
いよいよ出荷が始まる手のひらAIデバイス「Humane Ai Pin」のやっておくことリスト
出荷間近となったAIデバイス「Ai Pin」。日本ではソフトバンクが取り扱うことが発表され、注目を浴びています。いち早く米国で購入した著者が、購入前の各種手続きについて解説します。


生成AIグラビアをグラビアカメラマンが作るとどうなる?第21回:ComfyUI応用編。ControlNetでポーズ・構図を指定する (西川和久)
ComfyUIでControlNet(Canny/Depth/OpenPose)を使うには


新連載「AIだけで作った曲を音楽配信する」。生成AIが作り上げた架空バンド「The Midnight Odyssey」を世界デビューさせる、その裏側
大規模言語モデル(LLM)でコンセプトを考えて、AI作曲サービスでボーカル入り楽曲を作り出す。そんなやり方で制作したコンセプトアルバムを音楽配信に載せるという話を、自ら音楽レーベルを主宰し、テクノロジー関連の執筆もこなしている山崎潤一郎さんに、数回にわたって執筆いただきます。


Adobeの生成AI技術を先取り公開 Adobe Summit 2024「Sneaks」のマーケティングツールを一挙解説(西田宗千佳)
Adobeは春と秋に大きなイベントを開催する。秋は「Adobe MAX」。Adobeと言われて多くの人が思い出す、Photoshopなどのクリエイティブ・ツールのイベントだ。では春は? それが「Adobe Summit」。同社のもう1つの柱である、デジタルマーケティング関係のイベントだ。今年も同社の協力で、米・ラスベガスに取材に来ている。


AIは人類が体験したことのない新しい音楽ジャンルを作れるか? Claude 3 OpusとSuno V3に問うた結果(CloseBox)
既存のカテゴリーの曲を巧みに作り上げるSuno V3。では、これまでにないような音楽をAIは作ることができるのでしょうか?


生成AIで3D化して整形。ローカルでも超高速で3Dデータ生成できる「TripoSR」を試す
Stablity AIが、独自の3D生成サービスを提供してきたTripo AIと共同開発した「TripoSR」を紹介します。

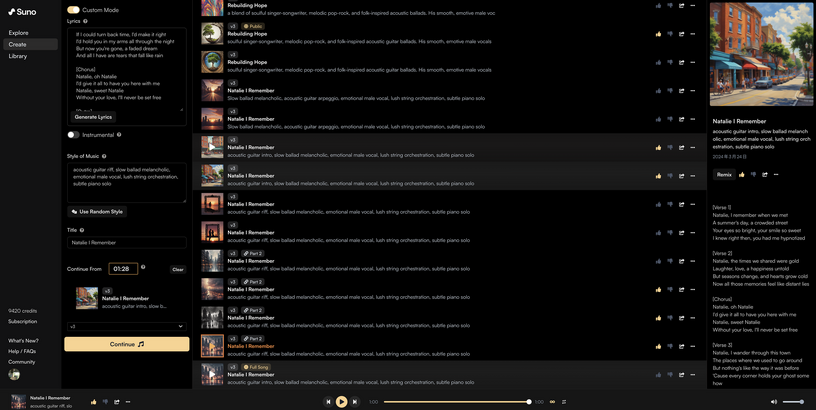
Suno AIに好みの曲を作らせて自分で歌う、オリジナル曲AIロンダリングで名曲を生み出すワークフロー(CloseBox)
Suno V3を使って好みの曲を作っていくためのワークフローを確立した感じがするので、その一例をお見せしようと思います。

動画生成AI「Sora」のオープンソース版「Open-Sora 1.0」公開、AI同士を掛け合わせて高品質なAIを自律的に生み出す手法など重要論文5本を解説(生成AIウィークリー)
先週発表された生成AI分野で重要な論文の中から5本を解説します。動画生成AI「Sora」のオープンソース版「Open-Sora 1.0」、AI同士を掛け合わせて高品質なAIを自律的に生み出す手法など。


