
1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、生成AIモデルが検索で引用する情報が誤ったものが多いことを指摘した米コロンビア大学のTow Center for Digital Journalismによる2025年3月発表の研究を取り上げます。
現在、アメリカ人の約4分の1がAI検索ツールを従来の検索エンジンの代わりに使用しているとされています。
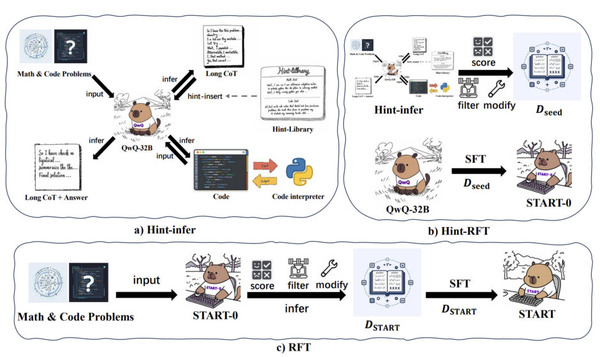
研究チームは、ニュースコンテンツを正確に検索し引用する能力を評価するため、リアルタイム検索機能を持つ8つの生成型検索ツール(ChatGPT、Perplexity、Perplexity Pro、Copilot、Gemini、DeepSeek、Grok 2、Grok 3)をテストしました。
20の出版社から各10記事をランダムに選び、それらの記事から抜粋を手動で選択してクエリとして使用しました。各チャットボットに抜粋を提供し、対応する記事の見出し、元の出版社、発行日、URLを特定するよう依頼し、合計1600のクエリを実施しました。

▲出版社20から各10記事をランダムに選び、その抜粋を各チャットボットに提供して対応する記事の見出し、元の出版社、発行日、URLを特定するよう依頼
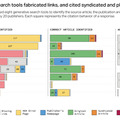
調査の結果、これらのチャットボットは全体として60%以上のクエリに対して不正確な回答を提供することがわかりました。Perplexityはクエリの37%に誤った回答をした一方、Grok 3は94%という高いエラー率を示しました。
多くのツールは、「~のようです」「可能性があります」などの限定的な表現をほとんど使用せず、知識の不足を認めることもなく、驚くほど自信を持って不正確な回答を提示しました。例えばChatGPTは、134の記事を誤って特定しましたが、200の回答のうち自信のなさを示したのはわずか15回で、回答を拒否することは一度もありませんでした。
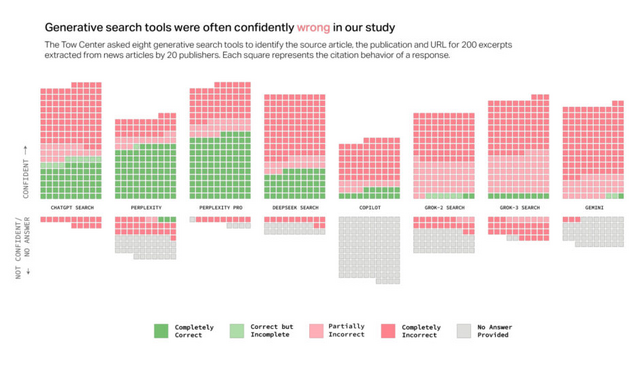
▲8つのチャットボットにおいて、上段が自信がある回答で下段が自信がない回答。赤が間違えた内容で緑が正解した内容。各四角は1つの回答を表している。
興味深いことに、Perplexity Pro(月額20ドル)やGrok 3(月額40ドル)などの有料モデルは、対応する無料版よりも多くの質問に正確に答える一方で、より高いエラー率も示しました。この矛盾は主に、質問に直接答えるのを避けるよりも、決定的だが間違った回答を提供する傾向があるためです。
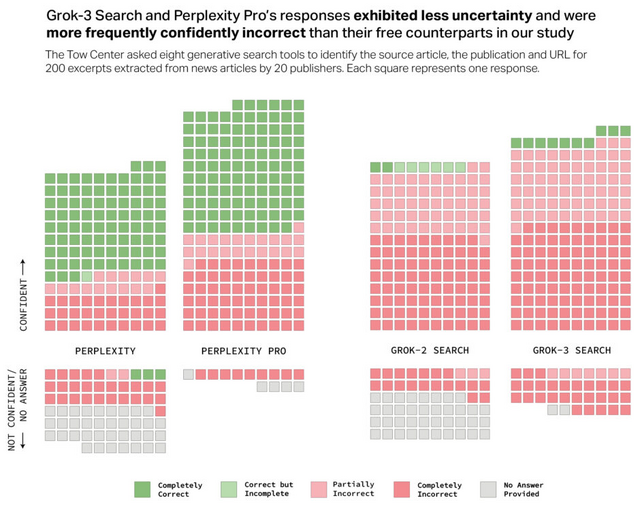
▲Grok-3 SearchとPerplexity Proの有料版の回答は、無料版と比較して自信を持って不正確な回答をより頻繁に示す
