

1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第44回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
マイクロソフトがスマホ上でローカル実行可能な小規模言語モデル「Phi-3」を発表
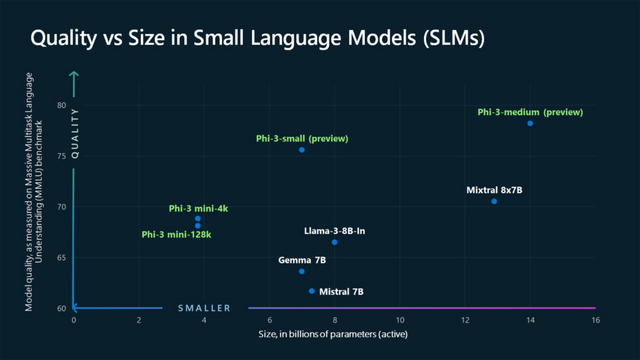
Microsoftは小規模言語モデル(SLM)「Phi-3」ファミリーを発表しました。第一弾として、38億パラメータの言語モデルである「Phi-3-mini」が利用可能になっています。phi-3-miniは、トランスフォーマーを基にしており、3.3兆トークンのデータセットで訓練されています。
そのサイズはスマートフォンに実装可能なほど小さく、性能は「Mixtral 8x7B」や「GPT-3.5」といった大型モデルに匹敵します。特に、「MMLU」で69%、「MT-bench」で8.38のスコアを達成しており、高性能ながらも省スペースのモデルとしての可能性を示しています。
デフォルトのコンテキスト長は4Kですが、より長いコンテキストを扱うためのバージョンとして、「phi-3-mini-128K」も導入されています。
さらに、Phi-3-miniはスマートフォン上でローカルに動作可能で、実験でもiPhone 14のローカル環境でテストされ実証されています。
Microsoftは、Phi-3ファミリーの追加モデルとして、近日中に「Phi-3-small」 (70億パラメータ) と「Phi-3-medium」 (140億パラメータ) をリリースする予定です。
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Olatunji Ruwase, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yunan Zhang, Xiren Zhou
Paper | Hugging Face | Blog
アップル、iPhone上でも動作可能な大規模言語モデル「OpenELM」をオープンソースで発表
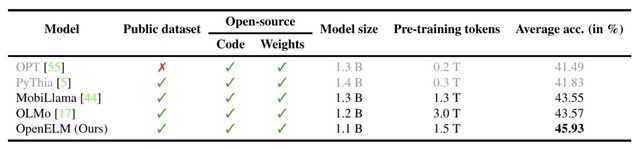
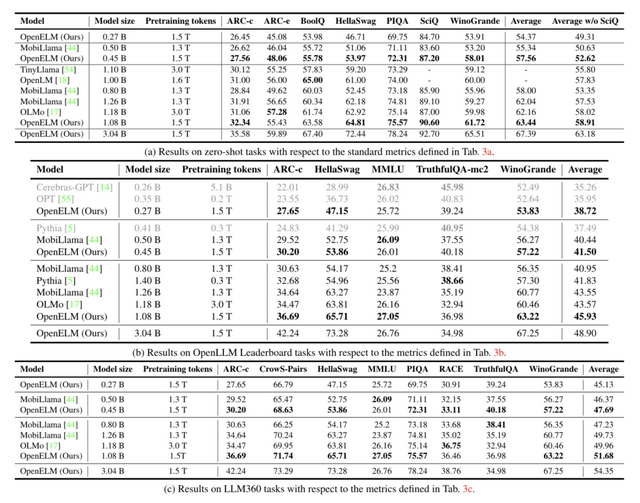
Appleは大規模言語モデル「OpenELM」を発表し、モデルの重みだけでなくトレーニングコードやデータセットもすべてオープンソースで公開しました。OpenELMはパラメータ数によって異なる4つのモデル(2億7000万、4億5000万、11億、30億)が提供されています。
OpenELMは、効率的なパラメータ割り当てを可能にするレイヤー単位のスケーリング手法を用いたTransformerを採用。これにより、同程度のパラメータ数を持つ既存のモデルと比べて精度が向上しています。例えば、11億パラメータを持つOpenELMは、12億パラメータを持つOLMoよりも2.36%高い精度を達成しました。さらに、OpenELMはOLMoの半分の事前学習トークン数で学習されています。
訓練に使用するデータセットには、RefinedWebやPILE、RedPajama、Dolma v1.6が含まれており、合計で約1.8兆トークンで構成されています。
iPhoneなどのスマートフォンやMacなどのノートPCでも動作するように、モデルをMLXライブラリに変換するコードも提供しています。
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari
Paper | GitHub | Hugging Face
OpenAI、大規模言語モデルへの攻撃を防ぐ手法「The Instruction Hierarchy」を発表
大規模言語モデル(LLM)はプロンプトインジェクション攻撃と呼ばれる脆弱性を抱えています。これは、悪意のあるユーザーが巧妙に作られたプロンプトを入力することで、LLMに本来意図しない動作をさせてしまう攻撃手法です。
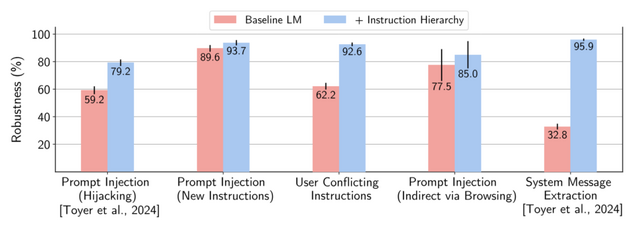
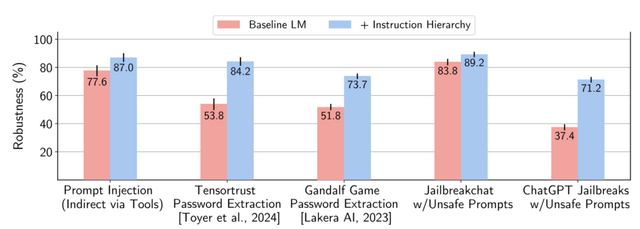
この問題に対処するため、OpenAIの研究チームは「The Instruction Hierarchy」と呼ばれる新しい防御手法を提案しました。この手法の基本的なアイデアは、LLMに対する入力を重要度に応じて階層化し、優先順位の高い指示と矛盾する低い指示は無視するよう学習させるというものです。
具体的には、まず(1)開発者が設定するシステムメッセージ(最高優先度)、(2)ユーザーからの入力(中優先度)、(3)インターネット検索結果やAPIのクエリ結果など、外部からの情報(低優先度)の3つに分類します。
そして、低優先度の指示が高優先度の指示と矛盾する場合は、低優先度の指示を無視するようLLMを学習させます。例えば、システムメッセージで「有害なコンテンツを生成してはいけない」と指示されている場合、たとえユーザーが「有害なコンテンツを生成しろ」と指示しても、LLMはそれを無視します。
研究チームは、この手法の学習に必要なデータを自動生成する手法も開発しました。さらに、GPT-3.5をベースにこの手法を適用したモデルを作成し、各種の攻撃手法に対する頑健性を評価したところ、防御率が最大63%向上し大幅な改善が見られたとのことです。