生成AIグラビアをグラビアカメラマンが作るとどうなる?第20回:MシリーズMacでもComfyUI+フロントUIが動く!ComflowySpaceの使い方(西川和久)
ComfyUI使ってみたいけど…。
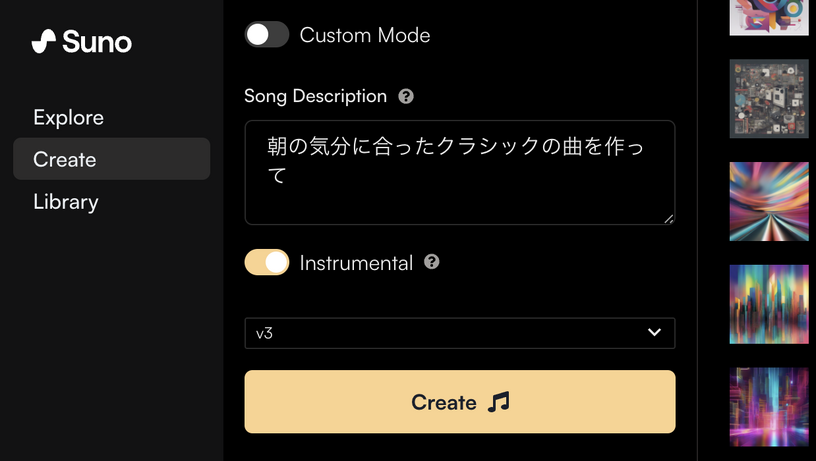
AI作曲サービス「Suno」、無料ユーザーにも高品質版V3を開放。1日20曲、1曲2分が生成可能(CloseBox)
Suno V3が正式に公開されました。
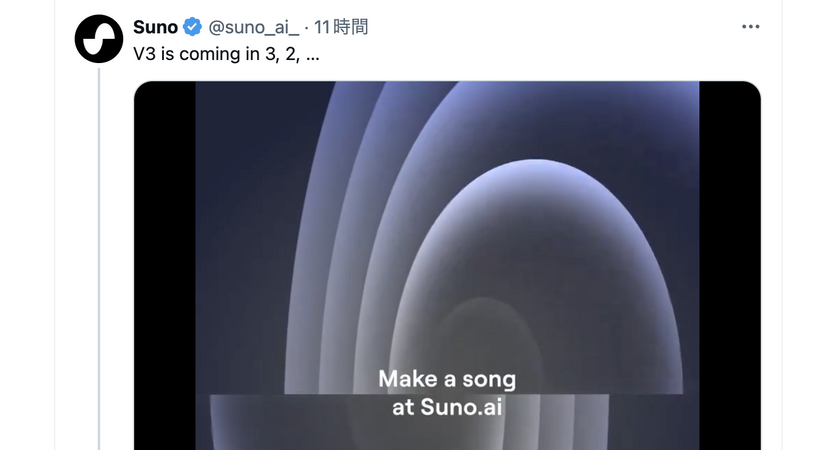
リアルな歌唱もインストも作曲できる生成AI「Suno」高性能な最新版V3が3月23日から無料?→22日公開されました。最新の使い方を解説(CloseBox)
3月23日に公開予定のSuno V3。すでにAlpha版でたっぷり遊んでいる自分としては、一般公開時に皆さんがスタートダッシュできるように、改めて使い方をまとめておこうと思います。

期待の3D生成AI「Stable Video 3D」(SV3D)発表。動画から3Dモデル生成、現状できることと今後の展望
Stable Diffusionを提供するStability AIは、高品質なマルチビュー推定と3Dメッシュの生成を行う新たなモデル「Stable Video 3D」(SV3D)を発表しました。ただし現時点で公開されているのは、画像から多角度の姿を推定するマルチビュー推定部分のみです。現状ではまだその全貌がよく知られていないので、ローカルで試せるようになる前に、その概要と技術的な構成についてまとめました。
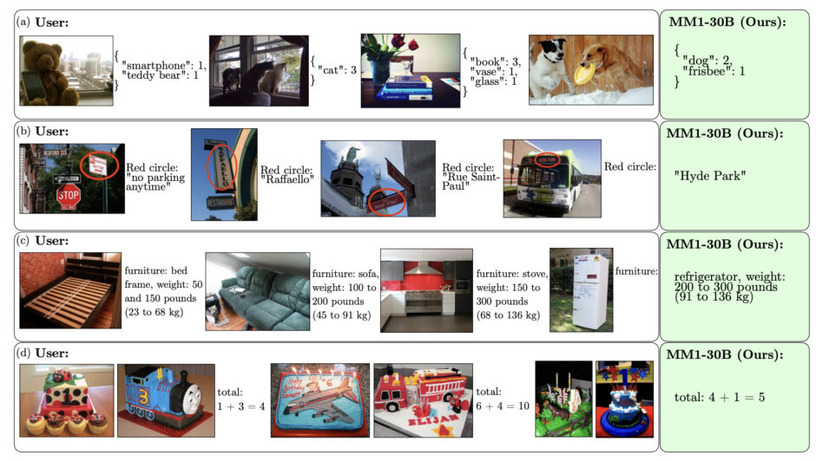
「公開するApple vs. 隠すOpenAI」アップルが300億パラメータのマルチモーダルAI「MM1」発表。重要論文5本を解説(生成AIウィークリー)
Appleは、高性能なMLLMを探るべく、モデルの構造や学習に使うデータの選び方がモデルの性能にどのように影響するかなどを詳しく分析した論文を公開しました。

