









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第35回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
拡散モデルで“モデルパラメータ”を生成する手法「P-diff」、Metaなどが開発
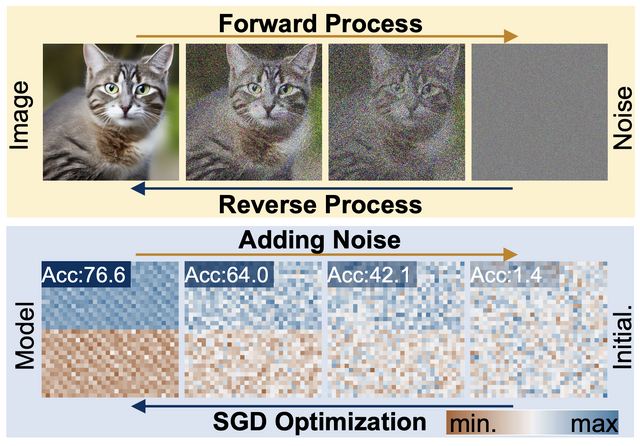
画像生成AIなどに活用されている拡散(Diffusion)モデルを使用して、ニューラルネットワークが学習や予測に使用するパラメータを生成するフレームワーク「P-diff」を提案しています。
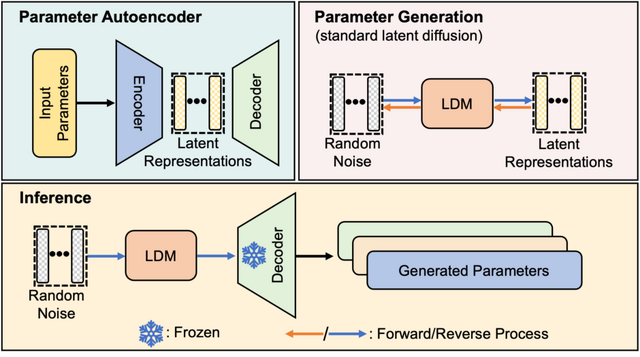
P-diffはオートエンコーダと標準的な潜在拡散モデルを組み合わせたものに基づいています。オートエンコーダは訓練済みネットワークのパラメータから潜在表現を抽出し、その後、潜在拡散モデルがこの潜在表現をランダムノイズから合成して新しいパラメータ表現を生成します。この新しい表現はオートエンコーダのデコーダ部分を通過し、使用可能な新しいネットワークパラメータのサブセットとして出力されます。
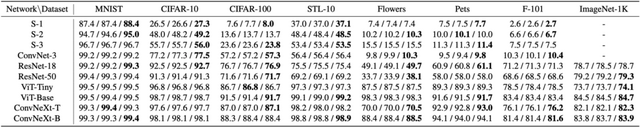
実験を通じて、研究チームは様々なアーキテクチャとデータセットにわたって、訓練済みネットワークと同等またはそれ以上の性能を持つモデルを一貫して生成できることを実証しました。
このプロセスは追加コストを最小限に抑えつつ行われます。興味深いことに、生成されたモデルは訓練済みネットワークとは異なる性能を示しました。これは、拡散モデルが訓練データを単に記憶するのではなく、新しいパラメータの組み合わせを創出できることを意味しています。
Neural Network Diffusion
Kai Wang, Zhaopan Xu, Yukun Zhou, Zelin Zang, Trevor Darrell, Zhuang Liu, Yang You
Project | Paper | GitHub
過去最高精度のリアルタイム物体検出器「YOLOv9」、台湾の研究者らが開発
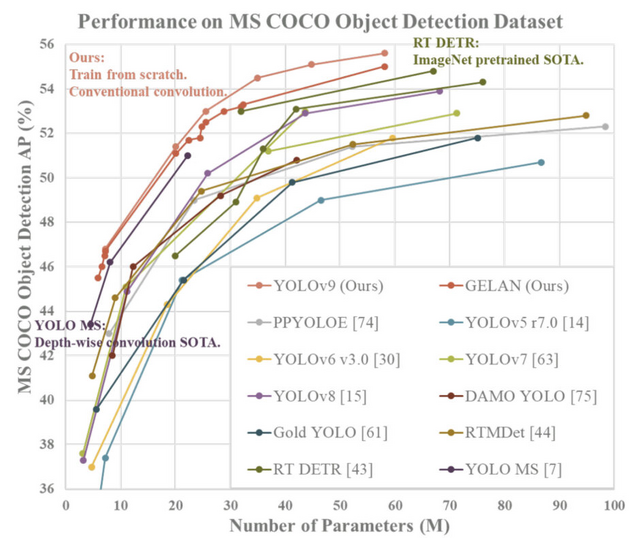
研究チームの報告によると、MS COCOデータセットにおけるベンチマークテストでは、提案されたモデルであるリアルタイム物体検出器「YOLOv9」が、YOLOv8を含む既存の物体検出モデルよりも高い精度を達成したことを示しました。
より強力なシステムアーキテクチャ(例えばCNNやトランスフォーマーなど)がしばしば直面する問題として、データがネットワークを通過する過程で情報が失われることがあり、この情報損失はモデルが不正確な予測をする原因となることがあります。
