

Googleが大規模言語モデル(LLM)の最新バージョン「Gemma 3」を発表しました。1B、4B、12B、27Bのパラメータ数を持つバリエーションが公開され、マルチモーダル対応、128kのロングコンテキスト、140言語以上の多言語対応、数学やコーディングタスクの性能向上などの特徴があります。
またGoogleは、「Gemini 2.0 Flash」において、テキストの指示から直接画像を生成する機能を開発者向けに公開しました。画像に対しての細かな変更もテキストででき、出力結果の一貫性の高さがSNS上でも一部話題になっていました。
さらにGoogleの「Deep Research」が無料ユーザーでも使えるようになりました。この機能には「2.0 Flash Thinking Experimental」のアップグレード版が搭載されており、検索から分析、レポート作成までのプロセスが強化されています。
加えて、Googleはデジタル領域で開発を進めてきたAI技術をロボティクスに応用したGemini 2.0をベースにした「Gemini Robotics」も発表しました。より優れた推論、インタラクティブ性、器用さなどの機能を物理世界に提供します。
Transformerを開発した1人であるエイダン・ゴメス氏がCEOのAIチーム「Cohere」が、生成AIモデル「Command A」を発表しました。GPU2個で動作するにもかかわらず、GPT-4oやDeepSeek-V3と同等以上の性能を示すといいます。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第87回)では、声の高さや話す速度も調整可能な高度なテキスト読み上げシステム「Spark-TTS」や、3DビデオゲームをAIがプレイできるようにするフレームワーク「PORTAL」を取り上げます。
また、リアルタイムで画像内のあらゆる物体を認識してセグメンテーションできるAIモデル「YOLOE」や、動画内の人物を好きなキャラクターに入れ替えられるなどの複雑な動画編集が可能な動画AI「VACE」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、人工知能を促進することを目的とした国際的な学術団体「AAAI」が発表したレポートで書かれている“AGI”に関する事柄を単体記事で取り上げています。

3DビデオゲームをAIがプレイできるようにするフレームワーク「PORTAL」を中国テンセントが開発
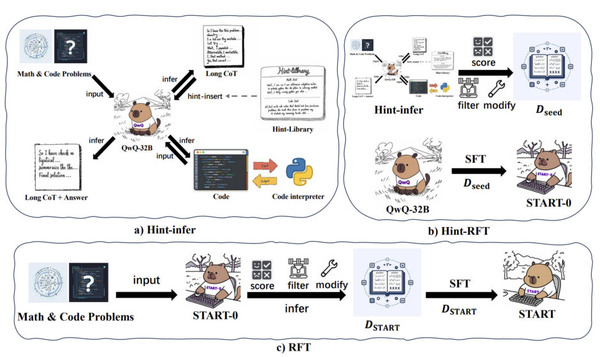
AIエージェントが3Dビデオゲームをプレイできるように学習するフレームワーク「PORTAL」を発表しました。
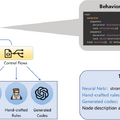
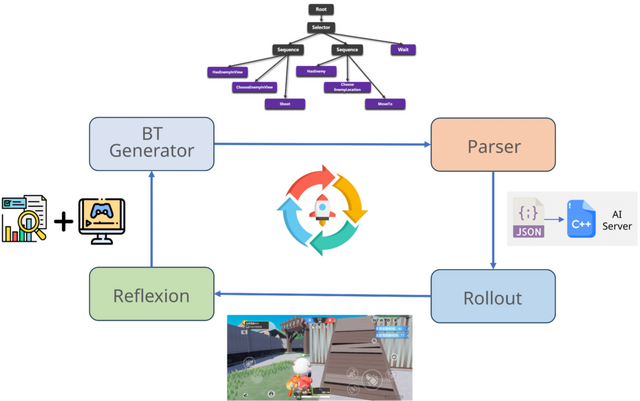
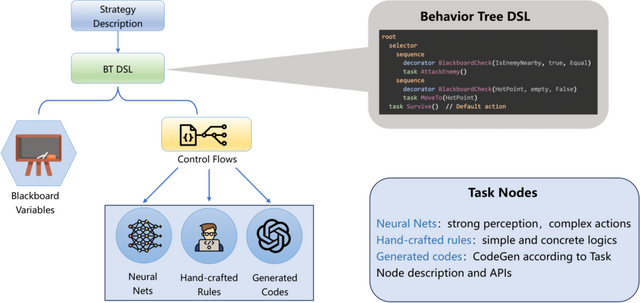
このシステムは大規模言語モデルを使って、ゲーム内での意思決定を行う「行動木」(Behavior Tree)を自動生成し、AIが数千もの異なる3Dゲームで効率的にプレイできるように設計されています。この方法では、従来の強化学習で必要だった何週間もの訓練時間や大量のコンピュータリソースが不要になります。
特徴的なのは、ルールベースの処理とニューラルネットワークを組み合わせたハイブリッド構造にあります。高レベルの戦略的判断を行う部分と、細かい操作を実行する部分を効果的に連携させることで、複雑なゲーム環境での行動を実現しています。また、ゲームの定量的な成績データとビジョン言語モデルによる分析を組み合わせたフィードバックシステムにより、AIが継続的に戦略を改善できる仕組みも導入されています。
実験では、数千のファーストパーソンシューター(FPS)ゲームにおいてPORTALの有効性が実証され、従来の手法と比較して開発効率、ポリシーの一般化能力、行動の多様性において大幅な改善が示されました。