「生成AIグラビア実践ワークショップ」過去回アーカイブの販売を開始しました
人気連載「生成AIグラビアをグラビアカメラマンが作るとどうなる?」の著者である西川和久さんを講師に迎えたオンラインワークショップ「生成AIグラビア実践ワークショップ」過去回アーカイブの販売を開始しました。


Midjourney、生成した人物の特徴を維持する「Character Reference」機能を追加
画像生成AIサービスMidjourneyは、複数の生成画像で一貫性を持った人物画像の生成に対応する「Character Reference」機能のテストを開始しました。


ゲーム内の「村人のセリフ」をChatGPTで大量生成する方法(第2回)。データを大量に出力する
生成AIをゲーム開発の現場で活用している筆者が、ゲーム内テキストの作成、中でもいわゆるRPGの村人たちのセリフの生成を一から行う流れを解説します。第2回は、データを大量に作るところから改善すべき点まで。

4090でもLLMをゼロから事前学習できる手法「GaLore」、画面を見てトリプルAタイトルを完走できるAIなど重要論文5本を解説(生成AIウィークリー)
民生用GPUはNVIDIA RTX 4090の24GBメモリが最大ですが、これでLLMのファインチューニングは困難とされています。それを可能にするという技術が発表されました。

「GPTs」で自分向け推敲支援機能を作ってみる(西田宗千佳)
ChatGPTの機能を使い、「自分向けの推敲支援機能」を作ってみた。

「春はあけぼの、YOYO白くなりゆく」をSuno AI作曲でラップにしてみた。清少納言が現代に生きていたら枕草子をどう歌っただろう(CloseBox)
NHK大河ドラマ「光る君に」を楽しんで視聴しています。紫式部と清少納言が初めて出会ったときのバチバチ感はスリリングでした。

ゲーム内の「村人のセリフ」をChatGPTで大量生成する方法(第1回)。RPG村人が住む世界を作るまで
ChatGPTがこれほど広く雑多な目的に適用できるのは未だ驚きです。このままいわゆるAGIに到達する道にあるのか、規制や資源の問題はどうなるのか、未来への関心は尽きませんが目の前の実用も重要です。

複数画像レイヤー同時生成できるAI「LayerDiffuse」、MML対応音楽生成AI「ChatMusician」、高性能なリップシンクAI「EMO」など重要論文5本を解説(生成AIウィークリー)
今週も、生成AIの重要論文5本を解説します。透明含む複数レイヤーを同時に画像生成できるAI「LayerDiffuse」、音楽を文字のように扱う音楽生成AI「ChatMusician」など。