この問題に対処するため、「Programmable Gradient Information」(PGI)というアプローチを提案します。PGIはデータ損失を防ぎ、正確な勾配を保証することで、追加のコストなしに、さまざまなサイズのネットワークに適用可能です。
さらに、勾配経路計画に基づく新しい軽量ネットワークアーキテクチャ「Generalized Efficient Layer Aggregation Network」(GELAN)を提案します。GELANの設計は、パラメータの数、計算の複雑さ、精度、推論速度を同時に考慮しています。
これらの提案されたPGIとGELANを組み合わせて設計された新しいYOLOシリーズの物体検出システム「YOLOv9」は、MS COCOデータセットを使用した実験において、全ての比較でトップの性能を達成しました。
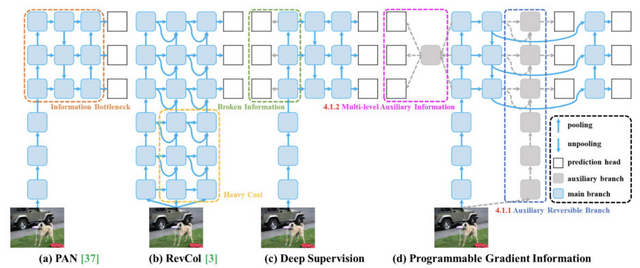
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
Paper | GitHub
音声、テキスト、画像、音楽などを統合して理解できるマルチモーダルモデル「AnyGPT」
マルチモーダル理解では、多くの場合、画像やオーディオなどの単一の非テキストモダリティのみが統合されています。テキストと1つの追加モーダリティの整合は比較的容易ですが、複数のモダリティを単一のフレームワーク内で統合し、それら間で双方向の整合を達成することは、より大きな課題です。
AnyGPTは、音声、テキスト、画像、音楽など、さまざまなモダリティを統一的に処理するマルチモーダル言語モデルです。このモデルは、現在の大規模言語モデル(LLM)のアーキテクチャや訓練手法を変更することなく、安定して訓練することが可能です。代わりに、データレベルの前処理にのみ依存し、新しいモダリティをシームレスに統合することを容易にします。
例えば、テキスト+画像を入力としてテキスト+音楽を出力したり、音声を入力としてテキスト+画像+音楽+音声を出力したり、音声+音楽を入力としてテキスト+画像+音声応答を出力するなど、入出力ともに異なる複数のモダリティを一度に扱うことができます。
このプログラムの特徴は、異なる種類の情報を共通の形式に変換して処理することです。これは、異なる言語を翻訳する際に共通言語を介して行うプロセスに似ています。例えば、画像や音声も、プログラムが理解しやすい「言語」に変換してから処理します。この方法により、AnyGPTは、従来のLLMよりも多くの種類の情報を扱うことが可能になります。
