

OpenAIが「Realtime API」のパブリックベータ版を発表しました。これにより、有料ユーザーがChatGPTの高度な音声モードと同様の、自然な音声対音声の会話をアプリケーションに実装できるようになります。また、OpenAIは文字起こしAIで知られているWhisperの最新バージョン「Whisper V3 Turbo」を公開しました。
Googleは、大規模言語モデル「Gemma 2 2B」の日本語版を公開しました。日本語で微調整したGemma 2 2Bは、自社評価において、 GPT-3.5 を上回るパフォーマンスを発揮したといいます。またGoogleは、従来のモデルよりさらに高速で小さい低価格モデル「Gemini 1.5 Flash-8B」を発表しました。
BlackForestLabsが新たな画像生成モデルFLUX1.1 [pro]と、BFL APIのベータ版の一般公開を発表しました。FLUX1.1 [pro]は、前モデルのFLUX.1 [pro]と比べて6倍高速な画像生成を実現し、画質や指示への忠実性、多様性も向上しています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第66回)では、日本語専用LLMベンチマーク「JMMMU」や、Appleの画像深度推定モデル「Depth Pro」を取り上げます。また、Metaが開発した動画生成AI「MovieGen」や、テキストや画像1枚から3Dコンテンツを生成する「Flex3D」をご紹介します。
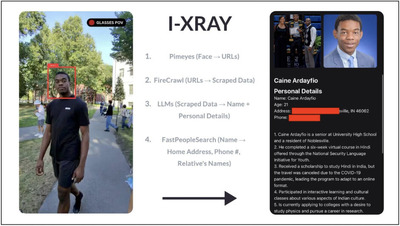
そして、生成AIウィークリーの中でも特に興味深い技術や研究にスポットライトを当てる「生成AIクローズアップ」では、スマートグラスに映る他人の顔から名前や住所などの個人情報をリアルタイムで特定する技術を単体で掘り下げます。
日本語LLMを真に評価できる日本語専用LLMベンチマーク「JMMMU」を東大などが開発。GPT-4oでも58%の性能
東京大学とカーネギーメロン大学に所属する研究者らは、日本語に特化した新しいマルチモーダルベンチマーク「JMMMU」を開発しました。これは、LLMの日本語でのマルチモーダル性能を真に評価することができるベンチマークです。
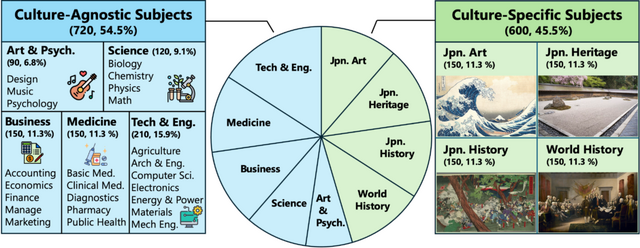
JMMMUの開発にあたり、研究チームはまず既存のMMMUベンチマークを慎重に分析し、その文化依存性を検討しました。文化に依存しない科目については、各分野の専門家である日本語ネイティブスピーカーを採用し、テキストと画像(グラフのタイトルなど)の両方を日本語に翻訳しました。
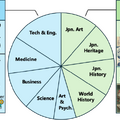
さらに、文化依存性の高い科目については、日本文化に適した新しい科目に置き換えました。これには、日本美術、日本の遺産、日本史、世界史(日本の教科書に基づいた内容)が含まれます。
その結果、JMMMUは720問の翻訳ベース(文化非依存)の問題と600問の全く新しい(文化依存)問題で構成され、合計1320問となりました。これにより、既存の文化を考慮した日本語ベンチマークのサイズを10倍以上に更新しています。