さらに、テストされた8つのチャットボットのうち5つ(ChatGPT、Perplexity、Perplexity Pro、Copilot、Gemini)はクローラーの名前を公開しており、出版社がそれらをブロックする選択肢を提供していますが、残りの3つ(DeepSeek、Grok 2、Grok 3)は公開していません。研究者らは、チャットボットがクローラーにアクセスを許可している出版社に関するクエリには正確に回答し、コンテンツへのアクセスをブロックしているウェブサイトに関するクエリには回答を拒否することを期待していました。しかし実際にはそうではありませんでした。
特にChatGPT、Perplexity、Perplexity Proは、クローラーのアクセス状況を考えると予想外の動作を示しました。コンテンツへのアクセスを許可している出版社に関するクエリに対して、不正確に回答したり回答を拒否したりすることがある一方で、アクセスできないはずの出版社に関するクエリに正確に回答することもありました。
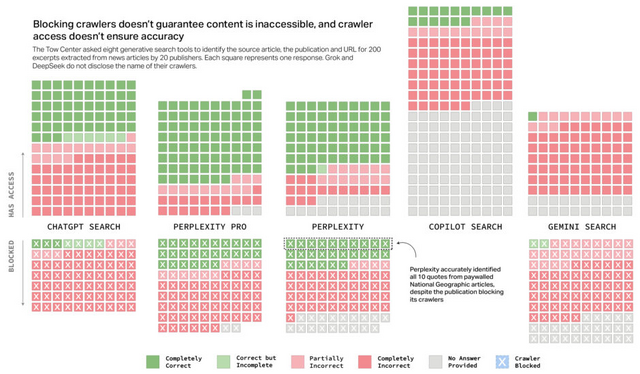
▲上段はクローラーのブロックなし、下段がブロックあり。緑が正解で、赤が不正解。
Perplexity Proはこの点で最も問題が多く、アクセスできないはずの90の抜粋のうち約3分の1を正確に特定しました。驚くべきことに、Perplexityの無料版は、クローラーを許可しておらずAI企業との正式な関係もないNational Geographicの有料記事から共有した10の抜粋をすべて正確に特定しました。
他方で、GeminiとGrok 3は回答の半数以上で偽造されたURLや機能しないリンクを提供していることが判明しました。特にGrok 3では、200のプロンプトに対する回答のうち154もの引用が存在しないエラーページへと誘導していました。Grokは記事を正確に特定できた場合でさえ、架空のURLを提供する傾向がありました。
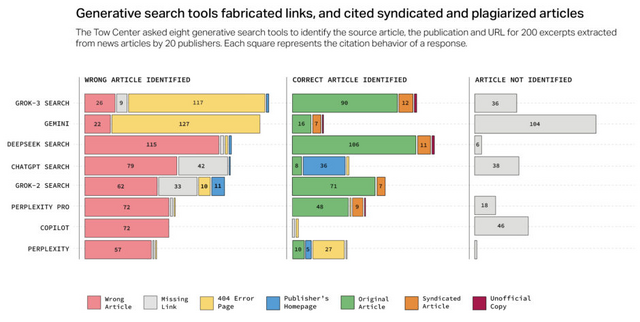
▲エラーページや偽のリンクを作成し、転載記事や盗用記事を引用していた
また、チャットボットは多くの場合、元の記事ではなくYahoo NewsやAOLなどのプラットフォームに転載されたバージョンを引用していました。さらに問題なのは、出版社がAI企業とライセンス契約を結んでいる場合でもこのような誤った引用が発生していたことです。
例えば、Texas Tribuneとのパートナーシップがあるにもかかわらず、Perplexity Proは10件のクエリのうち3件でTexas Tribune記事の転載バージョンを引用し、Perplexityは1件で非公式に再公開されたバージョンを引用していました。このような傾向は、オリジナルのコンテンツ制作者から適切な帰属や潜在的な参照トラフィックを奪う結果となっています。

▲Texas Tribuneと提携しているにもかかわらず、Perplexity は非公式バージョンの記事を引用した。