


アップルが打ち出したAIフレームワーク「Apple Intelligence」ですが、個々の機能についてはわかるものの、全体像がつかみにくいものになっています。
OpenAIのサム・アルトマンCEOがApple Parkに顔を出していたことからApple IntelligenceはChatGPTを借りただけみたいな誤解が生まれたりもしていますが、AppleのAIへの取り組みが実はいいところを突いているのではないかという指摘も上がってきています。
Private Cloud Computeが重要であると。Apple Intelligenceはオンデバイスとクラウドの2段階構成になっていて、そのクラウド部分がAppleシリコンサーバで組まれたPrivate Cloud Compute(PCC)。その詳細が、セキュリティブログで説明されています。その概要をNotebookLMでまとめてみました。
ユーザーのプライバシーを保護するために、PCCはユーザーのデバイスから送信された個人データへのアクセスをユーザー自身以外には許可せず、Appleでさえアクセスできないように設計されています。
この高いレベルのプライバシーを達成するために、PCCはステートレスな計算、アクセス権の厳格な制限、システムの透明性の確保など、いくつかの重要なセキュリティとプライバシーの原則に基づいて構築されています。
さらにAppleは、セキュリティ研究者がPCCのセキュリティとプライバシーの保証を検証できるように、PCCのソフトウェアイメージと検証ツールを公開することを約束しています。
これは、クラウドベースのAI処理におけるユーザープライバシーの保護に対するAppleの取り組みを示すものです。
オンデバイスの部分の解説がないかと探したところ、Platforms State of the Unionにありました。
Platforms State of the Unionは、WWDCでは基調講演の後に開催される恒例のイベントで、発表内容をデベロッパー向けにもっと詳しくまとめたものです。WWDCの本番は基調講演ではなく、ここから、というのが通例となっています。
Apple Intelligenceについてはその開発経緯から、Intelligent System Experience Engineering担当VPのSebastien Marineau-Mes氏による解説がされていました。ちなみにこの方は元BlackBerryで、アップルに転職する際に古巣から訴えられてしまった経緯を持つ人でもあるようです。
アップルはこれまで機械学習をAppleシリコン上で安全かつ高速に走らせてきましたが、大規模言語モデル(LLM)の登場に対応する必要がありました。しかし、そのために高性能でありながらiPhoneのようなデバイスで動かせる、小さなモデルでなければなりません。
そのためにどうしたか。
■オンデバイス用小型LLMの開発手法
まず、Foundation modelという基盤になるLLMを開発し、それを特定処理に役立つよう、サイズは小さく、高速化つ省電力で動作するよう最適化します。

アップルの発表資料によれば、サイズは3B未満とされています。かなり小さなモデルですね。
アップルは4月にOpenELMという言語モデルをオープンソース公開しており、そのうち最小のものは2.7Bなので関係あるのかもしれませんが、外部LLMをアプリで利用する際の例としてOpenELMを挙げているためイコールではないようです。ちなみにOpenELM 2.7Bはドラえもんのことは知らないようです。
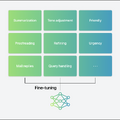
この小さいFoundation modelにファインチューニングを行います。テキストの概要作成、校正、メールの返信といった用途別に多大な時間をかけて学習していきます。これらのモデルはそれぞれの用途に特化しています。
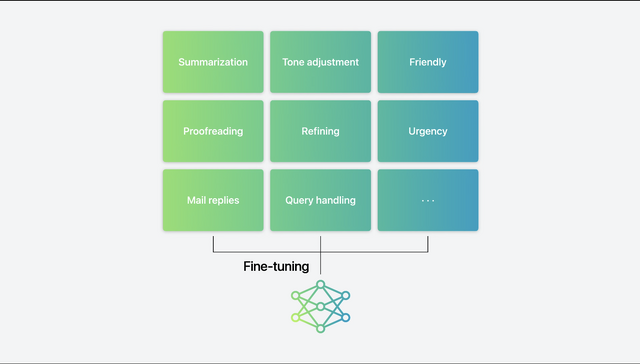
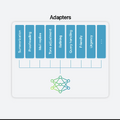
次に、これらの学習モデルをFoundationモデルの上にダイナミックにロードしたりスワップしたりするAdaptersという手法を適用。タスクによって、使用するモデルを動的に換えていくわけです。
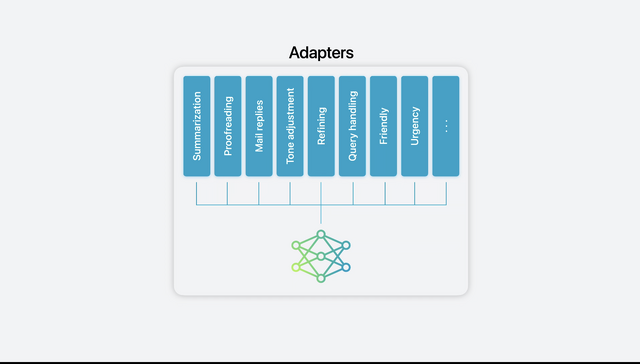
次に行ったのは圧縮。量子化技術により1パラメータあたり16bitのモデルを1パラメータあたり平均4bit未満に圧縮し、M1以上、A17以上という推論性能でも処理できるようになっています。
最後に、推論の性能と効率を向上させます。プロンプトを受け取ってから回答するまでの時間を最短にするということです。このために、投機的デコーディング、コンテキストの枝刈り、グループクエリアテンションなどの技術を取り入れました。
オンデバイスで動くAIモデルはLanguage(言語モデル)とImages(画像モデル)の2つに大きく分かれており、その中で用途によりさらに細分化されています。これらを動的に呼び込むことにより、限られた処理能力の中でタスクを実行しているというわけです。
Private Cloud Computeの解説では、サーバの安全性を確保するために一貫性のあるストレージ、リモートシェルを排除した構造となっているというのも興味深かったです。Foundation modelはオンデバイスのものより大きいものだとしていますが、サイズについての言及は見つけられませんでした。

