









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第12回目は、好きな声でオーディオブック作成するAI、Stable Diffusionの40倍高速な画像生成AIなど5つの論文をまとめました。
生成AI論文ピックアップ
テキスト、画像、動画、オーディオのいずれでも入出力できるマルチモーダル生成AI「NExT-GPT」
最近、マルチモーダル大規模言語モデル(MM-LLM)が驚くべき進歩を遂げていますが、多くは入力側だけでのマルチモーダル理解に限定されており、複数のモードでコンテンツを生成する能力がありません。
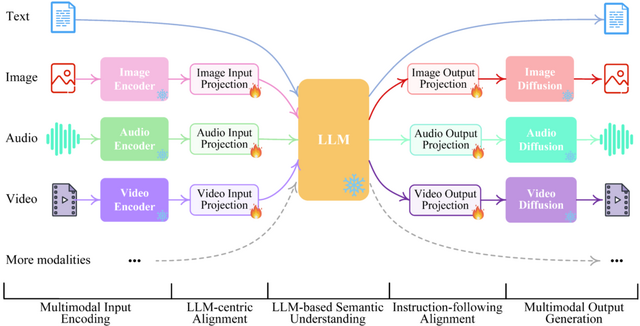
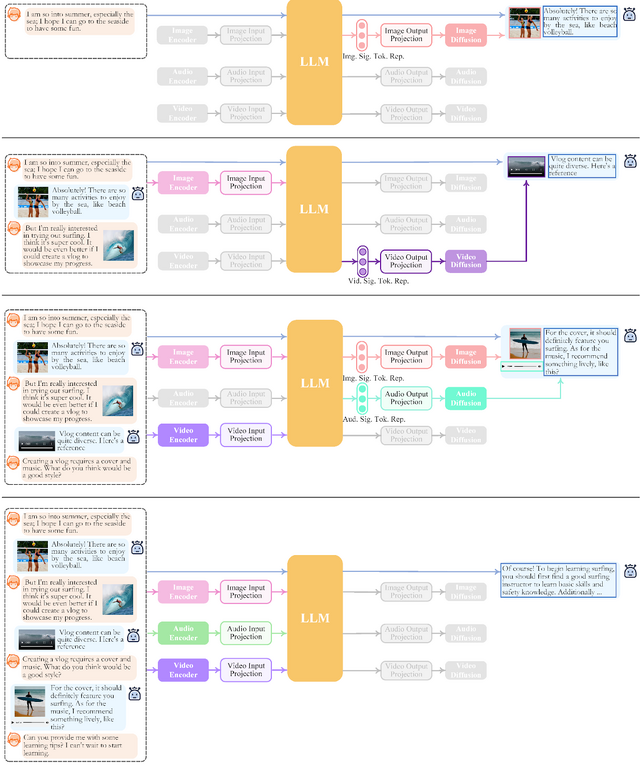
この研究では、汎用的なany-to-any MM-LLMシステム「NExT-GPT」を提案します。これはテキスト、画像、ビデオ、オーディオの任意の組み合わせで入力を受け取り、同じ4つのモダリティで出力を生成する能力を持つシステムです。
この技術の中心部分は、3つのステップで構成されています。どんなデータタイプでも言語モデルが理解しやすい形式に変換するエンコード部分。言語モデルがこの入力を理解し、どのタイプのデータとして出力するかの指示を生成する中間ステップ。その指示に基づいて、必要なデータタイプの出力を作成するデコード部分です。
このシステムをゼロからトレーニングするのは非常にコストがかかるため、既存の高性能なエンコーダーやデコーダー(例:Q-Former、ImageBindなど)の事前学習済みのパラメータを利用しています。
さらに、複数のデータタイプ間でうまく切り替えるための指示チューニング「Mosit」も導入しています。これにより、NExT-GPTはさまざまなデータタイプを柔軟に組み合わせて使うことができます。
NExT-GPT: Any-to-Any Multimodal LLM
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, Tat-Seng Chua
Project Page | Paper | GitHub
電子書籍を“好きな人の声”のオーディオブックに変換するシステム マイクロソフトなど開発
人の声で一つ一つ録音する従来のオーディオブック作成方法は、時間とコストがかかります。自動的に声を生成する技術も存在しますが、これまでのものは機械的な声が多く、また読み上げる部分を自動選定するのが困難でした。
このような課題を解決するためのシステムとして、マイクロソフトとMITが共同で、オンラインの電子書籍から高品質なオーディオブックを生成するモデルを提案しています。このモデルは以下の特徴を持っています。
まず、テキストを機械的な声ではなく、人間のような音声に変換する能力で、感情や強調を込めて文章を読み上げることを可能にします。
次に、本の中身から読み上げるべきテキストと読むべきでない部分(例: 目次、ページ番号、図表、脚注など)を自動で識別します。これにより、余計な情報を除外し、本文だけをオーディオブックとして提供することが可能です。
また大量のオーディオブックを短時間で効率的に生成するシステムであり、オンラインの電子書籍コレクションから迅速かつ効果的に高品質なオーディオブックを作成できます。Project Gutenbergが提供する電子書籍を元に、オープンソースとして、約3万5000時間の音声を持つ5000冊以上のオーディオブックを提供しています。Apple、Goolge、Spotifyのポッドキャストでも聞くことができます。
さらに、このシステムはユーザーが短いサンプル音声を提供することで、そのユーザーの声を模倣したカスタムオーディオブックを生成する機能も搭載しています。