さらに、AnyGPTは、「AnyInstruct-108k」という新しいデータセットを作成して学習します。このデータセットには、テキスト、画像、音声などが複雑に組み合わさった10万8000件以上のサンプルが含まれており、プログラムがさまざまな情報を組み合わせて理解する能力を高めます。
AnyGPTの実験結果は、様々なモダリティにわたる理解と生成タスクで有望な結果を達成したことを示しています。具体的には、画像キャプション、テキストから画像への生成、音声認識、テキストから音声への変換、音楽理解などのタスクで評価されました。AnyGPTはこれらのタスクでゼロショット性能を発揮し、特定のモダリティに特化したモデルと比較して競争力のあるパフォーマンスを示しました。
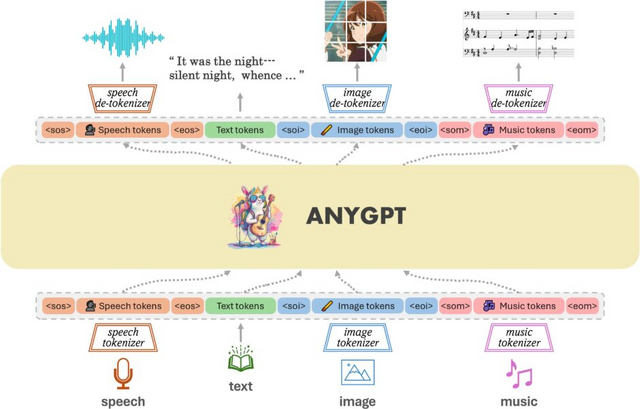
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yugang Jiang, Xipeng Qiu
Project | Paper | GitHub
大規模言語モデルのコンテキストウィンドウを200万トークン以上に拡張できる「LongRoPE」、Microsoftが開発
大規模言語モデル(LLM)のコンテキストウィンドウを200万トークン以上に拡張する手法「LongRoPE」がMicrosoftから提案されました。この手法では、事前訓練されたLLMのコンテキストウィンドウを204万8000トークンまで拡張し、ファインチューニングステップを最大1000回、トレーニング長を25万6000トークン以内に抑えることで、元の短いコンテキストウィンドウでのパフォーマンスを維持することができます。
この成果は、3つの主要なアプローチによって実現されています。まず、文章の各部分が持つ独自の特性を理解し、それに基づいてモデルが文章をどのように処理するかを最適化することで、ファインチューニングのためのより良い初期化を提供し、ファインチューニングを行わないシナリオで8倍の拡張を可能にします。
次に、25万6000トークン長のLLMを最初にファインチューニングし、その後ファインチューニングされた拡張LLMに対して二次的な位置補間を行い、204万8000トークンのコンテキストウィンドウを実現します。最後に、短いコンテキストウィンドウでのパフォーマンスを回復するために、LongRoPEを8000トークン長に再調整します。
実験結果によると、LongRoPEにより拡張されたモデルは、元の短いコンテキストウィンドウ用に設計された標準ベンチマークタスクにおいて、元のモデルと比較して同等またはそれ以上の性能を発揮しました。また、数百万トークンの中から特定のパスキー(5桁の数字)を検索するタスクにおいて、4kから2048kまでの範囲で90%以上の高い精度を達成しました。