不要な機能を削ぎ落とした上で、デバイスとセキュアなやり取りができるような方策をとっています。

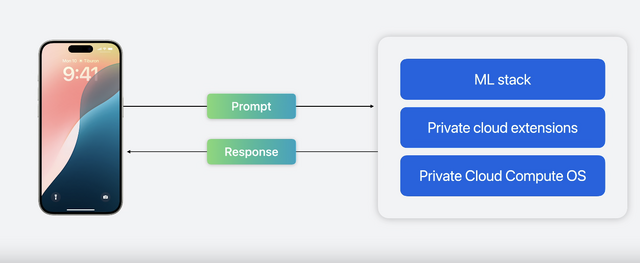
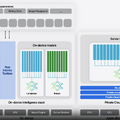
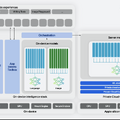
■Private Cloud Computeを含めたApple Intelligenceの全体構成
Private Cloud Computeを含めたApple Intelligence全体の構成は次のようになっています。ChatGPTとの連携は、この中では図示されていません。
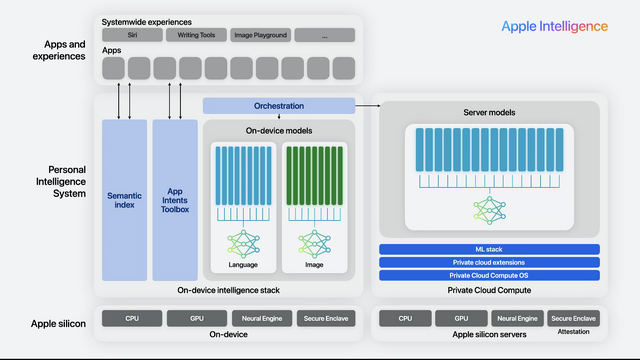
(▲Apple Intelligenceの全体像)
Platforms State of the Unionに出てきた話でもう一つ興味深かったのが、別のLLMをApple Intelligenceの枠組みで動かせることです。

Whisper、Stable Diffusion、Mistral、Lhama、OpenELMなどのPyTorchベースのAIモデルはCore MLでパッケージ化することで、4bit量子化や、効率的キーバリューキャッシングの恩恵を受けられ、CPU、GPU、Neural Engineに最適化された動作が可能です。
というふうにApple Intelligenceについてつまみ食いしてきましたが、これらのFoundation model(基盤モデル)について、より詳細な解説をnpakaさんがまとめてくれていますので、興味のある方はどうぞ。
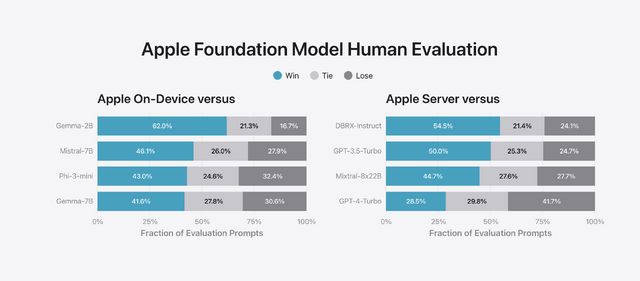
この記事の元になった「Introducing Apple’s On-Device and Server Foundation Models」という資料によれば、オンデバイス版の性能は、それぞれマイクロソフトのPhi-3 mini、Gemma 7B、Mistral 7Bに相当。サーバ版はGPT-4 Turboに迫るという、なかなかの結果を引き出しています。