多視点3Dディスプレイ「Looking Glass Go」用に写真を立体化、AIによる単眼深度推定の方法と課題を解説
裸眼立体視ディスプレイをコンパクトにしたLooking Glass Goがついにユーザーの元に届きます。それに備えて、単眼深度推定を行うための方法をまとめました。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第19回:ComfyUIで最新のStable Cascadeを試す+アナログ風の後処理ProPost (西川和久)
前回標準のWorkflowにLoRAを追加してみたが、今回は画像が出来た後、つまり後処理用のNodeを追加してみたい。
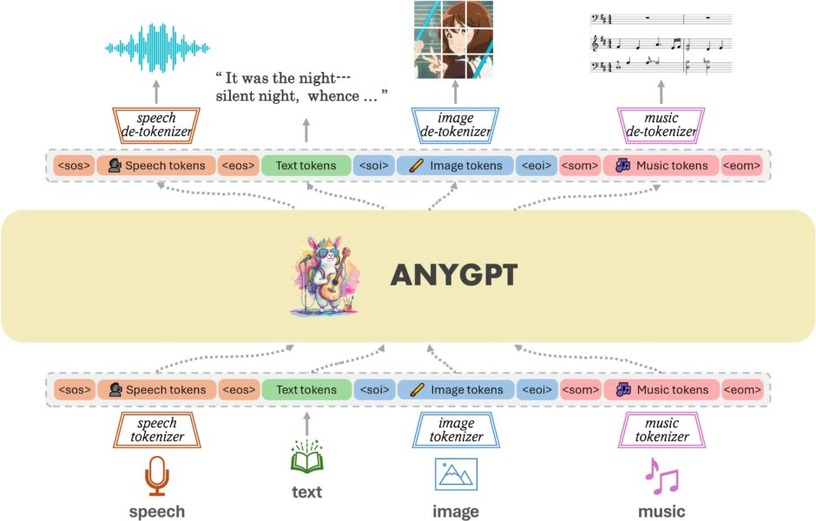
音楽含むマルチモーダルAIモデル「AnyGPT」、AIの“パラメータ”を生成するAI「P-diff」など重要論文5本を解説(生成AIウィークリー)
今週の生成AIウィークリーは、AIの“パラメータ”を生成するAI「P-diff」、過去最高精度のリアルタイム物体検出器「YOLOv9」など重要論文5本を解説します。

GoogleのGemini AI、多様性に配慮して「黒人ナチスドイツ兵士」や「米国建国を率いた黒人政治家」画像を生成してしまう。改善に取り組むと声明
Googleの生成AIであるGeminiが、多様性に配慮するあまり「1943年のドイツ軍兵士の画像を作って」に対してナチスドイツ風軍装の黒人男性やアジア人女性の画像を生成してしまい、Googleは歴史的に不正確だったと認める声明を発表するできごとがありました。


さよなら吟遊詩人。Bardから双子のGeminiにバトンタッチしたGoogleのAIはどう変わったのか(Google Tales)
GoogleのAIはBardからGeminiに変わりました。名前以外にどこが変わったのかをまとめてみました。

1時間超のYouTubeを解釈できるオープンなマルチモーダルAI「LWM」、Windowsをプロンプトで自動操作するMS製AI「UFO」など重要論文5本を解説(生成AIウィークリー)
1週間分の生成AI関連論文の中から重要なものをピックアップする連載。今回は、Gemini 1.5、LoRA改良版、WindowsのAIエージェント、長時間動画にも対応するマルチモーダルAIなど5本を紹介します。

AI生成の巨大ペニスを生やしたネズミ画像、査読付き科学誌の論文に載ってしまい科学界困惑。学術的にもデタラメ
査読付きのオープンアクセス科学論文誌Frontiersは、掲載した論文に、意味不明な巨大なペニスを持つラットの挿絵を添付して掲載していたことで、科学者コミュニティをザワつかせています。


OpenAI、文章から驚異的品質の動画を生成するモデル「Sora」発表。試せる一般公開はまだ先、世界を描ける汎用の生成AIレンダラになり得るか
OpenAIから新しい動画生成モデル「Sora」が発表され、合わせて技術レポートも公開されました。Soraはテキストから最長1分の動画を生成できるモデルで、画像から動画の生成や動画の補完も可能。作例を見る限り、現在公開されているどの動画生成モデルよりも優れています。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第18回:バレンタイン編。ComfyUIの環境を整える (西川和久)
グラビアカメラマンでありソフトウェアエンジニアでもある西川和久氏による生成AI
グラビア実践講座 第18回をお届けします

複数の同一人物を同時に量産できるNVIDIAの画像生成AI「ConsiStory」、Gemini UltraやGPT-4に匹敵する数学特化のオープンソース言語モデル「DeepSeekMath」など重要論文5本を解説(生成AIウィークリー)
複数の同一人物を同時に量産できるNVIDIAの画像生成AI「ConsiStory」、Gemini UltraやGPT-4に匹敵する数学特化のオープンソース言語モデル「DeepSeekMath」などを解説します。