LongRoPEはLLaMA2やMistralなど、異なる大規模言語モデルに適用可能であり、これらのモデルを用いた実験でもLongRoPEの有効性が確認されました。
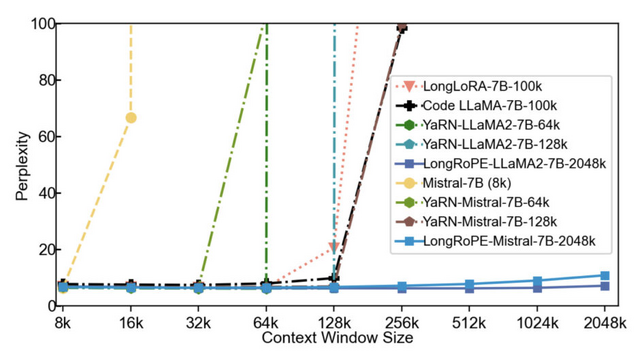
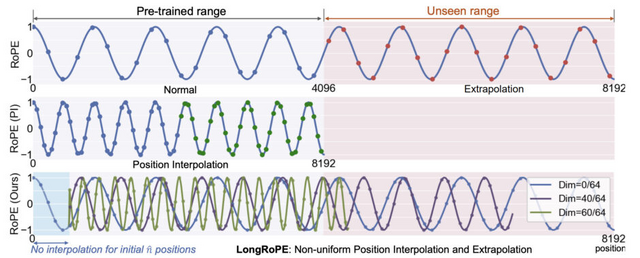
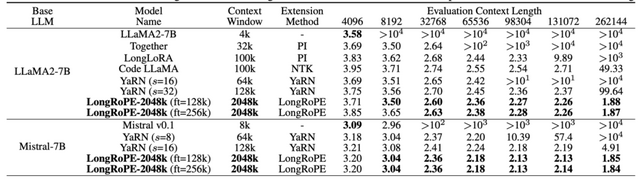
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, Mao Yang
Paper | GitHub
1024×1024の高解像度画像を高速に生成するモデル「SDXL-Lightning」、ByteDanceが開発
SDXL-Lightningは、高品質な1024×1024ピクセルの画像を高速で生成できるオープンソースの画像生成モデルです。このモデルはSDXLから蒸留され、品質を維持しながら1ステップまたは数ステップの推論で高品質な画像を生成することが可能です。モデルはLoRAおよび完全なUNetの重みとしてオープンソース化されています。
実現するために、プログレッシブ蒸留と敵対的蒸留を組み合わせた新しい手法を用いています。プログレッシブ蒸留は、教師モデルから生徒モデルへ知識を段階的に伝達するプロセスで、この方法では生徒モデルが教師モデルが実行した複数ステップ後の流れの位置を直接予測するように訓練されます。
敵対的蒸留は、敵対的訓練の原理を拡散モデルの蒸留プロセスに適用したものです。このアプローチでは、生徒モデルが生成したサンプルと教師モデルが生成したサンプルを区別しようとする識別器を用いて、生徒モデルの訓練を行います。このプロセスを通じて、生徒モデルは教師モデルに近い品質の画像を生成できるようになります。
これら2つの技術を組み合わせることで、1ステップ、2ステップ、4ステップ、8ステップで高品質な画像を生成できるようになります。SDXL-TurboやLCMといった他のオープンソースモデルと比較して、この方法が全体的な品質と詳細で著しく優れていることが示されています。また、元のモデルのスタイルとレイアウトを保持する点でも優れています。4ステップおよび8ステップモデルは、32ステップの元のSDXLモデルをしばしば上回ることを示しました。


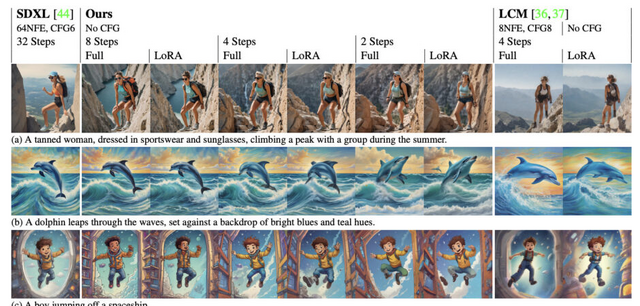


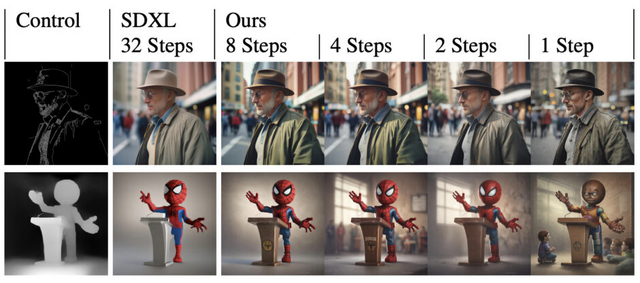
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Shanchuan Lin, Anran Wang, Xiao Yang
Paper | Hugging Face | Demo