Large-Scale Automatic Audiobook Creation
Brendan Walsh, Mark Hamilton, Greg Newby, Xi Wang, Serena Ruan, Sheng Zhao, Lei He, Shaofei Zhang, Eric Dettinger, William T. Freeman, Markus Weimer
Project Page | Paper | GitHub
自律型AIエージェントを改造するためのオープンソースプラットフォーム「Agents」
自然言語で目標を指示すると、その目標をサブタスクに分割し、自ら考え、行動する「自律型AIエージェント」をベースにしたモデルが多数登場しています。ユーザーは文章で目標を与えるだけで、後はAIが自動で処理してくれるのが特徴です。このようなアプローチは、AIの新たな方向性として注目されています。
しかし、技術者ではない、または専門的な知識を持たない人が自律型AIエージェントのカスタマイズや調整を試みるのは非常に困難です。
この問題を解決するため、「Agents」という新しいオープンソースフレームワークが開発されました。Agentsは、大規模言語モデル(LLM)を活用して、非技術者でも自律的な言語エージェントのカスタマイズ、テスト、調整、デプロイを容易に行えるように設計されています。
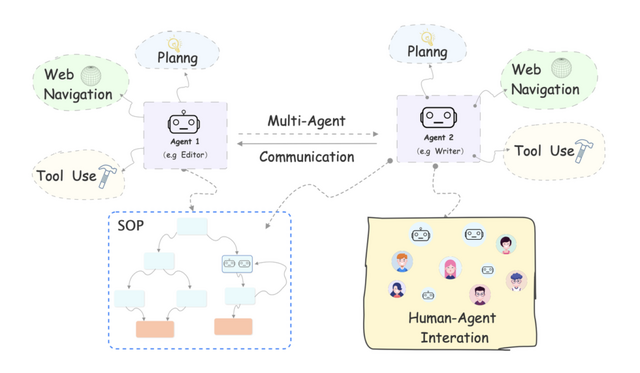
主要な機能としては、長期・短期の記憶(情報の維持・参照能力)、外部ツールの利用やWebナビゲーション(情報の検索・収集能力)、複数エージェント間の通信、人とエージェントの対話、エージェントの動作を詳細に制御するための機能などが含まれています。これらの機能はモジュール化されており、コーディングせずに簡単にカスタマイズが行えます。