生成AIで大統領候補のフェイク画像作成、Midjourneyが禁止検討。トランプおよびバイデン両氏を含む
Midjourneyは今後1年間、同社の人工知能ソフトウェアを使って政治的な画像を作成すること、特にジョー・バイデン氏とドナルド・トランプ氏の画像生成を禁止することを検討しています。

アップル、文章で画像を編集するAIモデル「MGIE」開発。GitHubにオープンソース公開
アップルの研究者らが、入力した文章によって画像を編集できるAIモデル「MGIE」を発表、公開しました。MGIEとはMLLM-Guided Image Editingの略で、テキストベースのコマンドを解釈するマルチモーダル大規模言語モデル(MLLM)を使用しています。

スマホ高品質画像生成、わずか0.2秒で。Google「MobileDiffusion」がiPhone 15 Proで達成。重要論文5本を解説(生成AIウィークリー)
iPhone 15 Proで0.2秒以内に高品質な512×512画像を生成することにGoogleが成功。生成AIに関する最新論文5本を解説します。

生成AIおじさんをおじさん好きが作るとどうなる?(第1回) ありふれたモチーフ「おじさん」を生成するための手法
生成AIによりおじさんの画像を作り出すためのツールや生成のコツのようなものをご紹介します。

Googleの会話AI『Bard』、賢いGemini Proが日本語でも利用可能に。回答のダブルチェックも対応
GoogleのチャットAIサービスBardで、日本語でもGemini Proを利用可能になりました。


生成AIグラビアをグラビアカメラマンが作るとどうなる?第17回:新技術をすぐ試せるComfyUIのインストール・使いかた (西川和久)
Stable Diffusionで生成AI画像を作る時、もっとも一般的なインターフェースはAUTOMATIC1111だろう。デファクトスタンダードと言ってもいいほどで、検索すると、インストール方法や使い方など、それこそ山盛り出てくる。ところが最近、ComfyUIがちょっとした人気だ。

アーティストのAIへの反発をどう考える? 台北当代芸術館のAIアート展覧会「Hello Human!」で、キュレーターにAIアートの課題を聞きました(CloseBox)
台湾の台北当代芸術館(MoCA TAIPEI)で開催されているAIアート展覧会「你好,人類!Hello, Human!」にアーティストとして参加。この展示会のキュレータにAIとアートの関係について聞いてきました。

Amazonが服の仮想試着AI「Diffuse to Choose」、画像内の物体分離指示できる「Grounded SAM」、動画の高品質な奥行き推定「Depth Anything」など重要論文6本を解説(生成AIウィークリー)
今回の生成AI論文解説はいつもより1本多い、6本分です。中でもAmazonのバーチャル試着技術は実用性が高そうです。

伝説のコメディアンをAIで「復活」させたYouTube番組を遺族が提訴「不謹慎な人間が作った粗悪な模造品」
米国の伝説的スタンダップコメディアン、ジョージ・カーリンの声をAIで模倣して製作された1時間のYouTube番組に対し、カーリンの娘は「偉大な米国人アーティストの業績」を盗んだとして、遺産管理団体を通じて著作権侵害とパブリシティ権侵害の訴訟を起こしました。

GPT-4のコード生成精度を2倍以上向上させる「AlphaCodium」、写真1枚から本人性を維持した画像を量産できる「InstantID」など重要論文5本を解説(生成AIウィークリー)
PhotoMakerのライバルともいうべき技術やAppleのLLMなど、生成AI最新論文の概要5つを紹介します。

生成AIグラビアをグラビアカメラマンが作るとどうなる?第16回:指問題解決!?Hand Refiner (西川和久)
Hand Refinerは2023年12月1日に論文、その後、2024年1月初旬にAUTOMATIC1111のADetailerとComfyUIで使用可能になった手(指)に関する新手法だ。今回ご紹介するHand Refinerはかなりロジカル。具体的には、画像から手を認識、認識した位置での形や5本指などリファレンスになる手を深度情報で取得、その深度情報を使って手をInpaintする、ざっくりこの3段構えとなる。