの支援を手に幹部社員ともどもMS傘下入りする話や、復帰を望む社員からの署名活動を経て、最終的に出戻ります。



アナウンスされていたビートルズ最後の新曲で、AI技術がどのように使われたかについての解説記事を書きました。

筆者が初代グランプリを取ったAIアートグランプリの第二回発表があったのもこの月です。快亭木魚さんによるグランプリ作品「明日のあたしのアバタイズ」については、NHKで詳しく記事にしているので、そちらを見るのがいいでしょう(記事にする予定でしたが書けずじまい)。これは発表日の夜に放映されたものをテキスト記事にしたものです。後半では自分への取材内容がまとめられています。
・AIは人間を“拡張”する~アートから見えてきた可能性~(NHK)
12月:作詞・作曲・演奏・歌唱まで全部丸ごとやってくれるAI「Suno」の衝撃
12月に入ると、GoogleのマルチモーダルネイティブなLLM「Gemini」が登場し、GPT-4超えの性能を持つというUltraも紹介しますが、一方でちょっとやり過ぎなデモ動画がちょっと問題を引き起こします。

そして12月最大の話題といえば、Suno。稼働していたのはもっと前で、ちょっと前から清水亮さんから教えてもらっていたのをやっと試してみた記事を出したところ、他のメディアも追随し、かなりの大ブームに。


そこから、UVR5によるAI音源分離、MIDIデータ抽出ソフトの紹介などもやりました。ChatGPTのマルチモーダル機能を使った、絵から歌詞を考えさせる試みもうまくいきました。
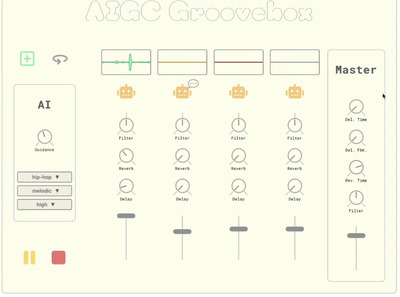

使い方記事はこちら。

しかし、ようやくまとめたと思ったら、さすがナディラ、おそろしい子。筆者の記事に気づいてなのか、Microsoft CopilotにSuno作曲機能を組み込んでしまいます。
こちらの使い方もまとめました。

SunoのAI作曲機能は、筆者の妻音源とりちゃん[AI]との取り組みにも役立っています。これまでカバー曲中心だった作品が、オリジナルのテーマを持った楽曲に広がりました。
2024年の1月から台湾の美術館でSuno作曲による作品を含めた展示が行われる予定です。
このほかにも、複数の映像化プロジェクトが動いています。1年を経て、AIを使った作品は、筆者のような美術文脈とは全く無関係の人物であっても「アート」となりうることが、ある意味実証されたのではないでしょうか。