Agents: An Open-source Framework for Autonomous Language Agents
Wangchunshu Zhou, Yuchen Eleanor Jiang, Long Li, Jialong Wu, Tiannan Wang, Shi Qiu, Jintian Zhang, Jing Chen, Ruipu Wu, Shuai Wang, Shiding Zhu, Jiyu Chen, Wentao Zhang, Ningyu Zhang, Huajun Chen, Peng Cui, Mrinmaya Sachan
Project Page | Paper | GitHub
写真内の被写体を“軽く引っ張る”と揺れ動くモデル Googleらが開発
この技術は、1枚の写真を元に、被写体が揺れているような動画を作成するシステムを提案しています。
例えば、静止している木の写真を元に、風に吹かれて揺れる木のアニメーションを再現することができます。また、ユーザーが画像内の被写体をドラッグ&ドロップすることで、その方向に揺れ動くインタラクションも実現しています。
このモデルは、多くの動画から自然界のさまざまな動き、例えば風で揺れる木の葉や花の動きを学習し、学習した動きを「Neural stochastic motion texture」という技術でモデル化します。これは、写真内の各ピクセルの将来の動きを予測するための技術です。
さらに、「フーリエ級数」という方法を使用して、予測された動きを数学的に表現します。フーリエ級数は、周期的な動き(例: 風による揺れ)を効果的に表現するのに適しています。最終的に、予測した動きを基にし、拡散モデルを用いて動画の各フレームを生成します。
このシステムを使えば、1枚の写真から被写体がさまざまな速度や方向で動く動画を作成することができます。物体の動きの速さや方向などをカスタマイズすることもでき、さらにはユーザーの軽く引っ張る操作に応じて被写体が反応するインタラクティブな映像も作成可能としています。


Generative Image Dynamics
Zhengqi Li, Richard Tucker, Noah Snavely, Aleksander Holynski
Project Page | Paper
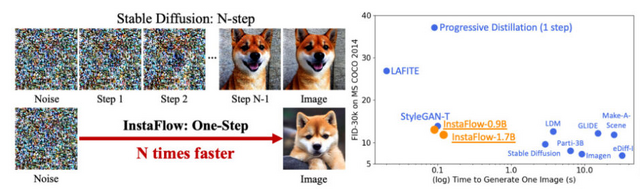
Stable Diffusionより40倍以上高速にテキストから画像を生成できるAI「InstaFlow」
近年、テキストを基にした画像生成技術が注目されています。拡散モデルはその代表的な技術の一つで、高品質な画像生成が可能である一方、コンピュータリソースの消費量が大きく、一つの画像を生成するのに時間がかかるという課題が存在しています。Stable Diffusionモデルは高品質な画像生成のために20ステップ以上のサンプリングを必要としています。
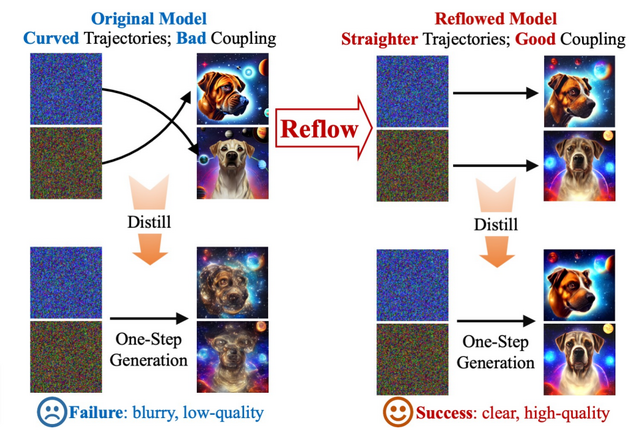
この課題を克服するために「InstaFlow」が提案されました。InstaFlowはStable Diffusionをベースとした新しいモデルで、最新の技術である「Rectified Flow」を採用しています。Rectified Flowの中核的なプロセスである「Reflow」は、画像生成の際の「ノイズから画像への変換過程」を最適化する役割を果たしています。
通常、画像を生成する際、ノイズやデータの変遷が複雑であり、これが高速化の障壁となっていました。しかし、Reflowはこの変遷を効率化し、ノイズと画像の関連性を強化することで、迅速に高品質な画像を生成することを実現します。
具体的な実験データによれば、MS COCO 2017のデータセットを使用した評価では、Stable Diffusionより40倍以上高速の、わずか0.09秒という短時間で高品質な画像を生成することができました。これは、従来のモデルと比較して格段の速さです。

InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, Qiang Liu
Paper | GitHub