JMMMUのリーダーボードでは、オープンソースモデルとクローズドソースモデルの性能が比較されています。現在のところ、オープンソースモデルの最高性能は40.3%(LLaVA-OneVision 7B)、クローズドソースモデルは58.0%(GPT-4o 2024-05-13)となっており、大きな改善の余地があることが示されています。
A Japanese Massive Multi-discipline Multimodal Understanding Benchmark
Shota Onohara, Atsuyuki Miyai, Yuki Imajuku, Kazuki Egashira, Jeonghun Baek, Xiang Yue, Graham Neubig, Kiyoharu Aizawa
Project | GitHub
Appleが画像の奥行きを0.3秒、225万画素で推定するAI画像深度モデル「Depth Pro」を発表
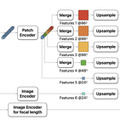
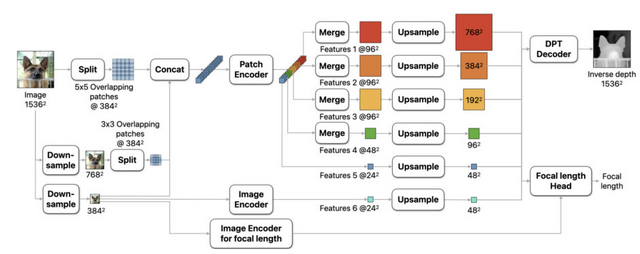
Appleは、新しいゼロショット単眼深度推定モデル「Depth Pro」を発表しました。このモデルは、単一の2D画像から高解像度の深度マップを生成することができ、従来のモデルと比較して精度、解像度、処理速度の面で大きな進歩を遂げています。
Depth Proの主な特徴は、225万画素の深度マップを0.3秒という短時間で生成できることです。これは、標準的なGPUを使用した場合の処理時間です。
まず、画像を理解するための新しい方法として、マルチスケールビジョントランスフォーマー(ViT)という技術を使っています。この技術は、画像全体の大まかな情報と細かい部分の情報を同時に処理できます。
次に、モデルの学習方法を工夫しました。実際の写真と、コンピュータで作った合成画像の両方を使って学習させています。実際の写真からは現実世界の複雑さを学び、合成画像からは正確な情報を学びます。
Depth Proの性能は、複数のデータセットを用いた広範な実験によって評価されました。その結果、このモデルは従来の手法を複数の側面で上回る性能を示しました。特に、物体の境界や細かい構造の再現性において顕著な改善が見られました。


Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun
Paper | GitHub
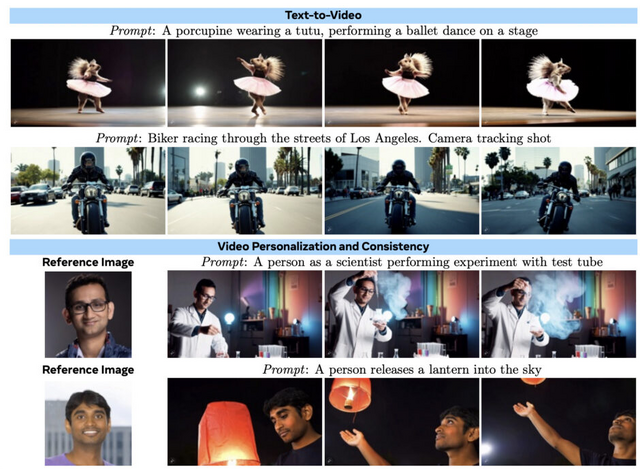
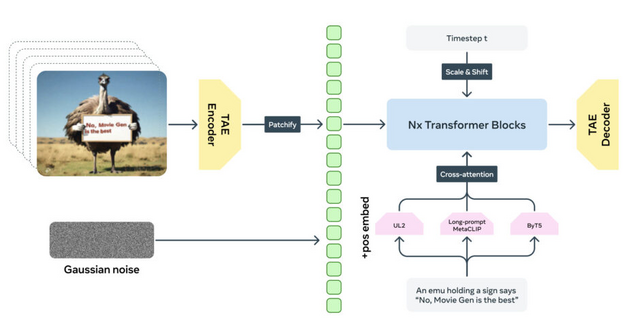
Metaが動画生成AI「MovieGen」発表。テキストから16秒程度の音声付き動画を生成
「MovieGen」は、Metaが開発した高品質な動画生成AIモデル群です。MovieGenは、テキストから動画の生成、動画の編集、キャラクターのパーソナライズ、テキストや動画から音声や音楽を生成したりと、様々な機能を持っています。
この幅広い機能は、2つの基盤モデルによって実現されています。