The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, Alex Beutel
Paper
あらゆる音声を複製し、多言語でさまざまな内容を話させるAIモデル「OpenVoice V2」。日本語対応、無料で商用利用可能なオープンソース
2024年1月に発表された、短い音声クリップから参照話者の声を模倣し、さまざまな言語で異なる内容の音声を生成できる音声クローンAI「OpenVoice」のバージョンアップ版「OpenVoice V2」がリリースされました。完全にオープンソースであり、MITライセンスに基づき無料で商用利用が可能です。
OpenVoiceは参照話者の声を単純に再現するだけでなく、感情、アクセント、リズム、イントネーションなど、声のスタイルを細かく制御できる点が特徴です。
OpenVoice V2では、英語、スペイン語、フランス語、中国語、日本語、韓国語がネイティブにサポートされています。そのため、自分の声質のまま別の言語に変換することも可能です。OpenVoice V2では、より優れた音声品質を提供する異なるトレーニング戦略を採用しています。


OpenVoice: Versatile Instant Voice Cloning
Zengyi Qin, Wenliang Zhao, Xumin Yu, Xin Sun
Project | Paper | GitHub
Web上の大量画像とテキストを使って、高速かつ高精度に画像認識AIを学習する新手法「CatLIP」をAppleが開発」
インターネット上には大量の画像とその説明文があります。それらを使ってAIに画像の特徴を学習させる手法が注目されていますが、画像とテキストの関連性を計算するのに膨大な時間がかかるのが課題でした。
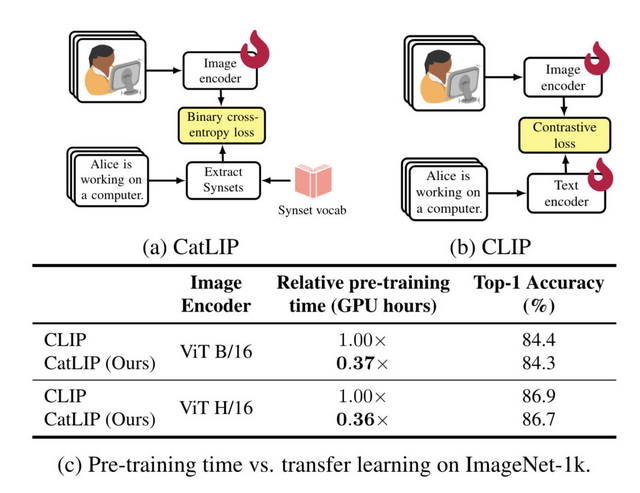
この論文で提案されている新しいAI学習法「CatLIP」は、画像認識の事前学習を分類タスクとして扱うことで、画像-テキスト間の計算を高速化しました。
具体的には、テキストデータから単語の意味を抜き出して「Synset」(単語の意味カテゴリ)を作ります。次に、ViTなどのモデルで画像をベクトル化し、そのベクトルかSynsetへの分類スコアを計算します。これにより、画像とテキストの細かい対応付けが不要になり、計算コストを大幅に下げられます。
CatLIPによる学習速度は従来手法(CLIP)の2.7倍に高速化しました。しかも、長時間学習を続けても精度が頭打ちにならず、従来手法の4分の1の計算量で同等の性能を実現しました。
また、CatLIPで学習したAIを別の画像認識タスクに転用したところ、少ないデータでも効率よく性能を発揮することが確認されました。これにより、汎用性の高い画像認識AIを高速に学習できます。