Agents Play Thousands of 3D Video Games
Zhongwen Xu, Xianliang Wang, Siyi Li, Tao Yu, Liang Wang, Qiang Fu and Wei Yang
Project | Paper
リアルタイムで画像内のあらゆる物体を認識してセグメンテーションできるAIモデル「YOLOE」
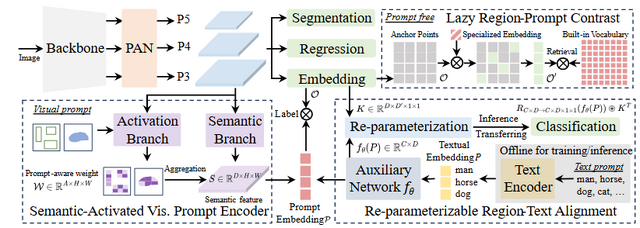
清華大学の研究チームが開発した「YOLOE」は、リアルタイムで物体検出とセグメンテーションを行える新しいAIモデルです。従来のモデルはあらかじめ定義されたカテゴリのみを認識する制限がありましたが、YOLOEはテキストや視覚的手がかりなどで様々な物体を認識できます。
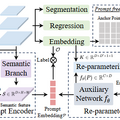
このモデルは既存のYOLOアーキテクチャをベースに、3つの技術を導入しています。「Re-parameterizable Region-Text Alignment」でテキスト処理を効率化し、「Semantic-Activated Visual Prompt Encoder」で視覚的手がかりを処理します。さらに「Lazy Region-Prompt Contrast」により、プロンプトなしでも物体を検出して名前を付けられます。
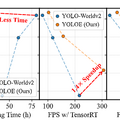
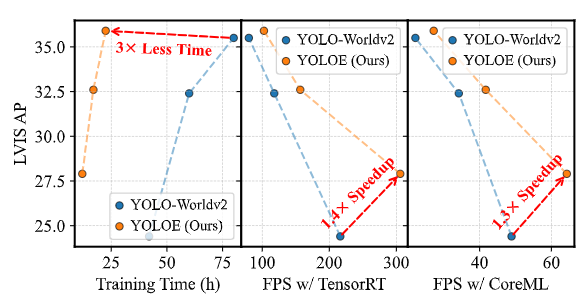
実験ではYOLOEは同様のモデルと比較して優れた性能を示し、YOLOE-v8-Sは3倍少ないトレーニング時間でYOLO-Worldv2-Sを上回り、推論速度も1.4倍速くなっています。また、モバイルデバイスでも効率的に動作します。