1つ目は30Bパラメータを持つMovieGen Videoで、テキストから画像とビデオを生成する統合モデルです。このモデルは、1秒あたり16フレーム、最大16秒間の高品質HDビデオをテキストプロンプトに従って生成します。
約1億本の動画と約10億枚の画像で事前学習されており、物体の動き、被写体と物体の相互作用、幾何学、カメラの動き、物理法則などについて理解しています。さらに、厳選された高品質の動画とテキストキャプションを用いて教師あり微調整を行い、生成品質を向上させています。
2つ目は13Bパラメータを持つMovieGen Audioで、ビデオとテキストから音声を生成するモデルです。48kHzの高品質な映画風効果音や音楽を、入力ビデオと同期させながら生成できます。
約100万時間の音声データで事前学習されており、視覚世界と音声世界の物理的および心理的な関連性を学習しています。このモデルは、動画の環境音や、視覚的な動きに同期した効果音、さらには場面の雰囲気や動きに合わせた音楽も生成できます。
MovieGen Videoモデルには、事後学習手順によってパーソナライゼーションと精密な編集機能が追加されています。パーソナライゼーション機能では、テキストと人物の画像を入力として、その人物が登場する動画を生成できます。編集機能では、テキスト指示を使って実際の動画や生成された動画に対して正確な編集を行うことができます。


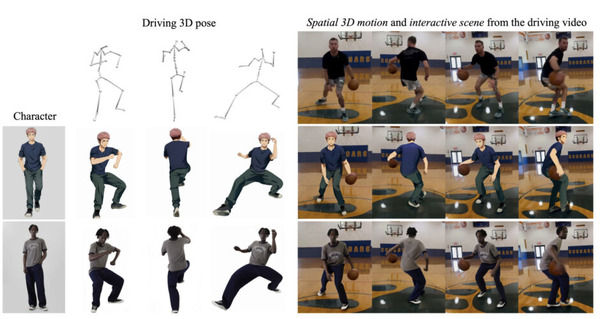
テキストや画像1枚から3Dモデルを生成するAI「Flex3D」をMetaが開発
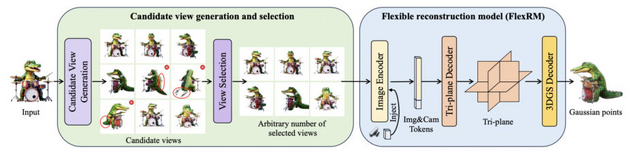
「Flex3D」は、テキストプロンプトや画像1枚から高品質の3Dコンテンツを生成します。候補となる多数の2D画像を生成し、その中から3D再構築に最適なものを選び出すという独自のアプローチを採用しています。これにより、3D再構築の精度を大幅に向上させることに成功しています。
Flex3Dの中核を成すのが「FlexRM」(Flexible Reconstruction Model)と呼ばれる柔軟な再構築モデルです。FlexRMは、入力される画像の数や視点が変化しても対応できるよう設計されており、効率的に高品質な3D再構築を行うことができます。
具体的には、FlexRMはトランスフォーマーアーキテクチャを基盤とし、3次元空間を表現するための「Triplane」表現を使用しています。この表現は、その後3D Gaussianパラメータにデコードされ、詳細な3Dオブジェクトを高速に生成することが可能となりました。
研究チームは、Flex3Dの性能をベンチマークで評価した結果、Flex3Dは最先端の手法を大きく上回る性能を示しました。



Flex3D: Feed-Forward 3D Generation With Flexible Reconstruction Model And Input View Curation
Junlin Han, Jianyuan Wang, Andrea Vedaldi, Philip Torr, Filippos Kokkinos
Project | Paper