YOLOE: Real-Time Seeing Anything
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, Guiguang Ding
Paper | GitHub
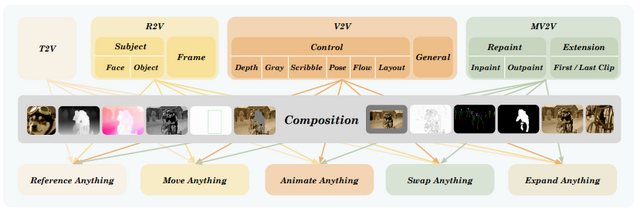
中国アリババの新たな動画AI「VACE」、動画内の人物を好きなキャラクターに入れ替えられるなど複雑な動画編集が可能
アリババグループのTongyi Labが開発した「VACE」は、ビデオ生成と編集のためのAIフレームワークです。
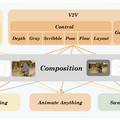
VACEは主に4つの基本機能を持っています。テキストからビデオを作る機能、参照画像をもとにビデオを生成する機能、ビデオ全体を編集する機能、そして特定の部分だけを編集する機能です。
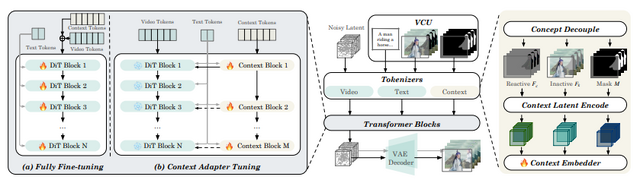
技術的には「Video Condition Unit」(VCU)と呼ばれる統一的な仕組みを採用し、テキスト、画像、ビデオ、マスクなど異なる種類の入力を効率的に処理します。これにより、さらに複雑な編集も可能になります。
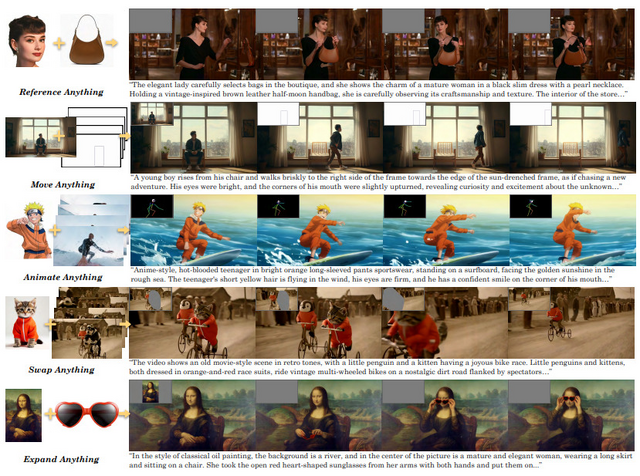
例えば、馬に乗っている人物部分をマスクで指定し、別の画像のキャラクターを参照として与えることで、元の動きを保ちながらキャラクターだけを入れ替えた動画を生成できます。他にも静止画の人物に対してモーション情報(ボーン動画など)を与えることで、その人物が動く映像を生成できます。
研究チームは評価データセット「VACE-Benchmark」を構築し、12の異なるタスクでVACEの性能を評価しました。その結果、VACEは個別のタスク専用モデルと同等以上の性能を示しました。
VACEは現在、「LTX-Video」と「Wan-T2V」という2つのモデルをベースに実装されており、それぞれ異なる特性を持っています。LTX-Videoベースのバージョンは高速処理が可能で一般ユーザー向け、一方Wan-T2Vベースのバージョンはより高品質な映像生成が可能ですが、より多くの計算資源を必要とします。

VACE: All-in-One Video Creation and Editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, Yu Liu
Project | Paper | GitHub
自然な音声合成を実現する高度なテキスト読み上げシステム「Spark-TTS」、声の高さや話す速度も調整可能
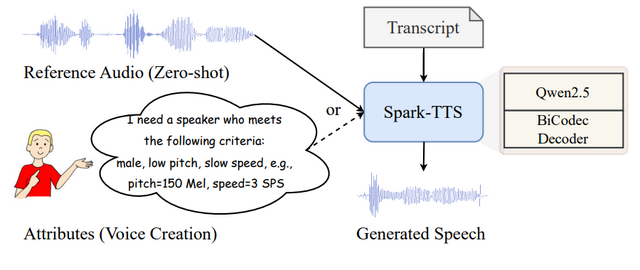
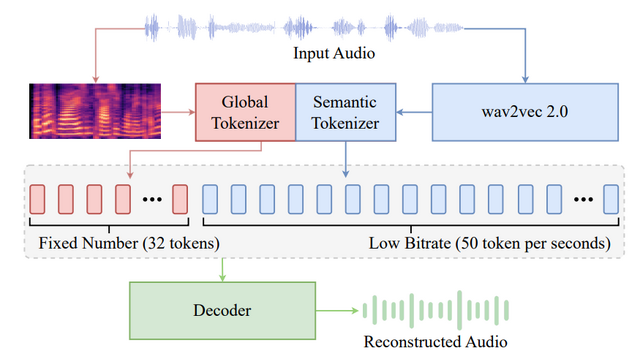
「Spark-TTS」は、大規模言語モデルを使った新しい音声合成技術です。この技術は、テキストから自然な音声を生成する能力を大きく向上させています。
Spark-TTSは大規模言語モデル「Qwen2.5」を基盤に、Chain-of-Thought(CoT)を組み合わせています。また「BiCodec」という仕組みにより音声を「言語内容」と「話者特性」という2つの要素に分解して処理することができます。
従来の技術と比べて特徴的なのは、細かい音声調整が可能な点です。Spark-TTSでは、性別、ピッチ、話速などの粗い制御だけでなく、具体的なピッチ値や話す速度などの微細な調整も行えます。これにより、ユーザーの要求に合わせた高度なカスタマイズが実現します。
研究チームは「VoxBox」という大規模な音声データセットも作成しました。このデータセットは10万時間以上の音声データを含み、性別やピッチ、話速などの詳細な属性情報が付与されています。
実験結果によると、Spark-TTSは最先端のゼロショット音声合成性能を達成し、参照音声に基づく合成だけでなく、高度にカスタマイズ可能な音声生成も実現しています。

Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, Weizhen Bian, Zhen Ye, Sitong Cheng, Ruibin Yuan, Zhixian Zhao, Xinfa Zhu, Jiahao Pan, Liumeng Xue, Pengcheng Zhu, Yunlin Chen, Zhifei Li, Xie Chen, Lei Xie, Yike Guo, Wei Xue
Paper | GitHub